
What’s a Size-of-Data Operation?
Database professionals say, “That’s slow because it’s a size-of-data operation.”
A size-of-data operation is when the database has to write all of the affected data again. What you’re asking for might seem small, but for the database, it causes a lot of work.
For example, let’s say you live in a strict household, and your parents have told us that under this roof, everyone’s hair can only be black, blond, brown, or red. (Don’t blame me. I don’t make the rules. They’re your parents, not mine. Go talk to them. And tell your mom I said hi.)
If your parents suddenly loosen up and say, “We’re now allowing you to dye your hair pink,” that doesn’t mean we have to touch everyone’s head. It’s a metadata operation: we’re just making a new note so that when someone walks into the door and we check their hair color, we have a new acceptable option.
However, if your parents freak out and say, “Everyone’s hair must be pink,” that means we’re gonna need to dye every person’s hair. We’re gonna have to gather everybody together and do some real work.
That’s a size of data operation: however many people live in the house, we’re gonna need to work on all of ’em.
How that translates into databases
I’ll use the Users table in a large Stack Overflow database to explain.
If I alter a table and add a new nullable column, it happens instantly, and SQL Server doesn’t have to touch any pages:
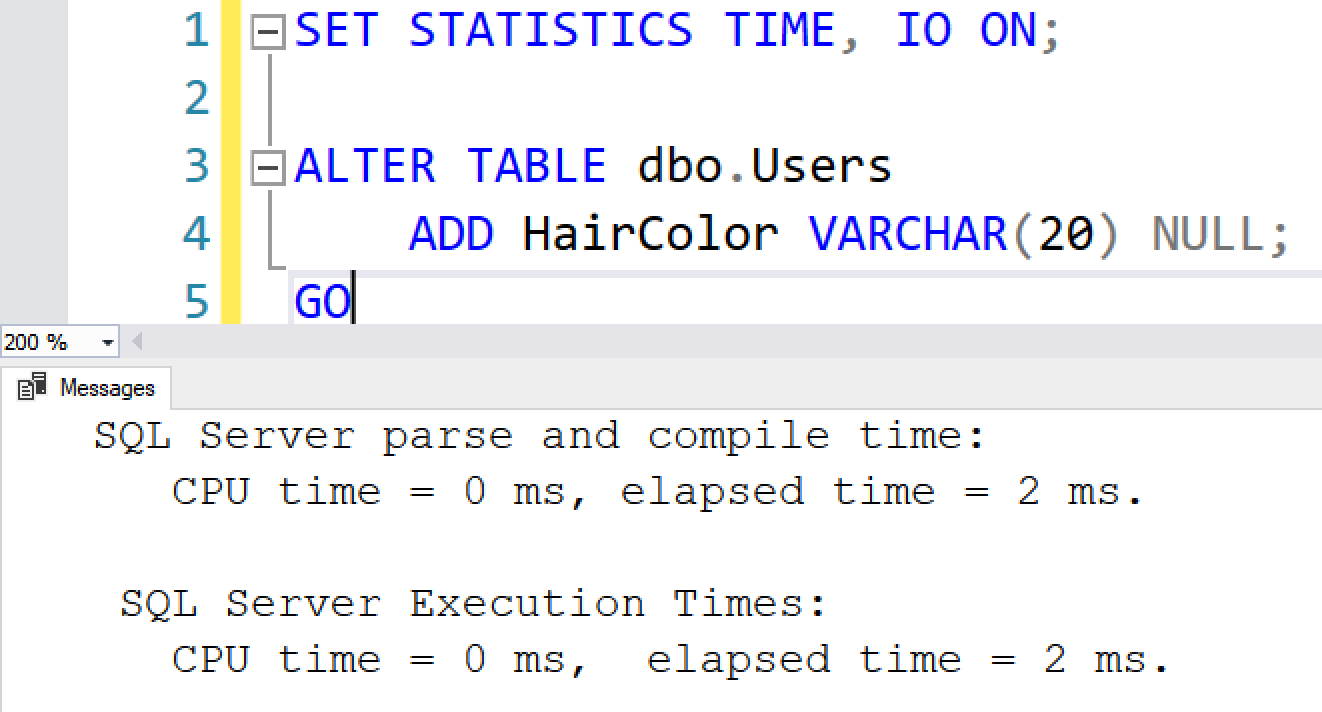
Adding a column like that is just a metadata change. It tells SQL Server, “When new rows walk into the house, they’re allowed to specify their HairColor now. When rows leave the house, if they don’t already have a HairColor set, just say it’s NULL.”
