
SSD RAID Load Testing Results from a Dell PowerEdge R720
We’ve got a client that does big batch jobs every day, loading hundreds of gigabytes of data or more in short bursts. They were frustrated with slow performance on the batch jobs, and after we performed our SQL Critical Care® with ’em, it was really clear that their hardware was the bottleneck. They were using a virtual server backed by an iSCSI SAN, and they were getting bottlenecked on reads and writes. We could put some more memory in it to cache more data, preventing the read problem, but we would still get bottlenecked trying to write lots of data quickly to the shared storage.
We recommended two things: first, switch to a standalone bare metal SQL Server (instead of a virtual machine), and second, switch to cheap commodity-grade local solid state storage. Both of those suggestions were a little controversial at the client, but the results were amazing.
Why We Switched from VMware to Bare Metal
Theoretically, virtualization makes for easier high availability and disaster recovery. In practice, there are some situations – like this one – where it doesn’t make sense.
In the event of a failure, 15-30 minutes of downtime were acceptable. The server was important, but not mission-critical. In the event of an outage, they didn’t mind manually failing over to a secondary server. This meant we could avoid the complexity of a failover cluster and shared storage.
Slow performance was not acceptable during normal production. They wanted to put the pedal to the metal and make an order-of-magnitude improvement in their processing speeds with as few code changes as possible.
They weren’t going to pay a lot for this muffler server. They’re a small company with no full time DBA and no glut of servers laying around. Buying a server was a big deal – we only had one shot to buy a server and get it right the first time. In this move, we were able to free up VMware licensing for other guests, too.
What We Designed: Dell R720 with Local SSDs
The Dell R720 is a 2-processor, 2-rack-unit server with room for 16 2.5″ drives across the front of the server, and two RAID controllers. It’s got room for up to 768GB of memory. It’s my favorite 2-processor SQL Server box at the moment.
I’m not against shared storage – I love it – but when I’m dealing with large batch jobs, a limited budget, and no clustering requirement, it’s tough to beat local SSDs. The R720 lets us use a big stack of 2.5″ solid state drives with two RAID controllers for processing data. Quantity is important here since affordable SSDs tend to be relatively small – 1TB or less. Some larger drives exist, like the Samsung 860 EVO 4TB, but bang-for-the-buck doesn’t quite match the 1TB-class yet.
The Dell R720XD is a similar server, but it’s absolutely slathered with drive bays, handling up to 26 2.5″ drives. While that sounds better – especially with today’s fastest SSD drives still being a little size-constrained – the R720XD only has one RAID controller instead of the R720’s two.
For our Plan B – where we’d fail over if the primary server died – we actually stuck with a virtual server. We built a small 2-vCPU, 8GB RAM guest with SQL Server. We keep it current using the database backups from the primary server. Remember, this application is batch-oriented, so we just need to run backups once a day after the batch completes, and then restore them on the secondary server. When disaster strikes, they can shut down the VMware guest, add more CPU and memory power to it, and it’s off and running as the new primary while they troubleshoot the physical box. It’s not as speedy as the primary physical box, but that’s a business decision – if they want full speed, they can easily add a second physical box later.
Picking Solid State Drives for the Database Server
When picking drives to populate the R720’s 16 bays, that’s where the tough decision comes in. You’ve got three options:
1. Use Dell-approved, Dell-sold drives. These are ridiculously, laughably, mind-bogglingly expensive given the size and performance:
A 400GB MLC drive is $1,200 rack, so filling all 16 bays would cost $19,200. To put things in perspective, the server itself is about $10k with 2 blazing fast quad-core CPUs, 384GB of memory, and spinners on the fans, so buying Dell’s SSDs triples the cost of the server.
2. Use commodity off-the-shelf SSD drives. In the latest Tom’s Hardware SSD Hierarchy (check page 2 to see the SATA results), pick high bang for the buck drives.
And it’s usually half the cost of the Dell drive, meaning we could fill the R720 with 8TB of smokin’ fast storage for a few thousand bucks, plus leave a couple of hot spares on the shelf.
There are risks with this approach – Dell won’t guarantee that their controller and their software will work correctly with this combination. For example, during our load testing, the DSM SA Data Manager service repeatedly stopped, and we couldn’t always use the Dell OpenManage GUI to build RAID arrays.
3. Ignore the drive bays, and use PCI Express cards. Drives from Intel and Plextor bypass the RAID controller altogether and can deliver even faster performance – but at the cost of higher prices, smaller space, and tougher management. You can’t take four of these drives and RAID 10 them together for more space, for example. (Although that’s starting to change with Windows 2012’s Storage Spaces, and I’m starting to see that deployed in the wild.)
