
How to Think Like the SQL Server Engine: Should Columns Go In the Key or the Includes?
In our last episode, in between crab rangoons, I had you create either one of these two indexes:
|
1 2 3 4 5 6 7 |
CREATE INDEX IX_LastAccessDate_Id_Includes ON dbo.Users(LastAccessDate, Id) INCLUDE (DisplayName, Age); GO CREATE INDEX IX_LastAccessDate_Id_DisplayName_Age ON dbo.Users(LastAccessDate, Id, DisplayName, Age); GO |
And I said that the leaf pages of either index would look the same:
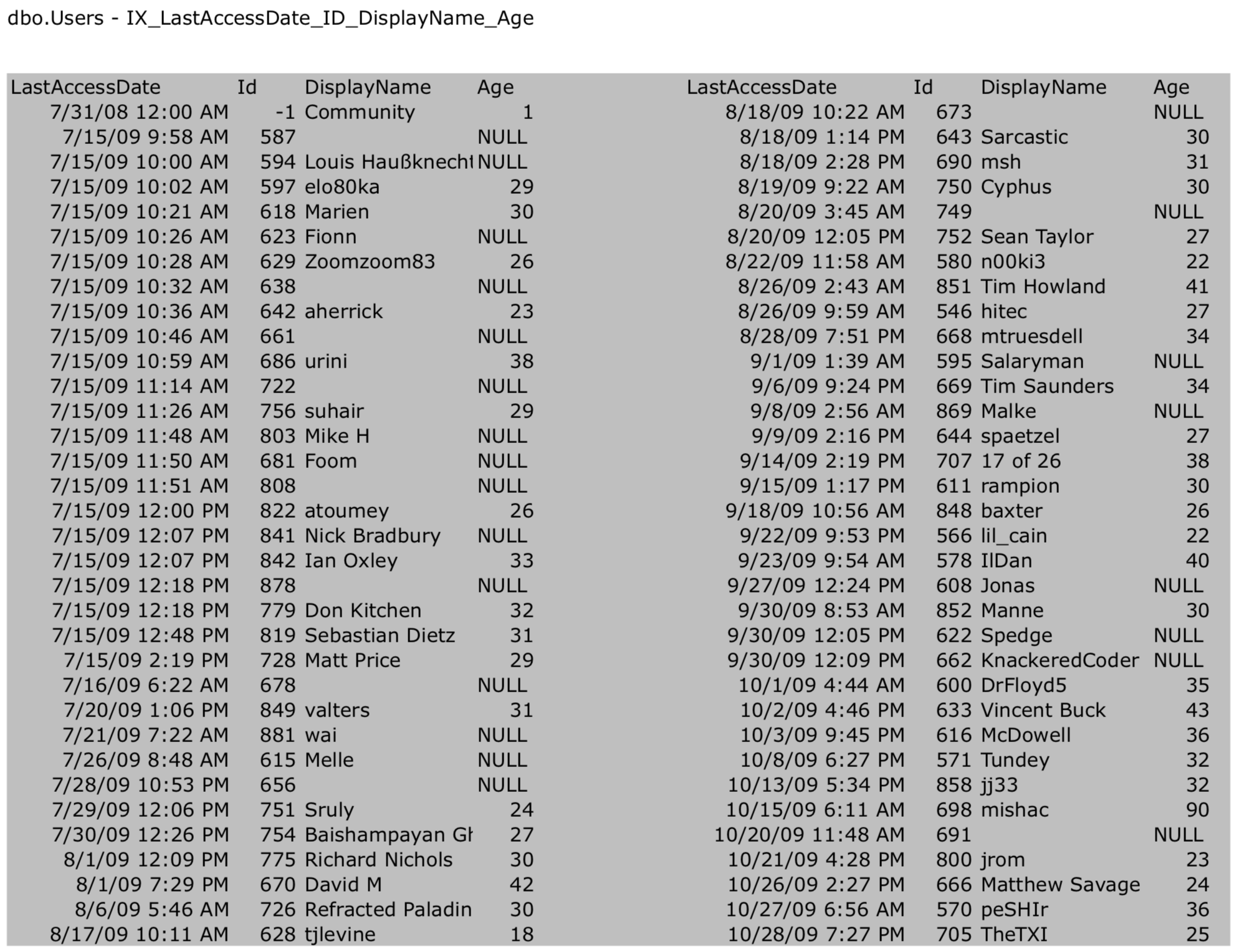
In terms of the space they take up on the leaf pages, it doesn’t matter whether columns are in the keys of an index or in the includes. It’s the same amount of space on the leaf pages. To see it, run sp_BlitzIndex focused on that table:

And note that the two highlighted indexes at the bottom – which are the two indexes I told you to choose from – take 12.4MB and 12.5MB. The difference in size has to do with the tree pages that help SQL Server get to a specific leaf page. If you wanna learn more about that, pick up a book on SQL Server internals – any of them will do, since this part of the topic hasn’t changed in decades.
