
Parameter Sniffing in SQL Server 2019: Adaptive Joins
So far, I’ve talked about how adaptive memory grants both help and worsen parameter sniffing, and how the new air_quote_actual plans don’t accurately show what happened. But so far, I’ve been using a simple one-table query – let’s see what happens when I add a join and a supporting index:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE INDEX IX_OwnerUserId_Includes ON dbo.Posts(OwnerUserId) INCLUDE (Score, Title); GO /* Let's add a join and change the sort order */ CREATE OR ALTER PROC dbo.usp_UsersByReputation @Reputation INT AS SELECT TOP 1000 u.*, p.Title, p.Score, p.Id FROM dbo.Users u JOIN dbo.Posts p ON p.OwnerUserId = u.Id WHERE u.Reputation = @Reputation ORDER BY p.Score DESC; GO /* Run it and see what happens: */ EXEC usp_UsersByReputation @Reputation = 3; |
(Careful readers will note that I’m using a different reputation value than I used in the last posts – hold that thought. We’ll come back to that.)
The execution plan leverages a new 2019 feature, adaptive joins for rowstore tables. They were available to queries with a columnstore index in 2017, but this is a new icon to see in a rowstore-only plan:

In this query plan:
- SQL Server started with a clustered index scan on Users, and produced 50k matching rows.
- It then had to decide how to use the index on Posts.OwnerUserId. For low numbers of rows (in this case, 36,700 or less, a threshold visible in the plan’s tooltips), it would have preferred an index seek for each matching row. For higher numbers, it would prefer to scan that index.
- Because our number of rows exceeded the adaptive threshold, it went with a scan.
I can hear you cheering because this is awesome. It means your plans are less susceptible to parameter sniffing problems because now SQL Server can cache one plan that adapts to more input parameters.
Narrator: “Sadly, the reader was incorrect.”
Now run it for @Reputation = 1. As we saw in earlier posts, @Reputation = 1 produces a lot more data – about 1M rows in this case – so it’s not surprising that something goes wrong. In this case, the adaptive join didn’t grant enough memory, so it spills 12,880 pages to disk:

That in and of itself isn’t really all that bad, though – and if I continue executing @Reputation = 1 several times in a row, adaptive memory grants kick in and stabilize memory at 288MB. The query stops spilling to disk, and it goes faster.
Until I run it just once for @Reputation = 2, at which point the memory grant starts dropping – and it can drop down to just 7MB. You saw in the first post how that story ends: the memory grants swing back and forth, constantly basing a query’s memory grant on the parameters used the last time the query ran, not the current parameters.
Heaven forbid I run it for @Reputation = 1 right after I run it for @Reputation = 2:
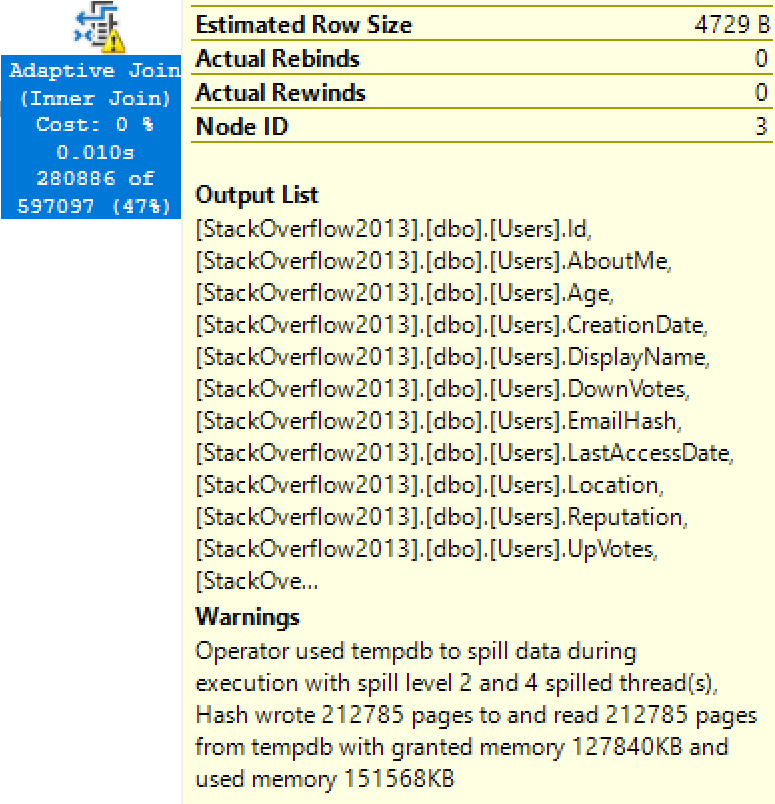
And remember: if you try to diagnose why this query took >10 seconds, you can’t see spills in the new air_quote_actual plans in 2019 yet – but they’re hopefully coming for RTM.
