A Single Database View Cost Me $50/Day for Months.
Our SQL Server monitoring product, SQL ConstantCare®, uses Amazon Aurora on the back end. I blogged about our choice of database back in 2018, and at the time, I said:
I know, I know. The Microsoft geek in you – and me – wants us to use SQL Server on the back end, but here’s the deal: SQL Server is not self-managing or cheap. (After all, you and I make very good livings keeping SQL Server up and running, right?) Whenever possible in this product, I wanted to use something inexpensive that somebody else managed for us.
Well, like anything else in the cloud, the costs creep up on you slowly over time.
 It took me a really long time to notice because most of our Amazon hosting costs are due to the lab VMs for our Mastering training classes. Students get pretty beefy VMs to run their labs, and I run a lot of training classes. I really should have had separate AWS accounts for each of our business uses – these days, the best practice is to isolate your environments across a lot of accounts. Instead, I was using tags in AWS to break things up by budget.
It took me a really long time to notice because most of our Amazon hosting costs are due to the lab VMs for our Mastering training classes. Students get pretty beefy VMs to run their labs, and I run a lot of training classes. I really should have had separate AWS accounts for each of our business uses – these days, the best practice is to isolate your environments across a lot of accounts. Instead, I was using tags in AWS to break things up by budget.
One day, it hit me out of nowhere as I was looking at Billing Explorer: the AWS Aurora RDS Postgres costs had gotten pretty expensive over time.
We were spending about $60/day, but we hadn’t upsized our instances. What was going on?
A peek into our bill revealed a nasty surprise:
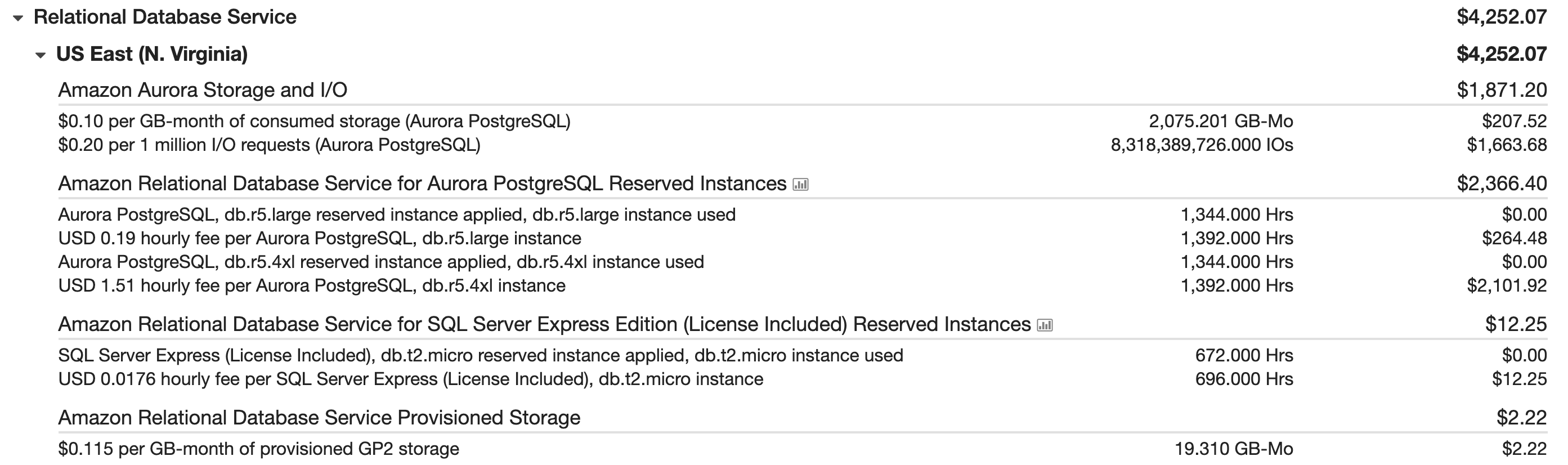
A few lines down, there’s a pretty doggone large number of IOs: we’d done 8.3 biiiiiiillion iops, ringing in at an extra $1,663.68 that month.
We jumped into AWS Performance Insights, a monitoring tool that’s included free with RDS. It gives you a really nice point-and-click GUI to analyze queries by CPU, reads, writes, and more. I expected to find a single ugly query, but lots of them were doing a lot of reads, and it took me an hour or two of digging to realize…
All of the read-intensive queries were calling the same view.
It wasn’t even a large view: it was just a view that fetched the prior collection number & date for a given client’s server. If we were analyzing your metrics, we needed to join to your prior collection so we could see what changed. The tables in the view had less than 100K rows – it was just that it was getting a pretty bad execution plan – well, bad relative to the size of the small query.