Somehow, people think included columns are cheap.
I don’t know how this happened, but an urban legend developed around INCLUDE columns that they’re somehow blazing fast and inexpensive. To understand why, think about this query:
|
1 2 3 |
UPDATE dbo.Users SET Age = Age + 1 WHERE Id = 643; |
If we ONLY have this index:
|
1 2 |
CREATE INDEX IX_LastAccessDate_Id_DisplayName_Age ON dbo.Users(LastAccessDate, Id, DisplayName, Age); |
Then here’s how the update’s execution plan looks:
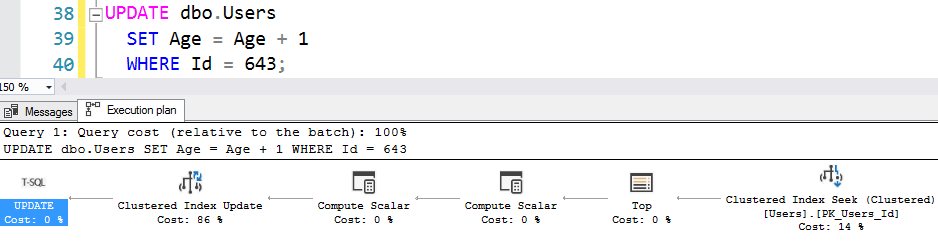
Remember, we read plans right to left, so here’s the work we did, although not necessarily in order – and note that I’m including more details than the plan shows graphically because there’s more work to be done than is immediately visually apparent:
- Look up user #643 on the clustered index by doing a seek – because thankfully our kind developer included the clustered primary key in the where clause
- (If the relevant clustered index pages for this user aren’t in memory, fetch them from disk)
- Get user #643’s LastAccessDate, Id, DisplayName, and Age so that we can look them up quickly on the gray index
- Look up that LastAccessDate, Id, DisplayName, and Age in the IX_LastAccessDate_Id_DisplayName_Age
- (If the relevant nonclustered index pages aren’t in memory, fetch them from disk)
- Lock these rows that need to be updated
- Write to the transaction log file indicating what we’re going to change
- Change the data page(s) for the clustered index
- Change the data page(s) for the nonclustered index, including moving a row around to different pages if necessary (like if the key values changed enough to merit being on an entirely new page)
- Later – asynchronously – write the changed data pages to disk
What’s that, you say? You didn’t see all that on the plan? Well, a lot of it is hidden at first glance, and you have to hover your mouse over various tooltips (or infer stuff to figure it out.) For example, here’s the nonclustered index update, hidden in the clustered index update:

Do included columns require less work?
You tell me: take a look at that 10-point checklist above, and tell me what would be different if we had this index:
|
1 2 3 |
CREATE INDEX IX_LastAccessDate_Id_Includes ON dbo.Users(LastAccessDate, Id) INCLUDE (DisplayName, Age); |
And we ran this specific query:
|
1 2 3 |
UPDATE dbo.Users SET Age = Age + 1 WHERE Id = 643; |
And I’ll give you a hint: the user involved is at the top right of this gray page:
So you can work through the query yourself with a pen and paper to figure out how much better off we’d be if DisplayName and Age were only included columns rather than part of the key. You can rant and throw things in the comments, and I’ll follow up with the answers in our next episode in this series.