For our design, we ended up with:
- Dell PowerEdge R720 with 2 quad-core CPUs, 384GB memory – $10k
- 16 1TB SSDs – $8k
- Hardware total: under $20k
- SQL Server Enterprise Edition licensing for 8 cores – $56k
Kinda keeps things in perspective, doesn’t it? The hardware seems insanely overpowered until you look at how much licensing costs. At that point, why wouldn’t you buy this kind of hardware?
Why I Load Test SSDs in RAID Arrays
The R720 has two separate RAID controllers, each of which can see 8 of the Samsung drives. The drawback of this server design is that you can’t make one big 16-drive RAID 10 array. That’s totally okay, though, because even just a couple of these race car drives can actually saturate one RAID controller.
I wanted to find out:
How few drives can we get away with? For future client projects, if we didn’t need to fill up the drive bays in order to get capacity, could we saturate the controllers with just, say, 4 drives instead of 8? Can we leave enough space to have hot spare drives? I run the performance tests with 2, 4, 6, and 8 SSD drives.
How much of a performance penalty do we pay for RAID 5? RAID 10 splits your drive capacity in half by storing two copies of everything. RAID 5 lets you store more data – especially important on limited-capacity solid state drives – but is notoriously slow on writes. (Thus, the Battle Against Any Raid Five.) But what if the drives are so fast that the controller is the bottleneck anyway?
Should we turn the controller caching on or off? RAID controllers have a very limited amount of memory (in our case, 1GB) that can be used to cache reads, writes, or both. In the past, I’ve seen SSD-equipped servers actually perform slower with the caching enabled because the caching logic wasn’t fast enough to keep up with the SSDs. Dell’s recent PowerEdge controllers are supposed to be able to keep up with today’s SSDs, but what’s the real story?
Does NTFS allocation unit size still matter? In my SQL Server setup checklist, I note that for most storage subsystems, drives should be formatted with 64K NTFS allocation units for maximum performance. Unfortunately, often we get called into client engagements where the drives are already formatted and the database server is live in production – but the NTFS allocation unit is just 4K, the default. To fix that, you have to reformat the drives – but how much of a difference will it make, and is it worth the downtime?
The answers to these questions change fast, and I need to check again about once a quarter. When I need to double-check again, and I’m working with a client on a new server build with all SSDs, I offer them a big discount if I can get remote access to the server for a couple of days.
Load Test Result Highlights
Turning off read caching didn’t affect performance. The controller’s small cache (1GB) just isn’t enough to help SQL Servers, which tend to cache most of their data in memory anyway. When we need to hit disk, especially for long sustained sequential reads, the controller’s minimal cache didn’t help – even with just 4 SSDs involved.
The controller’s write caching, however, did help. Write throughput almost tripled as opposed to having caching disabled. Interestingly, as long as write caching at the controller was enabled, it didn’t matter whether read caching was enabled or not – we saw the same benefit. I would expect higher write throughput if all of the 1GB of cache was available to cache writes, but that doesn’t appear to be the case with the R720’s controllers at least.
NTFS allocation unit size made no difference. This combination of RAID controller and drives is the honey badger of storage – it just don’t care. You can leave the default caching settings AND the default NTFS allocation unit size, and it’s still crazy fast.
In RAID 10, adding drives didn’t improve random performance. We got roughly the same random performance with 4 drives and 8 drives. Sequential read throughput improved about 35% – good, but maybe not worth the financial cost of doubling the number of drives. Sequential writes saw a big boost of about 60%, but keep in mind that sustained sequential writes is a fairly rare case for a database server. It’s unusual that we’re not doing *any* reads, and we’re writing our brains out in only one file.