Each time we hit the view, we were incurring a few hundred milliseconds of time, which doesn’t sound like much – but we called that view a lot.
We debated tuning the view and its indexes, but Richie leapt into action and turned it into a table instead. After all, when we process a client’s data, we only need to fetch the prior collection ID & date once – it’s not like they’re adding additional past collections. Time only goes forward.
You can see the day when Richie implemented the table:
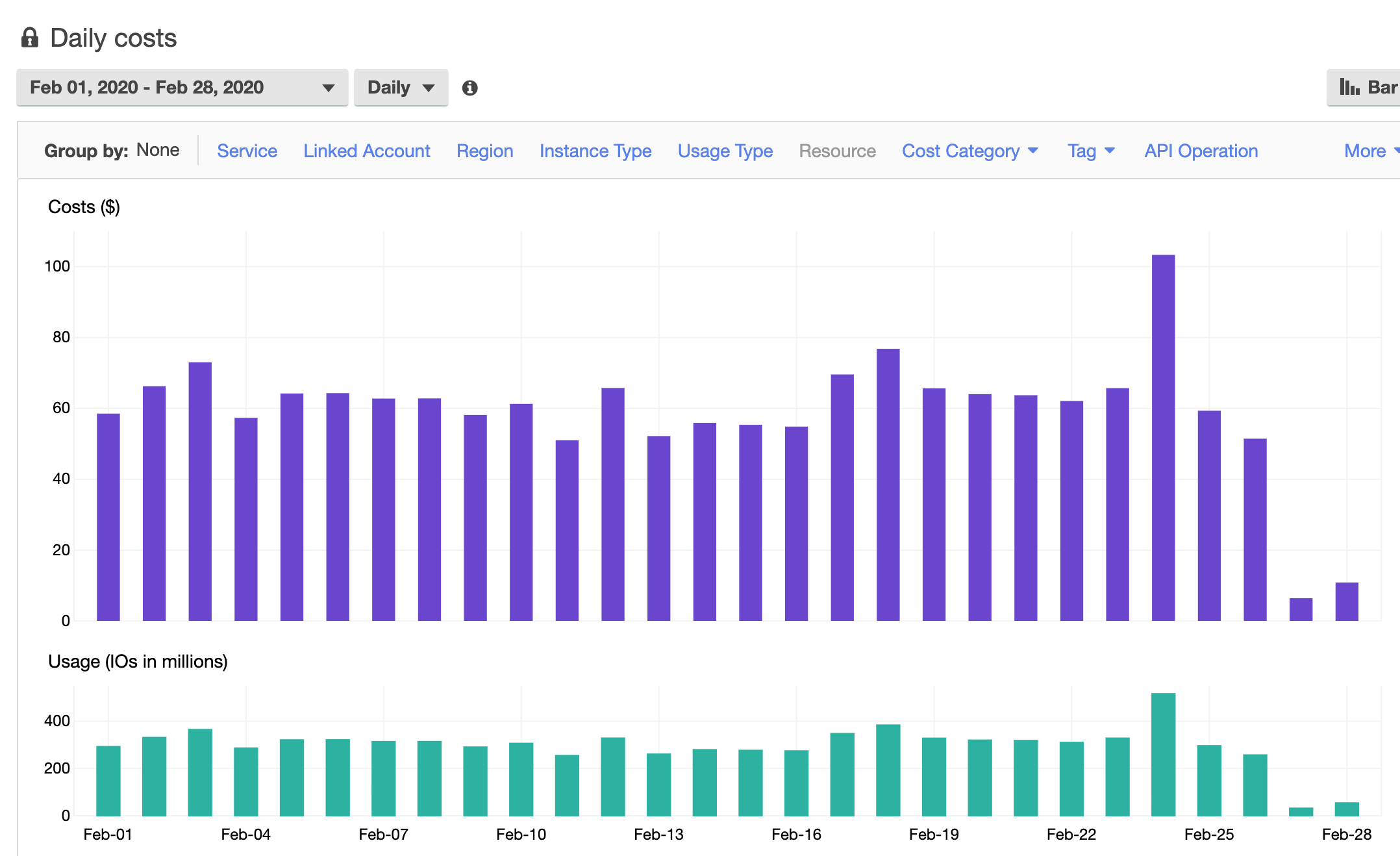
Our IO costs dropped by fifty bucks a day just with that one change.
Performance tuning in the cloud is about the tipping point.
No, not the tipping point of index seeks vs table scans: the point where increasing ongoing costs mean that you should stop what you’re doing and focus on eliminating some technical debt.
