
ColumnStore Indexes: Rowgroup Elimination and Parameter Sniffing In Stored Procedures
Yazoo
Over on his blog, fellow Query Plan aficionado Joe Obbish has a Great Post, Brent® about query patterns that qualify for Rowgroup Elimination. This is really important to performance! It allows scans to skip over stuff it doesn’t need, like skipping over the dialog in, uh… movies with really good fight scenes.
Car chases?
Soundtracks?
Soundtracks.
Fad Gadget
With Joe’s permission (we’re a polite people, here) I decided to pick on one of the queries that was eligible for Rowgroup Elimination and stick it in a stored procedure to see what would happen. I’m interested in a couple things.
- Is Rowgroup Elimination considered safe with variables?
- Will the plan change if different numbers of Rowgroups are skipped?
With those in mind, let’s create a proc to test those out. Head on over to Joe’s post if you want the setup scripts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DROP PROCEDURE IF EXISTS #wonky_eye; GO CREATE PROCEDURE #wonky_eye ( @idlow BIGINT, @idhigh BIGINT ) AS BEGIN SELECT MAX(ID) FROM dbo.MILLIONAIRE_CCI WHERE ID BETWEEN @idlow AND @idhigh; END; GO |
With literal values, the optimizer/storage engine/unicorn toenails behind the scenes are able to figure out which Rowgroups are needed to satisfy our query.
With stored procedures, though, the first execution will cache a particular plan, and the rest of the queries will reuse that plan.
Let’s test our first hypothesis! Will different passed in values result in appropriate Rowgroup Elimination?
|
1 2 3 4 5 6 |
EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 1000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 10000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 1000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 10000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000000 |
All of those queries use the exact same execution plan:

But do they all use it as efficiently?
Well, in short, no.
Things start off okay, and to be fair, Rowgroup Elimination occurs as appropriate.
|
1 2 3 4 5 6 7 8 9 |
Table 'MILLIONAIRE_CCI'. Segment reads 1, segment skipped 99. Table 'MILLIONAIRE_CCI'. Segment reads 1, segment skipped 99. Table 'MILLIONAIRE_CCI'. Segment reads 1, segment skipped 99. Table 'MILLIONAIRE_CCI'. Segment reads 1, segment skipped 99. Table 'MILLIONAIRE_CCI'. Segment reads 10, segment skipped 90. |
But once our high ID hits 10000000, things start to slow down.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms. SQL Server Execution Times: CPU time = 47 ms, elapsed time = 50 ms. SQL Server Execution Times: CPU time = 500 ms, elapsed time = 492 ms. |
And by the time we hit ID 100000000, things have melted into a fondue almost no one would want.
|
1 2 3 4 |
Table 'MILLIONAIRE_CCI'. Segment reads 100, segment skipped 0. SQL Server Execution Times: CPU time = 5110 ms, elapsed time = 5095 ms. |
Five seconds! Five! Who has that kind of time on their hands?
The performance cliff can be further exposed by incrementing IDs between 10000000 and 100000000.
While Rowgroup Elimination occurs just like before, CPU keeps on going up.
|
1 2 3 4 5 6 7 8 |
EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 20000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 30000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 40000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 50000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 60000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 70000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 80000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 90000000 |
It looks like we found a potential tipping point where a different plan would be more effective.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SQL Server Execution Times: CPU time = 1000 ms, elapsed time = 995 ms. SQL Server Execution Times: CPU time = 1469 ms, elapsed time = 1463 ms. SQL Server Execution Times: CPU time = 1953 ms, elapsed time = 1951 ms. SQL Server Execution Times: CPU time = 2437 ms, elapsed time = 2440 ms. SQL Server Execution Times: CPU time = 2922 ms, elapsed time = 2926 ms. SQL Server Execution Times: CPU time = 3422 ms, elapsed time = 3414 ms. SQL Server Execution Times: CPU time = 3906 ms, elapsed time = 3916 ms. SQL Server Execution Times: CPU time = 4391 ms, elapsed time = 4392 ms. |
State of Confusion
So where are we? Well, we found that Rowgroup Elimination is possible in stored procedures with ColumnStore indexes, but that the cached plan doesn’t change based on feedback from that elimination.
- Good news: elimination can occur with variables passed in.
- Bad news: that cached plan sticks with you like belly fat at a desk job
Remember our plan? It used a Stream Aggregate to process the MAX. Stream Aggregates are preferred for small, and/or ordered sets.
How do we know this is the wrong plan, here? How can we test it?
If we run the stored proc once the regular way, and once with a RECOMPILE hint, well…
|
1 2 |
EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000000 WITH RECOMPILE |
The query plans decide to be cheeky and have similar costs. You’ll notice that the Hash Match plan is 51% of the cost, and the Stream Aggregate plan is 49%. The relative difference is tiny, though. The Stream Aggregate plan costs 27.8431 query bucks, and the Hash Match plan costs 28.8442 query bucks. That’s a difference of 1.0011 query bucks, which is exactly the cost difference between the Stream Aggregate operator, and the Hash Match operator.