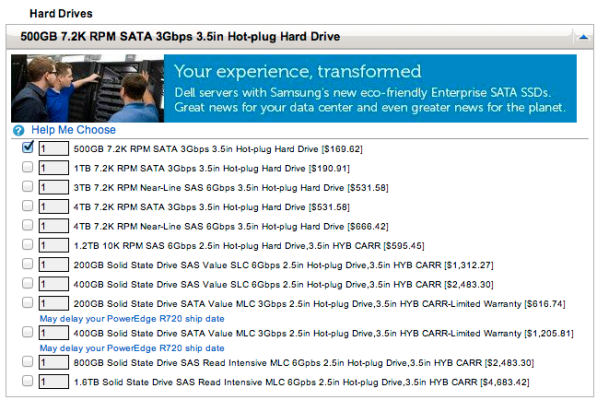
SSD speeds still can’t beat a RAMdrive. With SQL Server Standard Edition being confined to just 64GB of memory, some folks are choosing to install RAMdrive software to leverage that extra cheap memory left in the server. If your queries are spilling to TempDB because they need memory for sorts & joins, this approach might sound tempting. Microsoft’s even got an old knowledge base article about it. The dark side is that you’re installing another software driver on your system, and I always hate doing that on production systems. Just for giggles, I installed DataRam’s RAMdisk for comparison. The SSDs are on the left, RAMdisk on the right, and pay particular attention to the bottom row of results:
The bottom row, 4K operations with a queue depth of 32, is vaguely similar to heavy activity on multiple TempDB data files. This particular RAMdrive software manages about 4x more write throughput (and IOPs as well) than the RAID 10 array of 8 drives. (For the record, a RAID 0 array of 8 drives doesn’t beat the RAMdrive on random writes either.)
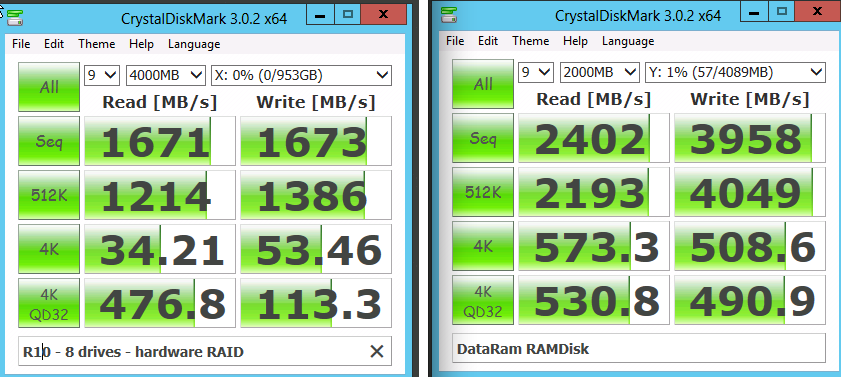
And finally, here’s the performance penalty for RAID 5. RAID 10 is on the left, 5 on the right. Same number of drives, same cache settings, same allocation unit settings:
It’s not a surprise that RAID 5 is faster for reads, but in this round of testing, it was even faster for sequential and large writes. The only place where RAID 5 takes a hit: the bottom right, 4K writes with queue depth 32.
If you’re running a Dell PowerEdge R720 loaded with Samsung 840 Pro SSDs, you’re probably better off with RAID 5 than RAID 10 – but why?
Load Test Lowlights: The Controller
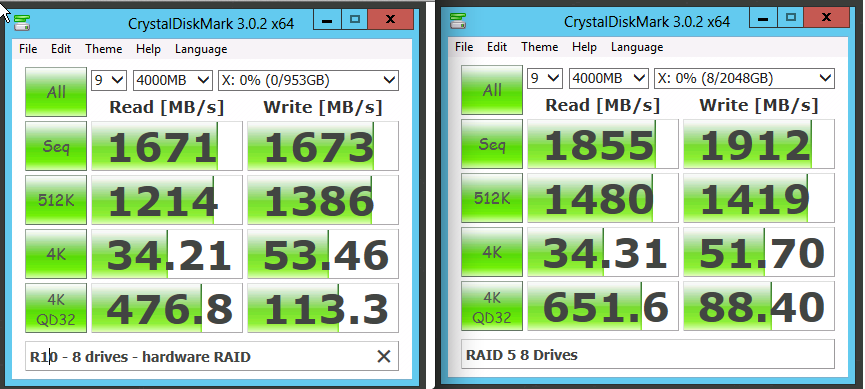
We’re not just testing the drives here – we’re also testing the RAID controller. To get a true picture, we have to run another test. On the left is a RAID 10 array with 8 drives. On the right, just one drive by itself:

The top two lines are sequential performance, and the RAID array helps out there as you would expect. Having more drives means more performance.
The jawdropper hits in the bottom half of the results – when dealing with small random operations, more drives may not be faster. In fact, the more drives you add, the slower writes get, because the controller has to manage a whole lot of writes across a whole bunch of drives.
See, we’re not just testing the drives – we’re testing the RAID controller too. It’s a little computer with its own processor, and it has to be able to keep up with the data we’re throwing at it. In the wrong conditions, when it’s sitting between a fast server and a fast set of solid state drives, this component becomes the bottleneck. This is why Dell recommends that if you’re going to fill the server with SSDs, and you want maximum performance, you need to use the R720 instead of the R720xd. Yes, the R720xd has more slots – but it only has one RAID controller, so you’re going to hit the controller’s performance ceiling fairly quickly. (In fact, the controller can’t even keep up with a single drive when doing random writes.)