So what’s a good plan for @Reputation = 1, then?
Oh, dear reader. Oh, sweet friend. Let’s run it for @Reputation 1, 2, and 3, all with recompile on so we can see what plan will get put into cache when each variation happens to run first:
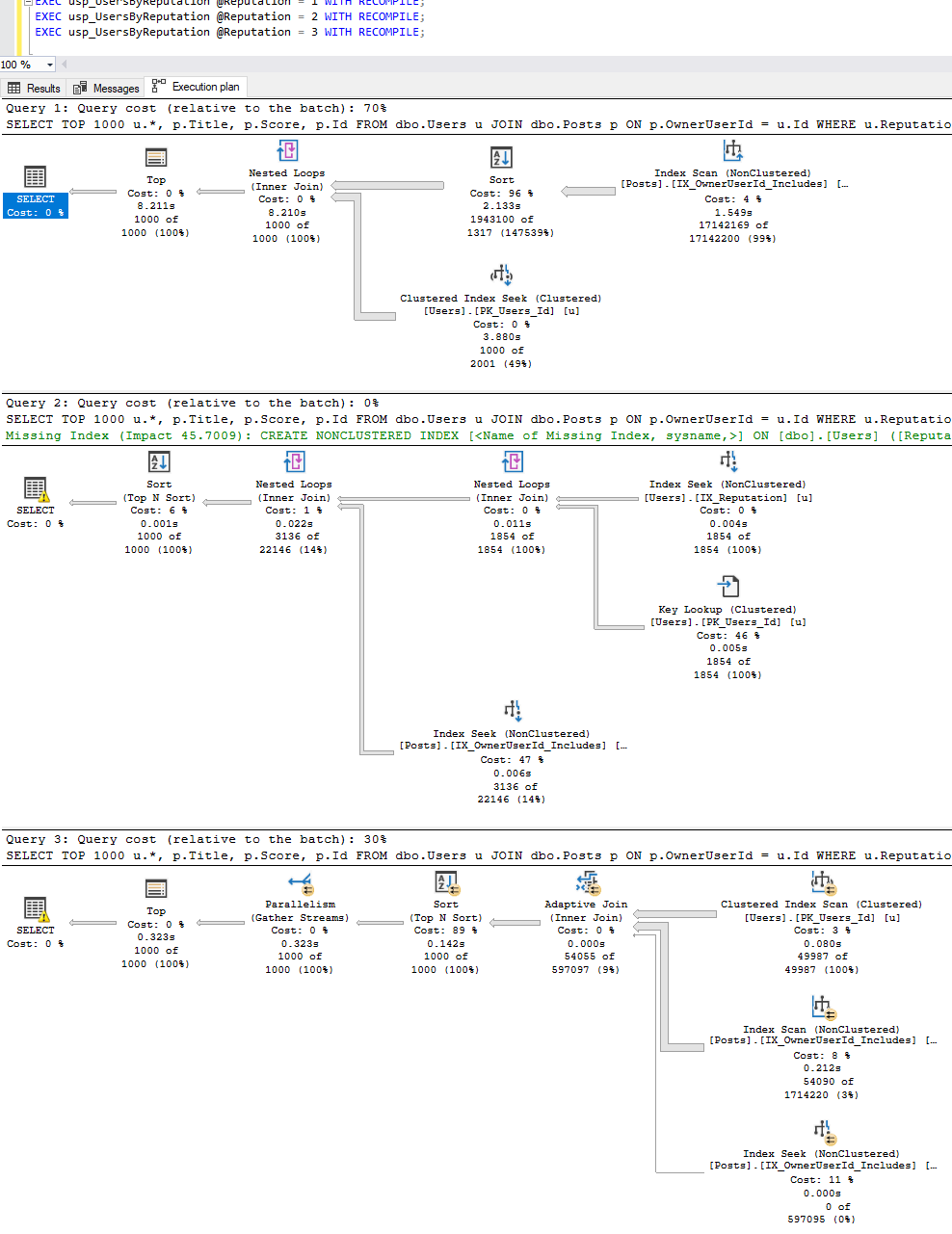
For a simple one-join query with only one parameter, three different-shaped plans are cached for three different input values, and they effectively produce 4 different plans since one of those is an adaptive join.