However, if I populate that column and dye everyone’s hair pink, that’s gonna take some time, because we’re gonna have to touch every row:

That’s a size-of-data operation, so it’s slower.
How that affects development & deployment
When you’re just getting started developing an app, and all your tables are empty, you don’t really have to worry about this kind of thing – because size-of-data operations are fast when there’s, uh, no data involved.
But the larger your data becomes, and the slower your storage becomes (like if you move from nice on-premises flash storage up to the cloud), then the more you have to pay attention to this. You’ll want to run your deployment scripts on a real production-sized database, not just an empty development shell, and time the deployment scripts. The longer an operation takes, the more likely it is a size-of-data operation. On larger databases – at 100GB and higher – and at 24/7 uptime shops like online stores, you’ll likely have to tune your deployment scripts to avoid size-of-data operations.
I haven’t seen a good rundown of all the operations that are size-of-data operations for Microsoft SQL Server, but it’s changed over the years. Hey, if you’ve got a blog – there’s a potential idea for you! Not me though. The hot tub is calling.

19 Comments. Leave new
Ohhh how worse it becomes.
There is a log of who’s hair was turned pink and what color it was beforehand in case of RollBack.
Everyone must go through the same room – tempdb.
Sometimes when hair is dyed there are split ends – page splits. More hair that one started with forward rows.
If there are page splits – then file may need to grow and that takes time.
Later – update statistics and rebuild index (all the hair is pink so everyone got a new value)
“What? Me worry?” My parents were from the 30’s – forget pink hair.
I think one of the key concepts that people are missing out on is that size (of data) matters always when making changes to the schema or the data in a database. Just like when your girlfriend says that she doesn’t want a valentines day present, or that size doesn’t matter, it’s a lie and a trap.
I think that’s a more concise and valuable concept to learn. Reason being that the situations when size don’t matter are fewer, and thus exceptions to the rule.
If we teach that everything requires I/O, and that bandwidth at every level in a system or network has a limit, then the world will be a better place. Memory, disks/storage, network in that order from fast/high bandwidth/low altency, to slow/low bandwidth/high latency. The general rule in computing is: small = fast, and large = slow.
In other words, database developers need to understand the fundamentals of computers, and then people won’t be surprised when an empty dev database is “fast”, and a huge prod database is “slow”, right?
Otherwise, just reboot the server. That will speed it up for sure, but your girlfriend will still be unhappy. ?
Jason, you are so right.
Takes longer to transfer 100 (whole table) meg than 10 meg (needed pages) or 800k (just the covering index)
Data compression helps. 64K cluster size does as well.
We hope to experiment with jumbo frame sizes for the network.
I think my girlfriend like Large and slow. Not sure. Works either way for me.
Jason – no, this part of what you said isn’t correct:
Reread the post, and I give one example where size doesn’t matter. There are others, and no, I’m not talking about your transaction log. 😉
@brent Yes, you are technically “correct” and I’m technically “wrong” because I used the word always on purpose to make my point. You caught me.
I read your example, and I’m aware of other examples. However, you’re missing the point I was making, probably because I was being sly and trying to be funny.
The point I was making is that even though there are a few known operations that require no I/O, it’s a much safer bet to teach people that *most of the time* changes will require I/O, and to teach them why.
The reason is that that a case like the example you gave is one of the few use cases in which adding a column to a table is a no I/O (metadata) operation.
Yes, I know that SQL Server 2012 Enterprise Edition has a way to add NOT NULL columns as a metadata operation, and yes I know that computed columns are metadata operations too, *unless* you specify PERSISTED, but I’m talking specifically about run of the mill columns that developers create 99% of the time.