This is why, when we’re building a new SQL Server, we want to test the bejeezus out of the drive configurations before we go live. In this particular scenario, for example, we did additional testing to find out whether we’d be better off having multiple different RAID arrays inside the same controller. Would two four-drive RAID 10 arrays striped together be faster than one eight-drive RAID 10 array? Would we be better off with a single RAID 1 for TempDB, and a big RAID 5 for everything else? Should we make four mirrored pairs, and then stripe them together in Windows?
You can’t take anything for granted, and you have to redo this testing frequently as new RAID controllers and new SSD controllers come out. In testing this particular server, for TempDB-style write patterns, a RAID 0 stripe of two drives was actually slower than a single drive by itself!
So as Jezza says on Top Gear, and on that bombshell, it’s time to end. Good night!

159 Comments. Leave new
Brent,
Great read, I did notice however, that in the second graph your setting differs, it says 2000MB, whereas all other graphs mention 4000MB. Not sure if that skewes the results…
Cheers,
Rick
Rick – great catch! That’s because the free version of that RAMdisk software only tops out at 4GB, and I didn’t want to hassle with checking to see if it ran into problems when the drive filled up. It shouldn’t affect the test on a RAM drive since there’s no caching involved.
Brent,
There may be a bad assumption here about the R720 hardware. We have a couple R720 servers that only have a single RAID controller (the PERC H710P Mini). I think you would have to specifically configure the server with two controllers, and I would imagine the option also exists for the R720XD
Ray – yep, you can check out Dell’s ordering pages for each model. The R720 can be ordered with an additional RAID controller, but not the R720XD. No need to imagine – you can go check for yourself now. 😉
The R720XD difference is the backplane, it’s one big unified thing rather than in the R720 where each bay of 8 has its own backplane on it. I think Ray is thinking of setups where each drive has a discrete cable from the controller to the drive, as far as “you should be able to get another controller”.
Sean – right, you can’t put an additional controller in the R720XD and split the drives into two sets of 8.
Did the Samsungs cause a warning in Open Manage and the Server Status LED because they’re not Dell supported? The Intel SSD’s we purchased don’t trigger that condition which makes it easier to detect faulty drives and they’re still significantly cheaper than the Dell drives.
I’m not sure about the server status LED, but they do trigger the yellow bang in OpenManage.
The drive lights themselves flash green, but the server’s LCD flashes orange because they are “unsupported” drives. Faulty drives are being detected through the iDRAC and the OpenManage platform.
I haven’t had a problem after updating the backplane firmware. Dell has been pretty cool about it lately on my R710’s. Looking at doing this in a VRTX soon myself.
i loved this statement: “The answers to these questions change fast, and I need to check again about once a quarter.”
to be in a position to do so would be a great problem to have, so thanks for sharing the detailed hardware luv with those of us who aren’t.
travis: which model intel drive?
Mike: We’re using Intel 710 Series SSD w/ Perc H700 in Dell r910. OMSA still reports a non-critical error but status light is healthy blue instead of amber. I can’t remember the condition of the drive status light.
In some other servers (including Dell 710,720 with perc H700’s & &710’s) we use Crucial M4’s and Edge Enterprise SSD’s but they report the same non-critical errors in OMSA; however they report faults in VMware and they create amber lights on the server. When the logs are cleared, the alarm returns after the server reboots. The moral is… use Intel drives.
I’ve found reports of other Intel models working without reporting errors, but your mileage may vary.
More info on the issue with reference to Samsung drives and Intel model 530
http://en.community.dell.com/support-forums/servers/f/906/t/19504074.aspx
If you know of alternative brands and models that don’t generate errors, please share.
The non critical error of your hard disks is because they are not ‘DELL’ hard disk.
Mike – thanks! It is indeed a fun problem to have.
A fascinating read Brent! I really enjoy hearing about real world consulting in action. Thanks for blogging the experience and sharing your insights.
John – you’re welcome! Thanks for stopping by, and congrats again on the MCM!
We have a RAID 5 with 4 x Intel 520 SSDs on an HP SmartArray P420i controller, testing with SQLIO I get max 1688 MB/s read, max 1344 MB/s write, max 133k IOPS — tests from Nov 2012.
