
How to Think Like the SQL Server Engine: Running a Query Repeatedly
Earlier in this series, we ran a query with ORDER BY, and we realized that it was CPU-intensive work that tripled the cost of the query:

Now, let’s run that query a bunch of times. In SSMS, you can add numbers after the GO, and SSMS will run your query a number of times. I’ll run it 50 times:
|
1 2 3 4 5 6 7 |
SET STATISTICS IO, TIME ON; GO SELECT Id FROM dbo.Users WHERE LastAccessDate > '2014/07/01' ORDER BY LastAccessDate; GO 50 |
I explained SET STATISTICS IO ON in the first post, but I’ve added a new option here: TIME. This adds more messages that show how much CPU time and elapsed time the query burned:
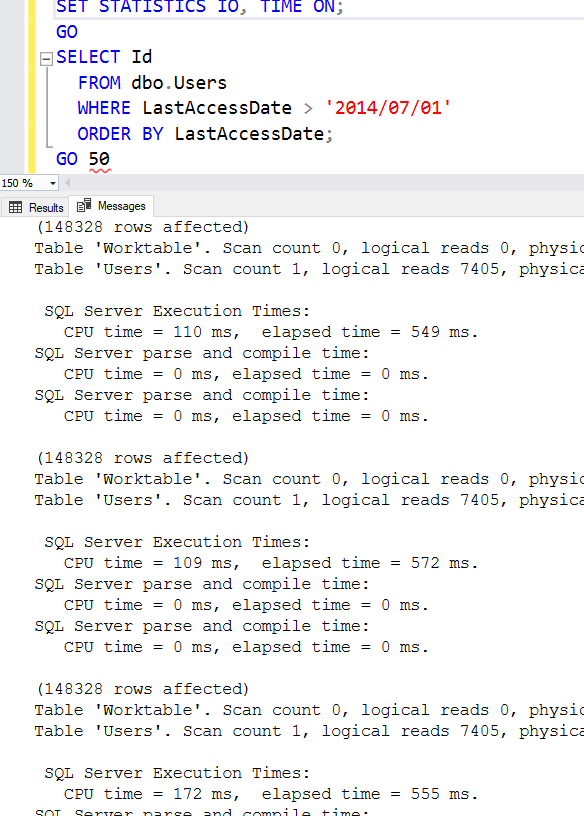
SQL Server executes the query over and over, reading the 7,405 pages each time, and doing the sort work each time.
When I was a developer, I used to be totally okay with constantly fetching data from the SQL Server. After all, I’d just run the query before, right? The data’s in cache, right? Surely SQL Server caches that sorted data so that it doesn’t have to redo all that work – especially when my queries had been doing a lot of joining, grouping, filtering, and sorting.
SQL Server caches raw data pages,
not query output.
It doesn’t matter if the data hasn’t changed. It doesn’t matter if you’re the only one in the database. It doesn’t even matter if the database is set to read-only.
SQL Server re-executes the query again from scratch.
And similarly, if 500 people are running the exact same query at the same exact time, SQL Server doesn’t execute it once and share the results across all of the sessions. Each query gets its own memory grant and does its own CPU work.
This is one of those areas where Oracle has us beat. Sometimes folks will ask me what my favorite database is, and I gotta confess that if money didn’t matter, I’d probably be really interested in Oracle. Check out their Result Cache feature: you can configure a percentage of memory to cache query results to be ready-to-go when apps keep rerunning the same query. However, at $47,500 per CPU core for Enterprise Edition licensing (check out the price sheets), I’m afraid I’m not going to be sampling any of that caviar anytime soon.
One way we can solve that problem is by caching the results in the application layer:
- The Fastest Query is the One You Never Make
- Which Queries Should You Cache in the Application?
- How to Cache Stored Procedure Results (an emergency duct-tape fix)
But another way – and the way I use most often – is to pre-bake the data in a way that makes queries run faster. That’s a nonclustered index, and I’ll cover those next.

6 Comments. Leave new
Man, Just when I though I knew how things worked I get an article like this and learn something new. I always assumed it was caching results but caching the pages makes way more sense. With 5 seconds of thought…”Yes storing the results of that cartesian product query I just stupidly wrote would be a great idea!”
Simon – isn’t that awesome? There are so many things I learn about SQL Server where I say afterwards, “Oh well now it’s obvious, but before…”
On the licensing, is that per physical core, or logical? IBM Power has 4 threads per core. Also don’t forget the 10,450 for updates and support. Is that per year?
Show some love for you account rep!
Joe – it gets worse: if you license the physical box, it’s per physical. If you license the VM, it’s per logical. 😉
This used to be the sort of situation where we started thinking about building a materialized view (“precomputed result set”) that could be refreshed on demand or by schedule. A number of DBMSs provide this facility. Such creatures are usually available to the optimizer to consider fetching from when resolving a new query request instead of going directly to the base tables of the materialized view. SQL Server’s analogue is an indexed view.
Jim – you’re a little ahead of yourself here. We don’t even have a nonclustered index yet. Stay tuned. 😀