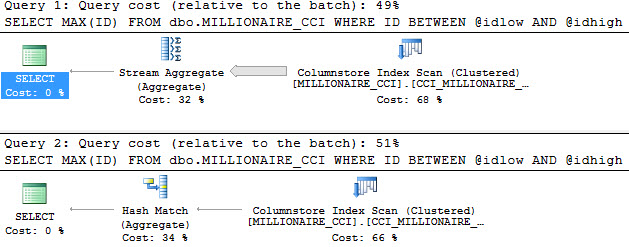
But in this case, cost is one of those awful, lying metrics. Let’s look at the different execution times.
|
1 2 3 4 5 |
SQL Server Execution Times: CPU time = 4969 ms, elapsed time = 4957 ms. SQL Server Execution Times: CPU time = 47 ms, elapsed time = 49 ms. |
The plan with the RECOMPILE hint finished in 49ms. That’s, like, 1000x faster. The difference of course is the Hash Match Aggregate operator replacing the Stream Aggregate operator.
So what happens if we run things in reverse order after freeing the cache?
|
1 2 3 |
EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000000 EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 1000 |
It turns out that the Hash Match Aggregate plan is just as good for the ‘small’ query. It has the same metrics that it did when using the Stream Aggregate plan when it ran first. In this case, there are no other differences to account for, like Key Lookups, or Parallelism.
Happy Mondays
We’ve come this far, so let’s answer one last question: At which point will ol’ crazypants choose the Hash Match plan over the Stream Aggregate plan? To answer that, we’ll go back to our original test scheme, and add in recompiles so each execution gets a fresh plan.
|
1 2 3 4 5 6 |
EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 1000 WITH RECOMPILE EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 10000 WITH RECOMPILE EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000 WITH RECOMPILE EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 1000000 WITH RECOMPILE EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 10000000 WITH RECOMPILE EXEC dbo.#wonky_eye @idlow = 1, @idhigh = 100000000 WITH RECOMPILE |
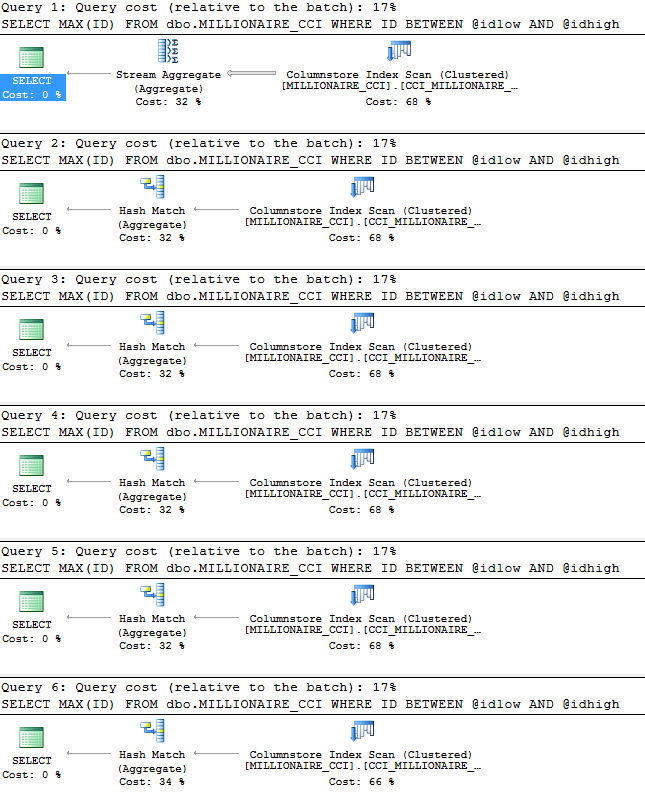
The answer is, unfortunately, pretty early on. The second query chooses the Hash Match plan, which means that, well, almost every single execution would have been better off with a different set of values passed in first, and the Hash Match plan chosen. Hmpf.
Human League
What did we learn, after all these words? Rowgroup Elimination is possible in stored procedures, but it doesn’t provide any feedback to plan choice. No matter how many were eliminated or not, the plan remained the same. As eliminations decreased, performance got worse using the ‘small’ plan. This is textbook parameter sniffing, but with a twist.
I also tested this stuff on 2017, and there was no Adaptive magic that I could find.
Thanks for reading!

5 Comments. Leave new
Great Post, Brent®!
Thanks, Brent®!
I bet that Eric guy is jealous of this well-written Brent® post.
Excellent post, but in all fairness 49 ms is only a hundred times faster than 4957
Cool, so every time you take out your phone I want you to count to 5 before you turn on the screen, unlock it, read a message, respond to a message, or make a phone call. Sound good?