When we’re in the cloud, it’s up to us, the data professionals, to:
- Review our monthly bill from time to time
- Understand what IT operations are generating new costs (like in our case, read IOs)
- Dig into which queries are causing those IT operations (like in our case, an inefficient view)
- Figure out the most cost-effective fix for those operations
- And then maybe most importantly for your career, produce the fix, and take credit for the new lower costs
Good data professionals can pay for themselves in reduced hosting costs. I know because I do it for other folks all the time – I just needed to do it for myself, too. Eagle-eyed readers will note that the dates on these screenshots are February. Yes, this happened a couple months ago – but what prompted me to write the post is that our costs have started creeping back up again, hahaha, so it’s time for me to go through and do another round of checks!
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
Fully agree
I have always found that all the promises of the cloud to save money were based on extremely optimistic assumptions that there would be no new support costs and that most of the support you were doing on-prem would just disappear. Your on-prem infrastructure previously being majorly oversized isn’t a real example of the cloud saving you money, when you correctly size in the cloud. Improving code so that it is more efficient to reduce cloud subscription costs, is an expense that you were able to ignore on-prem, while spending a little more on RAM, but is required to prevent the cloud from eating you alive. The reason why the code was bad in the first place is usually from only being able to triage the most serious problems and some queries running a little bit slow go to the bottom, and you ended up paying some overtime to fix it or bringing in a consultant you wouldn’t have otherwise.
Having someone watch contracts like a hawk for cost overruns and plan for migrations as products get discontinued relatively abruptly in *aaS offerings is an expense you don’t have on prem. It usually requires dedicating one of your more expensive resources who understands what is happening throughout the stack, who could otherwise be doing things of operational value. Or you can let the beancounters monitor it and put your raises at risk.
But I am enjoying it as a consultant. As the high level technical resources become rarer and rarer, my bill rate goes up and up and I’m making more now than what a few years ago, I thought I would be able to make without getting into development or management.
Curious is you have looked at a lower end flavor of SQL DB using DTU’s? That can be very inexpensive. Philosophically, Azure database resources tend to throttle rather than allow you run up a big bill accidentally. There are pros and cons with each approach. Generally, I prefer the ‘throttle and don’t accidentally break the bank’ approach.
P.S. Azure also has a really nice managed MySQL, PotgreSQL, and MariaDB offering. #JustSaying. 🙂
Brian – nah, I wrote why we chose Amazon Web Services here: https://www.brentozar.com/archive/2018/03/building-sql-constantcare-part-2-the-serverless-architecture/
AWS was a couple/few years ahead of Microsoft when it came to serverless, and I’d say they still are.
Thanks though!
It’s a funny thing… I’ve seen a lot of people move to the cloud to use other products because it was “too difficult to learn T-SQL to create good code” to “avoid costs and improve performance”. They (not you) spend a whole lot of time learning something new but the same old habits prevail (especially the one about not really learning the tools well) and they end up spending a shedload of money on something that still sucks. 😀
People just don’t understand when I remind people that the cloud is just someone else’s hardware and that the code is still theirs.
Jeff – it’s true! And now you pay to rent someone else’s hardware…
I’m amazed at how much that view cost you. There’s a pretty good example of how something that is “fixed” in nature costs you so much more on the cloud.
Thank you for taking the time to write this “small” but expensive issue up, Brent. I really appreciate it.
Jeff – you’re welcome, sir!
Cloud = cheaper applies only the use cases where the usuage can scale up/down, i..e. a retailer with a seasonable pattern at the end of the year. Instead of sizing for the highest peak of the year (and them some extra margin) you can scale your capacity and thus costs.
For businesses with a fixed load… not cheaper.
But I like the flexility and the rate of change. 3 clicks and you have new stuff up-and-running. Instead of waiting on the yearly release cycle of the vendor and installing and patching the whole development street with major effort, Azure SQL DB gets automatically all the new goodies and is always patched.
Don’t dismiss the lowered cost for your patching cycle… which is shifted to watching cost elsewhere 😉
We have a fixed load on our (small) internal data warehouse. The Azure SQL DB, together with ADF and other pipeline tools cost us about $150 a month. Not sure we could get the same numbers on-premises when you have to pay a full SQL Server license.
Good point! The old CAPEX/OPEX consideration.
MS is pushing us for moving our old db’s to Managed Instance. So we had the capex already and the opex is much lower keeping the stuff on IaaS. The migration effort + the ‘low’ cost for software assurance, is totally not worth the effort.
New databases are considered for PaaS first and then IaaS as we are hitting the capex first. Unless we dump it on an existing SQL server, but that is not a limitless strategy haha
Can you share your experience with Aurora so far? Did you have any issues/outages?
It’s been brilliant. Totally love it.