- @Reputation = 1 caches a plan that starts with a Posts index scan in batch mode
- @Reputation = 2 caches a plan that starts with a Users index seek, and does everything but the sort in rowstore mode
- @Reputation = 3 caches an adaptive join plan that either scans a Posts index in batch mode, or seeks it in rowstore mode

This isn’t a new phenomenon because complex queries can often produce wildly different plans, but SQL Server 2019 just makes it happen more often, with even simpler queries, because now we’ve got the option of adaptive joins and batch mode. SQL Server has exponentially more plans to choose from, and in the early days of 2019, some of these to backfire, hard.
Parameter sniffing isn’t getting easier with 2019.
It’s getting harder.
Much, much harder, to the point where it’s getting to be time for a mind shift amongst query authors. In theory, we have to stop asking, “Why was this query slow the last time I ran it?” and start asking, “How can I change this query to be more predictably fast?” I just don’t see that mind shift happening anytime soon, though. That’s not the way humans work. We’re all about shipping a good enough query, quickly. It’s a miracle that our queries even compile, let alone produce accurate results, let alone perform well.
SQL Server tuning work ebbs and flows.
In some SQL Server versions, the job of performance tuning gets easier. SQL Server 2016 comes to mind: for many SPs and CUs, many of which got backported to 2012 and 2014, we were blessed with a continued stream of diagnostic data improvements that made it way simpler to diagnose complex problems like memory grants, spills, and poison waits like RESOURCE_SEMAPHORE and THREADPOOL.
In other versions, SQL Server adds new features faster than the supporting diagnostic infrastructure can keep up. SQL Server 2014’s new Cardinality Estimator, In-Memory OLTP (Hekaton), and updated columnstore indexes were good examples of that: you could use ’em, but boy, they could backfire without warning.
Microsoft’s obviously going to say that SQL Server 2019 is in the make-life-easier category because the robots do more for you. However, the robots have brand new, untested, not-very-well-documented choices that they’ve never had before, and it’s much harder for you to see what they did after the fact.
Based on my time with 2019 so far, I think it’s going to be a lot like 2014. People are going to:
- Put 2019 in their testing environment
- Test their worst queries under 2019 compatibility level, and be pleasantly surprised
- Go live with 2019 (but they won’t enable Query Store because they don’t know why or how, and the defaults don’t make sense)
- Have their server catch fire with unexpected query plan regressions
- Not have the time to figure out if the problem is adaptive grants, adaptive joins, or batch mode (and especially not have the time to understand that any of those could cause problems with any query)
- Switch their databases back to 2017 compatibility level (which is thankfully easy)
But instead, I really wish they would:
- Enable Query Store today, and start building up a history of good query plans that you can use to fix regressions
- Go live with 2019, but stay in 2017 compatibility level, again, building up a good history
- After a couple/few weeks, try 2019 compatibility level – but don’t be afraid to switch back if the work is overwhelming
- If the work isn’t overwhelming, use Query Store to regress specific plans, but inventory them
- For each regressed plan, start working with your developers to identify what behavior is causing a problem, and modify those queries or their supporting indexes to remove the requirement for the plan guide
That last step is so important because sooner or later, your developers are going to ship a new version of that query. They’re going to add a comment, tweak the query, or add a join, and as soon as they do, the plan guides will no longer be relevant. Remember, Query Store’s plan guides only work for exactly similar prior queries. SQL Server can’t automatically regress a query to a prior plan if you’ve never had a good plan for that exact query.
 And oh, are your plans about to change, bucko. Tomorrow, we’ll discuss the biggest change of them all: automatic inlining of user-defined functions.
And oh, are your plans about to change, bucko. Tomorrow, we’ll discuss the biggest change of them all: automatic inlining of user-defined functions.
Hey, while you’re here – I built a whole series of classes around parameter sniffing. It looks so easy, but it gets so hard – and backfires so hard. The first class: Fundamentals of Parameter Sniffing. Conquer that, and you can move on to Mastering Parameter Sniffing.

1 Comment. Leave new
Thanks for this. But I’ve been using option(recompile) more and more, for any query likely to take more than a few seconds, since about 2008.
All this stuff we’re just now getting I think was “supposed” to be in 2016, or wherever “query store” was introduced. When they pre-announced query store, I think that’s what they had in mind. Then slowly discovered “whoops, not so easy”. And it still isn’t.
I remain rather disappointed in modern SQL Server and consider it unstable, performance-wise, as databases pass the terabyte mark. More fun for professional tuners, but since time began SQL Server was supposed to be all automagic, and it just too often fails at that now, especially at scale.