27 Comments. Leave new
Is the only change would be on line #3 ? “Get user #643’s LastAccessDate, Id so that we can look them up quickly on the gray index”
There is another myth out there that included columns in your index is best used as a covering index (Covering all columns in your select) however i have run multiple selects on the Users table to return the exact columns in the select statement but SQL always chooses the index with the columns in the key. Weird
It really seems like there is almost an identical amount of work involved between the two.
My mind is blown. Here I was thinking I was saving some dramatic space by putting data in the leaf pages vs the tree.
With this in mind, it sounds like its always worth testing each index (with columns in the key and columns in the include) to see if there is a significant space difference and if it’s worth the extra limitations of “not” having those columns in the key.
I mean if we are talking about building a “covering” index putting those columns in the key would could help optimize future SQL statements for practically the same costs. Why limit your queries?
Daniel – as the old ladies with the flappy arms say, “Bingo.”
In this example it does not matter if the DisplayName and Age are part of the index key or the include columns for the Update command given. The age is most likely an int (a fixed size of 4 bytes), so regardless of the integer that is put in the field, the records on this page will remain on this page. However, in other examples, it would matter. For example an index on Users (State, City) compared to Users (State) INCLUDE (City), where changing a city name from ‘Albany’ to ‘Wright’ could cause the indexed value to be moved on to the next page for Users (State, City) and remain on the existing page for Users (State) INCLUDE (City), as the Include columns are not sorted like the key fields are in an index.
Stephen – very good, but keep thinking: can you imagine a scenario where you would want the index to be keyed on State, but only have City in the includes, completely unsorted? That doesn’t seem like a very useful index when you’re looking for people, does it?
You’re on a good track, but you’ve gotta dig a little deeper: come up with a more real world scenario.
I’d always try to think about scale, even though the difference is not that big in this case, having larger index keys makes queries slower in general because more pages need to be read. Even if we are talking about only one page, executing this query 1 million times causes 1 million more page read.
Also, thinking the same way about the possibility to move that row to a new page when we update DisplayName instead of Age makes me keep extra columns in INCLUDE.
I’d rather keep them in INCLUDE unless it’s necessary.
Ehsan – so you think if we change the DisplayName, the row is going to move, eh? Think a little deeper – think through this example:
UPDATE dbo.Users
SET Age = Age + 1, DisplayName = ‘Optimistic’
WHERE Id = 643;
Using the gray page above, think about what’s going to happen. You’re in for a surprise…
Not in this case, but I was thinking about a different situation actually, like if we had less unique columns before DisplayName.
Actually, now that I’m thinking deeper, it’s a rare real-world scenario. Thank you for making me think deeper.
But, what do you think about my first idea? Scaling?
Ehsan – hold off on the ideas, and focus on the real-world here first with the specific questions in this blog post.
I find that the more people think about specifics, the more the ideas start to take care of themselves.
I reckon the only change is item 9, the bit after the comma (including moving a row around to different pages if necessary (like if the key values changed enough to merit being on an entirely new page)).
Although not actually included in the code example, I’d assume (making an ass of u and me) that the row is likely to be moved regardless of the change to the age column, but as a result of the leading column of the the non-clustered index (LastAccessDate) being updated by a trigger (shock, horror) not included in the code as the row actually has been accessed 😉
I’m afraid I might be wrong, but it seems indexed with included columns have little benefits – such as reducing some tree pages and tiny cost of updating indexes. But if so, I wonder, why Microsoft even bothered to implement this feature? There might be some edge cases for this that I can’t think of.