Results here: https://gist.github.com/wqweto/6286203
wqw: I was hoping you’d say the 520. I don’t know HP as well as Dell, but do they “bark” at you that the “drives” are “unsupported” (i.e. are the lights green or not?)
brent: when you tested the single drive setup, was that setup as a single drive raid 0 still running through the raid controller, or were you somehow wired directly into the mobo and bypassing the raid controller altogether? i couldn’t tell from the 720 docs i found whether this was even possible, but i got the sense that all non-optical drives have to run through the perc. i’m sure everything running through the hot-swap backplane probably has to hit the perc, but a fella (or lady) could theoretically cable his way around this if he or she were so inclined.
Mike – the single drive test went through the RAID controller. I didn’t see a point in setting it up standalone since I can’t go into production that way, and there’s plenty of other tests on the web for this drive attached to various motherboards.
@Mike: LEDs are green, no warnings in Array Configuration Utility too. Only the SSD wear info is not working for some reason.
I’ve got the array 20% over-provisioned at the OS level (leaving 273GB out of 1341GB unpartitioned) but do plan to wipe/reset the SSDs when replacing the whole server or sooner :-))
“I offer them a big discount if I can get remote access to the server for a couple of days” ingenious. You should publish more of that. I’d be interested in SQL Server scalability to extreme numbers of cores for example (>=128). What workloads scale, which ones do not?
Tobi – thanks! I don’t publish these often because it’s a LOT of work on my part to put these together. I try to share as much as I can for free with the community, but I have to have that work life balance. This post took me a Saturday. 😉
You didn’t need that Saturday anyway… Be a man! 😉
Put a shopping cart link on the page… and you can keep the work life balance (as this could be considered paid work). I would click and buy a 20k server loaded with memory and drives ready for sql…
Brett – well, there’s plenty of resellers who can help with that, but we avoid the hardware reseller thing for now. The instant we start selling hardware, then we have to support it, and there goes the work life balance again. 😉 I’d rather not ever be on call again.
Brent, great article as always. I spend so much time with my clients on how to size servers and they just don’t seem to have a clue on how their own application will perform, much less the hardware. I use your blog posts a lot to highlight things when (especially developers) just scream for more cpu/ram without any idea why it will or won’t help.
Can you expand on the “why bare metal” option? Although at the edges bare metal vs virtual is faster, its not by much (certainly not the “orders of magnitude” you mentioned you needed to achieve). Your first two arguments I could use with virtual and physical, so it didn’t help. Was it just because they needed NEWER/FASTER hardware and the extra cost of a VMware license was too much? I know, there are options like the free hypervisor or hyper-v, but the first might be a support issue for the client and the latter is a whole new game if its their first/only hyper-v.
You could have gotten the same R720 and used the base ESXi and probably had nearly the same results, using local SSDs, etc.
I’m also wondering if they really needed SQL enterprise, at 56K I hope that was a requirement – certainly they could have saved a bundle there if they only needed standard.
Mike – what benefits would you gain by adding virtualization? Before you say HA or DR, make sure to read the project details again – virtualization couldn’t meet the needs.
About Enterprise Edition – you do realize Standard is capped at 64GB of memory, right?
Brent – regarding the 64GB limit, I did know that, but I was just guessing that memory was the reason (since you gave the server 384GB of ram). I assumed that you would have suggested standard straight away if they didn’t need that much 🙂
As far as adding virtualization, I’m not *too* worried about HA or DR, although I often think customers understate that need. Since I’m sitting here on the outside without knowing your client, its just guesswork. If they had 200 vms on 5 vsphere servers and practically no other physical hosts, the benefit of having this new server virtualized probably outweighs the minimal performance benefits of bare metal. You know, are they using Veeam or whatever VM backup/restore product, etc.
Not trying to argue, just wanted to understand. Of course for me 99% of my clients have small SQL servers in a highly virtualized environment (or do after they bring me in to get them virtualized!) but then they buy “product X from company Y” and this new product doesn’t support virtualization or understand anything about it, so the developers want a physical box, because they don’t care about backups, availability, DR, uptime, etc – other than to complain when its down/slow/has data loss!
Thanks as always!
Mike – actually, come back to the question. Why would you add virtualization into the mix? What’s the benefit that you’re suggesting here?
The funny thing is that a few years ago, I used to ask clients, “Why are you using bare metal for this? It’s a tiny server, it hardly ever does work, and it could share resources with other servers.”
