
What’s New in SQL Server 2019: Faster Table Variables (And New Parameter Sniffing Issues)
For over a decade, SQL Server’s handling of table variables has been legendarily bad. I’ve long used this Stack Overflow query from Sam Saffron to illustrate terrible cardinality estimation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
declare @VoteStats table (PostId int, up int, down int) insert @VoteStats select PostId, up = sum(case when VoteTypeId = 2 then 1 else 0 end), down = sum(case when VoteTypeId = 3 then 1 else 0 end) from Votes where VoteTypeId in (2,3) group by PostId select top 100 p.Id as [Post Link] , up, down from @VoteStats join Posts p on PostId = p.Id where down > (up * 0.5) and p.CommunityOwnedDate is null and p.ClosedDate is null order by up desc GO |
It puts a bunch of data into a table variable, and then queries that same table variable. On the small StackOverflow2010 database, it takes almost a full minute, and does almost a million logical reads. Here’s the plan:

See how the top query has a cost relative to the batch of 100%, and the second query says 0%? Yeah, that’s a vicious lie: it’s based on the estimated cost of the queries, even when you’re looking at an actual plan. The root cause is the number of rows SQL Server expects to find in the table variable in the second query – hover your mouse over that:
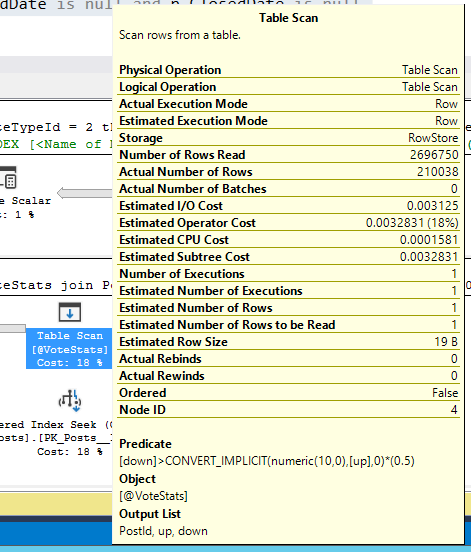
The estimated number of rows is only 1 – way low, because we just got done inserting 2.7 MILLION rows into it. As a result, SQL Server says, “I’ll just get that one row out of the table variable, do one matching index seek in the Posts table, and then I don’t have to bother sorting this data until later in the plan.”
In the past, we told people to fix it by replacing table variables with temp tables, or slapping an OPTION RECOMPILE on the relevant portions of a batch. However, both of those require changing the query – something that’s not always feasible.
Now, let’s try it in SQL Server 2019.
Same query, no changes, just running it in a database with compatibility level 150:
- Duration: before was 57 seconds, now 7 seconds with 2019
- Logical reads: before was ~1 million, now about 70k with 2019
Here’s the 2019 query plan:

Now, SQL Server 2019 estimates 800K rows will come out of the table variable – still not exactly accurate, but a hell of a lot more accurate than estimating 1 row. As a result, it decides to sort the contents of the table variables to find the top 100 rows FIRST before doing the seeks on the Posts table.
Suddenly, 2019 produces better table variable estimates out of the box. It’s all cake and no vegetables, right?
Now we have a new problem: parameter sniffing.
I’m going to create an index on Users.Location to help SQL Server understand how many rows will come back when we filter for a given location. Then, I’m going to create a stored procedure with 2 queries in it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE INDEX IX_Location ON dbo.Users(Location); GO CREATE OR ALTER PROC dbo.usp_TableVariableTest @Location NVARCHAR(40) AS BEGIN DECLARE @NotATable TABLE (ID INT); INSERT INTO @NotATable SELECT Id FROM dbo.Users WHERE Location = @Location; SELECT u.* FROM @NotATable t INNER JOIN dbo.Users u ON t.ID = u.Id ORDER BY u.DisplayName, u.Location, u.WebsiteUrl; END GO |
The first query loads the table variable with all of the users in a location.
The second query fetches the rows back out of that table variable, does a lookup, and sorts the data. This means SQL Server needs to estimate how much memory it needs to grant for the sort operation.
Let’s free the plan cache, and then call it for a really big location:
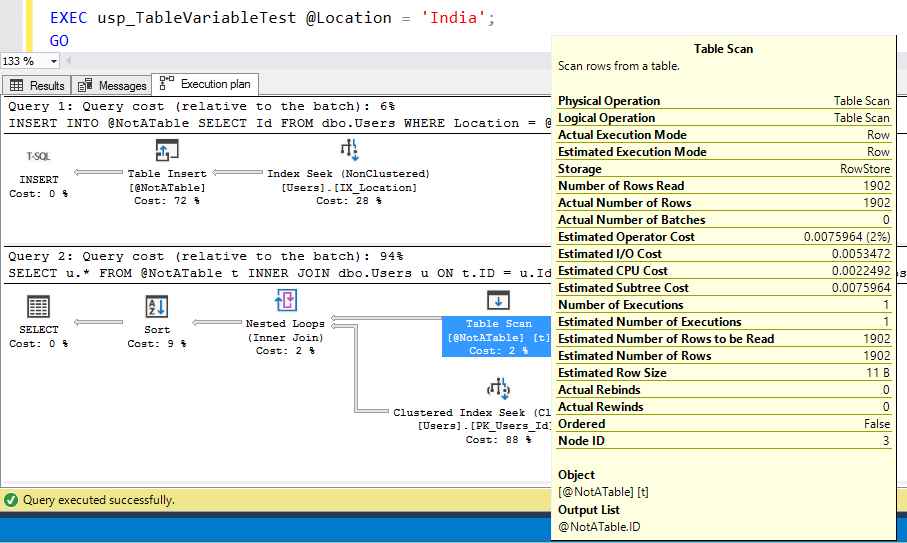
Here, I’m hovering my mouse over the table variable scan to show the estimated and actual number of rows – they’re absolutely perfect! This is awesome! That means SQL Server allocates enough memory to sort those 1,902 rows, too.
Now let’s run it for a really small location:
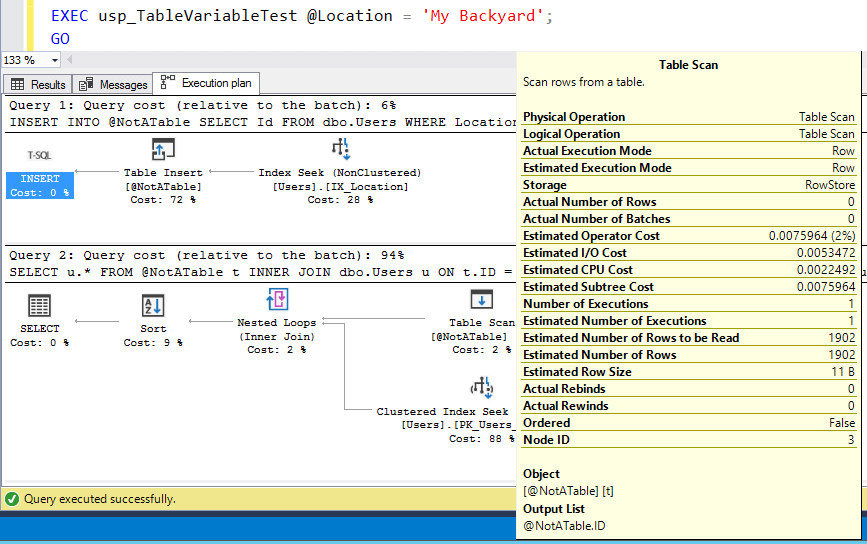
Just like every parameter sniffing issue from the dawn of time, SQL Server cached the execution plan for the first set of parameters that got sent in. Now, it’s estimating 1,902 rows – from India – every time the query runs. That’s not a big deal here where the memory over-estimation for this query isn’t large, but now let’s try it in the opposite order.
Free the plan cache, run it for My Backyard first, and SQL Server 2019 caches the execution plan for a 1-row estimate:

And then run it for India, and presto, the sort spills to disk:

Most of the time, SQL Server 2019’s table variable handling will be WAY faster.
Before, table variables generally produced bad plans ALL of the time. It was black and white. Performance just sucked.
Starting with SQL Server 2019, we stand a better chance of getting good plans at least some of the time, if not most of the time. We just have a new problem – parameter sniffing – and hey, you can learn how to fix that pretty easily. That seems like a pretty good tradeoff to me!
To learn more about this feature, check out Aaron Bertrand’s writeup on how it works in Azure SQL DB, and for other new goodies in 2019, check out what’s new (so far) in SQL Server 2019.