I found Microsoft’s official recommendations(https://docs.microsoft.com/en-us/sql/relational-databases/indexes/create-indexes-with-included-columns?view=sql-server-ver15). It is recommended [1] to make index key “small and efficient”, and [2] “to avoid exceeding the current index size limitations of a maximum of 32 key columns and a maximum index key size of 1,700 bytes”
On point 1, I wonder how “small and efficient” can it be, since this post proves it has little benefit. Point 2 is surely an extreme situation that should be avoided if possible in the first place. If these are the only reasons, I think it would be useful very rarely. Did I understand this correctly?
(And thank you for the great post! I also thought included columns are cheap.)
Kim – you’re welcome! On point 1, it does make sense in some rather obscure situations, like folks who try to key their index on multiple NVARCHAR(200) columns. They’re gonna have a Bad Time™. And you’re bang on for point 2 as well.
As I recall it, it has something to do with a key limit of 16 columns and total of 900 bytes limit back in SQL Server 2005 or earlier. With Included Columns we can exceed this limit.
Enlightening, humbling and annoying – as I now have a new mini project to investigate indexes.
Richard – hahaha, thanks. Those are my favorite kinds of comments to get!
AFAIK updates to key columns not only potentially moves them but cause an internal Split operator to turn updates into delete + insert pairs, which might mean more work even if the end result looks the same. Another thing is statistics of course, only key columns are stored in the (multi-column) statistics for the index. Less key columns means likely less statistic updates and more information represented given the limited steps (right?).
Goodness, you typed an awful lot without addressing a single thing in the post. 😉
Huh? I scratched on “Somehow, people think included columns are cheap.” with my comments about Split and need for more frequent statistics updates if they’re part of the key. So for the final question of “Do included columns require less work?”, the answer for that specific query is yes because only the leaf level page needs updating since Age is only an included column, it does not increase the modifcation counter for the statistics of that index (delayed costs) and does not dirty the intermediate index page.
LOL OK
Okay, so here’s my take on this. Using included column is not going to really be any more efficient than putting the columns in the key. Any change to an included column is still going to need to be applied to the leaf page of the index, so you still have that overhead. Also, if the update to the included column causes the row width to change, you could still have rows moving, page splits, etc. as if it were a column in the index key itself.
And yes, the included column is only stored in the leaf pages of the index and are not carried up through the intermediate levels of the index, but the space savings will generally not be that significant as the intermediate levels only contain a row for each page at the next level down. So actually, if the included columns make the leaf rows wider, your leaf level is likely going to require more pages to store the leaf rows.
More pages at the leaf level means more rows in the next level up, and possibly more pages, so the index is still going to be a bit bigger then an index without the extra columns. Yes, it will maybe be a bit smaller in total number of pages than an index with all the columns in the key, but probably not enough to add another level to the index (at least not more than 1 level) and it’s the number of levels in the index that is the key factor in index seeks rather than the number of pages at an index level.
And since the rows will be just as wide with the columns as included columns or as part of the key, there will be just as many pages at the leaf level either way, so no performance advantage if SQL Server performs a leaf level scan.
Included columns are mostly useful when you have a unique nonclustered index on a table and you want to add one or more columns to it to take advantage of index covering, but you don’t want those columns as part of the unique key.
For me I use the Missing Indexes DMV’s to determine where to put the fields.
The fields in the Equality_columns and Inequality_columns are in the where clauses.
The Fields in the Include_columns are in the Select Clause.
So
The columns in the equality_columns field I put in the Index.
The columns in the inequality_columns I put at the end of the Index
The columns in the Include_columns I put in the Includes
Ooo, you’d really enjoy the Fundamentals of Index Tuning class where I explain why that’s often not such a good idea. (To be a little more to the point, what you’re saying is not technically correct. Whee!)
Catching up on old emails, reading thru all your Think Like The SQL Server Engine, and now I just want crab rangoons. Dang you, Brent Ozar! P.S. The Red Apple in Stayton Oregon makes some pretty good rangoons, for a total dive bar\restaurant.
HA! And the same thing happens to me every time someone comments on this post, HAHAHA.