Now, the pendulum has swung in the other direction – some companies aggressively virtualized everywhere, even where it didn’t make sense. Perfect example – huge server (larger than any other in-house server), all local solid state storage, with data that clears out and refreshes frequently. When you add the virtualization layer in, now you simply can’t patch it – you have no Plan B. You can’t move the guest somewhere else quickly, because it’s the biggest guest you have (by a long shot), bigger than any other host. You can’t use virtualization storage replication for HA/DR because the data changes too fast, and app-based backup/recovery is so much more efficient.
Glad to throw in some ideas here Brent. Again, without knowing some of the client details, these are just guesses….a lot “depends” on what else they have.
If the company was 100% virtual, my guess is they have a whole setup based on everything being virtual. backups, replications, snapshots, monitoring tools, etc. So having 1 server out there that’s physical now brings into play a host of new challenges.
Everyone always says “HA/DR isn’t really important” and then they need it one day, or the situation changes. I always giggle (internally) when a client says HA or DR isn’t important.
What I find interesting about your client is that this box isn’t critical, but its worth spending $100K on to make it go faster….yet if the box dies somehow, being on the “slow” box is ok.
Also you mentioned that this guest is the biggest guest you have and you can’t move it somewhere else. That sounds to me like when you provisioned the new server, you changed it significantly too (way more cpu, ram – not just the SSD). You said you couldn’t patch it. But you also said 15-30 minutes downtime was ok, so you’ve got a patch window.
Or was it just disk that was slow. So getting a dedicated san for the 100K you just spent might give you the best of both worlds, and you still have your failover-to-old-slow-storage for a DR solution (in the event the san dies).
I started out asking the question because I was reading your bare metal as a case for better performance.
Also there can be an added benefit here when it comes to replace the R720 with new hardware (but the SQL server is still fine), *OR* assume they make VM backups of the OS/app drives (but not the data) and they have a complete hardware meltdown. Rather then rebuild or go through other potentially painful processes, they can restore the last snap backup, restore the data (which they already do very well from what you said), and they are on their way. Again, so many *ifs* here.
When they need to patch SQL, they can use snapshots to recover quickly if something goes wrong, which they can’t do with BM.
These are sort of “throw it against the wall” sort of comments.
In the end, for me, it would come down to how the rest of their environment was. *IF* they were 100% virtual and *IF* they had developed tools/procedures/etc for utilizing that virtual hardware, I’d try to make this a standalone virtual server.
Mike – great comments! Here’s my thoughts:
“my guess is they have a whole setup based on everything being virtual. backups, replications, snapshots, monitoring tools, etc. So having 1 server out there that’s physical now brings into play a host of new challenges.”
Not really – for large multi-terabyte database servers (SQL, Oracle, etc), you don’t want to use conventional virtualization backup/snapshot tools for them anyway. Think about instances with a 250GB TempDB – you certainly don’t want to replicate or snap that.
“Everyone always says “HA/DR isn’t really important” and then they need it one day, or the situation changes. I always giggle (internally) when a client says HA or DR isn’t important.”
I didn’t say HA or DR wasn’t important, but I said that the HA/DR goals they have don’t match up with a VMware or Hyper-V solution. Remember that with VMware and Hyper-V, a single VM isn’t protected from Windows or SQL patch problems. You’re much better off having a separate machine already ready-to-go with the most recent backups.
“You said you couldn’t patch it. But you also said 15-30 minutes downtime was ok, so you’ve got a patch window.”
Nope – that’s a time window, but not a Plan B. If you patch the VMware host (firmware, BIOS, ESXi, etc) and it breaks, what’s the Plan B? You need a lot more than 15-30 minutes to recover from that.
“So getting a dedicated san for the 100K you just spent might give you the best of both worlds”
$100k is a lot of money in a scenario like this. Plus, keep in mind that you need switch gear, HBAs, rack space, and a part-time SAN administrator.
“Also there can be an added benefit here when it comes to replace the R720 with new hardware (but the SQL server is still fine)”
That assumes you want to use new hardware with an old version of Windows & SQL Server and not do any testing. Instead, when you do hardware refreshes, I strongly recommend laying down a new version of Windows & SQL Server, and then load testing your app on that. (As we’re doing here.) You wouldn’t buy a new car and put your old engine in it – why do the same with high performance database servers? Building out a Windows & SQL Server instance is something that a good sysadmin should be able to do in a day or two, tops, and the performance gains really pay off.
“When they need to patch SQL, they can use snapshots to recover quickly if something goes wrong, which they can’t do with BM.”