If you take your example of adding a column and consider the other probable use cases of adding a column, then hopefully you can see the point I was making. There are at least five cases of adding a column that require I/O, and only one case that does not.
If you add a nullable column, supply a default constraint, and WITH VALUES then it requires I/O.
If you add a nullable column to a non-clustered index, then it requires I/O.
If you add a non-nullable column with a default constraint, then it requires I/O.
If you add a foreign key constraint on that column, then it requires I/O unless you include WITH NOCHECK.
If you add a check or unique constraint on that column, then it requires I/O unless you include WITH NOCHECK.
Of course, if the table in the example is empty, then all of these examples result in no I/O.
So, what’s a better lesson to teach a developer? Do you teach them the X number of cases of Size of Data operations when I/O is required?
Or, do you teach them that most of the time (effectively always) you’re going to incur I/O, except for a small handful of exceptions when no I/O is required?
I’m arguing for the later. Production databases will thank us later.
Now back to manually growing my transaction log… 😉
Jason – the point of the post is cleverly concealed in the title: “What’s a size-of-data operation?”
This post is about starting to understand which things are size-of-data operations, and which ones aren’t.
It sounds like you’re arguing that folks shouldn’t even bother to learn: they should just assume that everything is a size-of-data operation. I disagree, thus the post. I tend to argue for education here rather than ignorance. Hope that’s fair. 😉
Did you use the hot tub?
I imagine it was like those Japanese Macaque monkeys in the hot springs, challenging getting out.
Add a column to a big table? No problem.
Add a not null column to a big table, and fill it with the default value? It will take a while.
Silviu, well, I’ve got some good news and bad news.
The bad news is that you’re wrong, and you used your name in public. You never really wanna do that. Instead, say “My friend says it will take a while.” That way, when you’re wrong, well, nobody’s gonna know it was really you.
Now for the good news – the proof:
USE StackOverflow2013;
GO
SET STATISTICS TIME, IO ON;
GO
ALTER TABLE dbo.Posts
ADD NewHotness VARCHAR(50) NOT NULL
CONSTRAINT Posts_NewHotness
DEFAULT (‘Brand New’)
WITH VALUES
Results – and note that there were zero logical reads:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 26 ms.
Cheers!
Oh well. That’s not the first time I was wrong. (At least I wasn’t a teenager any more, when Facebook was invented.)
Anyway, I have another friend that uses to say “It depends”. And since I hurried to post here without testing first, I did just that, on a new machine with SQL2019 on it. Blinking fast, about 3ms on my table.
Then I tried the same thing on the old 2008R2 prod server (yet to be decommissioned), and got many logical reads and over ten seconds.
Thanks, Brent. Now I have to test this on the same hardware.
“wasn’t a teenager any more, when Facebook was invented” how lucky we are.
Keep asking questions.
@Brent Are you running Developer or Enterprise edition for this? A friend says you might be wrong, but he doesn’t have Standard Edition handy to verify.
https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-table-transact-sql?view=sql-server-ver15#adding-not-null-columns-as-an-online-operation
And why wouldn’t your friend have Standard Edition handy? (That’s part of the answer, heh.)
He works with SQL Server 2019 Developer Edition on his local PC and Azure SQL Database mostly, and he didn’t want to VPN into work. My friend is lazy.
I asked a friend with 2019 Standard Edition, and the logical reads are still there.
Learning is never ending!!!
(sigh) I hear you.
Neither is stupidity. At least I can get a certificate in learning.
In your defense, the fool resistant lab diagrams simplify things. There are no abandoned tables or weird names. Kronos database still has TKCS ( Time Keeper client Server) tables. Too much work.
As you grow you find this stuff mucking things up.
People used 32K varchar not knowing the performance impact.
People used int instead of tinyint because “I do not want the program to bomb”
People put varchar at the front of a row or tuple.
For what it is worth, the rabbit hole just kept getting deeper until it did not. Start with how many rows on a page and work up – not down.
Just had to say the pink hair dye is far and away the most entertaining SQL example I’ve ever read; made me laugh and taught me something too 🙂
Hahaha, thanks, glad you liked it!