17 Comments. Leave new
I’ll take WAY faster, most of the time, any day. It’s a lot better than the “sucks all the time” we have now. So now for the hard part, to dream up a story to convince the vendors to support SQL 2019, and then selling the upgrade to the company.
Absolutely agree!
Hey Brent, I kind of wish I read this post prior to writing my post on dba stackexchange this morning 🙂 Do you think this might be due to switching Trace Flag 2453 on globally? It seems to be the behaviour I’d expect due to that, and that’s why I asked what’s the downside to doing so on stackexchange.
https://dba.stackexchange.com/questions/218465/reasons-for-not-globally-enabling-trace-flag-2453-cardinality-on-table-variabl
Andrew – no idea! Sorry. Brent
Hey, I hear it happens, even to the experts on the bleeding edge of the pre-release limited information variety 🙂
I’ve heard back from the Tiger Team that it is a different new feature as part of their new Intelligent Query Processing engine changes – Table Variable Deferred Compilation. So it looks like we’ll have to upgrade if we want that one 🙂 https://blogs.msdn.microsoft.com/sqlserverstorageengine/2018/07/16/public-preview-of-table-variable-deferred-compilation-in-azure-sql-database/
[…] I dug deeper into this functionality in a recent tip, Table Variable Deferred Compilation in SQL Server, and Brent Ozar has talked about it too, in Faster Table Variables (And New Parameter Sniffing Issues). […]
You may want to try adding a primary key to your table variable if it’s feasible.
[…] Mudanças na estimativa de linhas ao utilizar tabelas variáveis (compilação adiada de variável de tabela). Até o SQL Server 2019, o otimizador de consulta SEMPRE estimava 1 linha retornada ao utilizar variáveis do tipo tabela, gerando muitas vezes, operadores incorretos quando utilizados grandes massas de dados nesse tipo de objeto e tendo uma performance muito ruim. Isso fazia com que muitas pessoas utilizassem tabelas temporárias ou o hint OPTION (RECOMPILE) para evitar esse tipo de comportamento. Na versão 2019, o otimizador de consulta irá tentar estimar um número mais próximo do real, fazendo com que os resultados utilizando variáveis do tipo tabela sejam geralmente melhores que os resultados em versões anteriores. Para saber mais sobre essa novidade, veja este post do Brent Ozar […]
[…] Server 2019 preview combines SQL Server and Apache Spark to create a unified data platform | What’s New in SQL Server 2019: Faster Table Variables (And New Parameter Sniffing Issues) | What’s New in SQL Server 2019: Adaptive Memory Grants | SQL Server 2019 preview containers […]
So i’ve been playing around with the 2019 container and I noticed that if I run a list command for the data directory: docker exec sql1 bash -c “ls -l -h /var/opt/mssql/data” I see four files I’m not familiar with.
-rw-r—– 1 root root 14M Oct 3 15:07 model_msdbdata.mdf
-rw-r—– 1 root root 512K Oct 3 15:07 model_msdblog.ldf
-rw-r—– 1 root root 512K Oct 3 15:07 model_replicatedmaster.ldf
-rw-r—– 1 root root 4.0M Oct 3 15:07 model_replicatedmaster.mdf
Took a look at the 2017 container and they aren’t in there. Any idea what these are for? I don’t see them listed under the model database properties in SSMS. Can’t find any info when googling for the names.
Eric – for questions, your best bet is a Q&A site like https://dba.stackexchange.com. (I wish we could tackle everything, just not enough hours in the day.)
Will do..I understand you can’t tackle everything; just thought from reading your blog for years that this was the kind of thing you would be interested in (new files being added to a new version of SQL).
You guessed right! I’m totally interested, but I just can’t dedicate the time to it. (Responding to this while on a plane flying back home from a conference, for example.)
Hi Brent, I am thinking about writing a sql server central editorial about this subject and I would like to reference your article. Would you give me permission to mentioned your article and have a link to it in my editorial?
Thanks,
Ben
Ben – yep, absolutely, thanks!
Links broken to “Identifying and Fixing Parameter Sniffing” video on Channel 9. Did you link it to your own session?
I could find a VIdeo from 2017 on your channel
https://www.youtube.com/watch?v=pd7xqLT_-2k