Even better: have two servers, and patch the standby first during regular weekday operations. Test it, know that it works, and then fail over to it with a few minutes of downtime. Patch the primary, test it, know that it works, and fail back to it with a few minutes of downtime. Suddenly all your patching is done during weekdays while the sysadmin is fully caffeinated and relaxed – rather than at Saturday night at 8PM when he’s stressed out and panicking. 😉
That’s why virtualization doesn’t bring any benefits here. Don’t get me wrong – it does in some scenarios – but not here.
I would disagree there is no benefit for virtualization here…..but this is one of those decisions that not only depends on having all the facts (and you have more than I do) but also which chair you sit in. You were brought in to solve a SQL problem. Tomorrow I’ll be brought in to solve their infrastructure problems related to other junk 🙂 I lean more towards virtualization as a general rule because I think it solves far more problems than it creates.
I’m not saying that there is never a situation not to virtualize. But I also think you’re talking an all or none here. For example:
“Think about instances with a 250GB TempDB – you certainly don’t want to replicate or snap that.”
You’re right. But in a virtual world I would snap/replicate the OS and the SQL install drives, not tempdb/data/log, on this multi-terabyte server.
“Remember that with VMware and Hyper-V, a single VM isn’t protected from Windows or SQL patch problems. You’re much better off having a separate machine already ready-to-go with the most recent backups.”
Of course…..you’re always better off that way. But if your DR system is a dog, does it really help? Now, if I blew up my sql server patching the OS or SQL, I could just revert to the snap, my data would be intact, and I’d be back in minutes. How long does it take to reinstall/restore/etc using a BM build/restore option (depends on how good the backup set up is).
“$100k is a lot of money in a scenario like this. Plus, keep in mind that you need switch gear, HBAs, rack space, and a part-time SAN administrator.”
They already had that. Or at least they already have some slower iSCSI san. I was saying get a faster iscsi SAN 🙂
“That assumes you want to use new hardware with an old version of Windows & SQL Server and not do any testing”
Testing on new hardware, of course. And in a perfect world, you always rebuild from scratch, latest version, etc. But to a large extent that is the beauty of the hypervisor – move your vm to new hardware and go to town.
“That’s why virtualization doesn’t bring any benefits here. Don’t get me wrong – it does in some scenarios – but not here.”
It sounds like I’m arguing, but I’m not trying to, although in reality that’s how we get really good setups in the end. What I *really* started asking was why not virtual, if it was just for the cost or what the real factors were. I think you have a scenario where you’re on the edge of where virtualization is an automatic, and from your seat/experience its not. For me, I’d make it work b/c that’s my generally value proposition. We’re both right, and we’re not really that far apart. In the best worlds you’d need to test, model, etc. Do they have 100 vms, 3 physical servers, and now 1 standalone physical box? Or do they have 100 vms, 3 physical servers, and 20 standalone physical systems that aren’t candidates.
Anyway keep on with the posts they are excellent
Mike – yep, I think we’ll have to agree to disagree here. Thanks for the feedback, though!
Brent – Thanks for the great post. I didn’t know about the memory cap for standard editions of SQL starting with 2008 R2. I guess that’s another reason to stick with 2008 Standard – no memory cap.
Also, the “base ESXi” probably wouldn’t have worked because of the 8vCPU limit.
Travis
for reference he only has eight cores on the server. The ram limit of 32 would be a problem. I was just giving an example. And hyperv would work.
I stand corrected. I didn’t follow the 32 GB limit unless it’s referencing former vSphere editions. I believe the recent vSphere version’s are unlimited by Ram. http://www.vmware.com/in/products/datacenter-virtualization/vsphere/compare-editions.html
The limits seemed like a detail that would be helpful to someone. I wasn’t trying to argue or enter the religious debate. You both made good points. It was helpful thought provoking dialogue for those of us who have to justify the ROI of virtual Db servers.
My final thought… We’re 99.5% virtual with the last 2 physical servers for SQL Db’s; but I’m not entering the debate. 😉
Your storage performance data was especially interesting. Is that where you stopped before going to production or before going to bed? It’d be great to hear about additional benchmarking before going to production.
Why use backups and restore instead of always-On?
Travis – AlwaysOn AGs have some serious administration challenges, and I’d only recommend it for companies with at least two full time DBAs.
We haven’t gone into production with this particular server yet – I do additional benchmarking and load testing around SQL Server maintenance tasks, application tasks, etc. It takes a lot of work to do that kind of blog post, though, so I don’t publicize those. (It took me a day to put this post together, heh!)
Thanks for the post and dialogue. The time you put in is obvious and much appreciated. I’ve consistently absorbed your material as part of my professional development diet for a long time and I’m not a DBA (Ops guy).
