
What’s In Your Development Database? The Answer: Production Data.
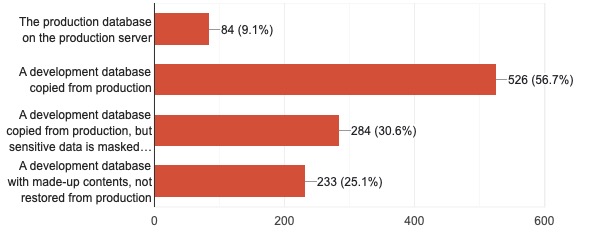
Are your developers working with live production data, completely made-up synthetic data, or something in between? I posted a poll here on the blog and on a few of my social media feeds, and here were the results:

Note that the numbers can add up to more than 100% because folks could mark multiple choices if they had multiple teams with different approaches.
I also posted it on Reddit, which has its own separate (smaller) results, but I like having samples from more audiences:

No matter which way you slice it, about half are letting developers work with data straight outta production. We’re not masking personally identifiable data before the developers get access to it.
It was the same story about 5 years ago when I asked the same question, and back then, about 2/3 of the time, developers were using production data as-is:
Someone’s gonna ask, “So Brent, what do you recommend to fix this problem?” And I just don’t have easy answers. Over a decade ago, I explained why masking data is so hard, and the commenters chimed in about the difficulties they were having.
So when vendors claim to have solved this problem, what’s the catch?
One group of products focuses on building fake data from scratch, which is fantastic in the sense that you can pre-build testing data without waiting around for customers, and you never have to worry about getting the sanitization right. However, you have to define your tables & relationships in those tools, and you’re relying on those tools to generate the same kinds of data distribution and outlier users that you end up with in production. My clients who use these tools tend to struggle with reproducing parameter sniffing issues, for example, because the created data is too evenly distributed and doesn’t account for the crazy things users do in production.
Another set of products focuses on sanitizing prod data, which is cool because you can maintain the same data distribution, but less cool because you have to define every column that needs to be sanitized, keep those definitions up to date as you add/change tables, and then when you need to refresh development, wait for the data to be sanitized. These tools make it easier to troubleshoot parameter sniffing issues, for example.
Both kinds of tools require time & attention from data modelers. You have to lay out your entire data model and define what parts of it are private. Honestly, I love this, and everyone should do it.
When Microsoft announced Purview, I thought, “This is another really good idea that very few people will ever use.” It’d be amazing if we had a central dictionary that defined every column in every table in every database. Row-level security tools could plug into that to determine who’s allowed to see PII. Data cleansing tools could plug into that whenever they needed to sanitize production data. It’d be an amazing single source of truth for all kinds of utilities.
However, back here in reality, we can’t even agree on what utilities to use, let alone the central dictionary for them all to rely on.
Back here in the reality of 2024, we’re still developing with raw production data. <sigh> We’ve got so much work to do.

11 Comments. Leave new
We do because we dont have any personally identifiable data, its just TV scheduling data and often we need that exact data to track down an issue and provide a fix.
It took me years, but I’m one of the lucky ones who changed my answer from five years ago – we moved from “production data in dev” to “masked production data in dev.” I have the rise in public data leaks to thank – finally management agreed that this was a serious issue!
I worked for MCI Worldcom in ’99 (Oracle production support dba) and EDS supporting the same client 2001-2004 (same Oracle dba role). The dev teams would not accept anything less than a copy of production databases so they could reproduce any potential performance issues that could arise and thoroughly test new features and modifications with existing data.
My dev folks are also the same peeps that do tier 3 support, so there are no real access issues, and our test/dev environment is protected just like our production environment. We refresh our test/dev environments regularly, so we can reproduce issues as necessary.
Many years ago I worked for a major IT company – and used a ‘randomizing routine’ developed by 1 of their senior guys – almost as a hobby. It took a DB and randomly reordered data specific columns of specific tables – based on inclusion in a control table. Randomising of each column was by a 1-off id based on the current timestamp but never recorded.
It proved impossible to reverse (believe me we tried), or find data relating to real world persons or entities, but the data retained (almost) all characteristics of data patterns, and though implicit relationships could become masked – eg. concentrations of a surname in a state/county, certainly enough to support development and perf testing.
The data was not on SQL Server but for and processed on a mainframe platform – using utilities contained therein. Over the years I’ve always wondered if something similar could be developed for SQL – but never had the time
So that is MUCH easier to do in a hierarchical database than SQL. A former client used a solution like that to create testing date to do dev on a new compliance reporting format templated off of real data, and narrative fields were set to “Now is the time for all good men to come to the aid of his country” It could be run several times to create new edge cases for the report validation to test, but still maintain realistic data distributions for a report that otherwise has millions upon millions of data combinations.
much easier to do in a hierarchy database than relational*
[…] Brent Ozar looks at survey results: […]
As long as the developers needs to be able to work on the prod data too (support, troubleshooting etc.) and the DEV system is protected similar to the prod system, I see no problems.
Okay, maybe if it are 100 developers who all have DBA permissions on prod and dev…
My experience is that there are a lot of data concerns that require an investment of time, money, manpower, tooling to address fundamentals such as data quality, data masking, data lineage etc. It isn’t “buy a tool and a miracle will occur”, which is what is a recurring fantasy for management.
The reality is that Data Governance needs to be a recognised business function, supported from the top of the organisation down. It’s a big topic encompassing ownership, stewardship and compliance. Again, from my experience, there is an unspoken, unwritten assumption that DBAs are responsible for all things data but Governance is simply too big a subject to fob off on a technical team to deal with in isolation.
See https://keeshinds.com/blog/kDSBlog20250317.html