I thought you might reveal additional data about your more sophisticated benchmarking methods. I was more interested in the method than the results of this server and drive combo. Fortunately, I found your other blog after a couple minutes of searching and I’m somewhat surprised you didn’t reference it or your other related posts because it clearly explains the method and gives some context…
“I use CrystalDiskMark as a fast “easy button” for people to do quick throughput testing, and then if time allows, I use SQLIO to do much more in-depth testing” by Brent Ozar @ https://www.brentozar.com/archive/2012/03/how-fast-your-san-or-how-slow/
Cool, glad you enjoyed that post. I’ve actually got lots of posts on storage testing, pathing, SSDs, and more. Feel free to use the Search box at the top left to search for topics you’re interested in. With over ten years of blogging, it’s tough to link back to every post, every time. 😉
HI Brent,
Can you please elaborate more on the following statement
“AlwaysOn AGs have some serious administration challenges, and I’d only recommend it for companies with at least two full time DBAs.”
Thanks
Manish
Manish – sure, check out our AlwaysOn resources page at https://www.brentozar.com/go/alwayson
Brent,
Thanks for a very informative blog post.
I’ve got a few R720s and it never crossed my mind that RAID5 SSDs could ever be (almost) as good as RAID10.
Controller caching/NTFS allocation – excellent questions answered.
Keep up the good work!
Brent,
Thanks for the post. Any concerns about lifetime of the drives? It has been awhile since I’ve done my homework on consumer grade SSD’s, but don’t they have a tendency to die relatively quickly in high write environments? I’ve been considering something similar at our organization, we do nightly batch runs as well, and am concerned about drive failure, or that the failures might occur over a small time frame. Any thoughts? Have things improved to where MTBF isn’t as much of an issue?
Andrew – well, the way I look at it is that any drive – magnetic or SSD – is going to fail. If we have to replace $10k worth of SSDs every year, and we keep getting faster performance every year as a result, and it’s always way faster than a SAN, then it’s a slam-dunk no-brainer.
As someone who has lost critical data from a RAID 5 disk group losing 2 disks in a relatively short period, I can’t recommend anyone using RAID 5… especially with cheap, off the shelf SSD drives. YMMV…
Wade – so are you saying a RAID 10 array can’t go down when you lose 2 drives? Think carefully on this one….
RAID10 can take the “right” two drives failing without losing data or speed. The reason RAID5 is considered more dangerous is when a mechanical drive fails, the stress of the other components may lead to another failed disk. Also rebuilding RAID5 takes way more time, so you get more vounerable for a longer time even if you have a hotspare available (this is true at least with mechanical drives). IMO hotspare + frequent backup is the way to go regardless of RAID type.
David – yep, if you’re still using mechanical drives (spinning rusty magnetic frisbees) for critical data in 2019, well…God be with ya.
Hi,
How in the end did you configure your drives and where did you place everything (tempdb, system dbs, user dbs)?
thanks,
Ben
First off – thanks for this wonderful site.
I’m primarily a sysadmin, and have been for quite a while. I’m slowly starting to learn bits and pieces about SQL server.
That being said, there are a few things about this article that I feel isn’t quite right..
– Any kind of parity RAID (3,5,6,50,60 etc) on SSD’s is begging for trouble. Each RAID5 write adds a second parity write. With RAID6 you get one data write and TWO parity writes. Considering how SSDs have a much lover MTBF when it comes to writes it’s needless to explain any further..
– Consumer grade SSDs have a much much lower MTBF and lifetime in general than enterprise SSDs. This varies a lot between different products, but using anything other than eMLC or SLC in write-intenstive database scenarious is not something I would recommend.
– Using consumer disks behind a RAID controller makes you unable to upgrade firmware on them. The only way to do it is to shut down the server, remove the disk(s), plug it in something else and then upgrade firmware. Not something you would want to do against a production system, as the downtime would be much, much longer than the 15-30 minutes you mention in this article, unless you have a specialized setup where you can easily connect 16 SAS devices at once. Maybe you don’t have to upgrade the firmware at all, but nearly every consumer grade SSD I’ve tried needs a firmware upgrade at some point to resolve critical bugs in the on-disk controller software.
Like I said, I’m not expert with SQL, but I’m thinking that this customer probably doesn’t need 4TB of SSD. An alternative solution could be to use a few eMLC or SLC enterprise SSD’s for the most heavily loaded parts, and use HDD’s in conjunction with SSD cache that the Dell controllers support (http://www.lsi.com/products/storagesw/Pages/MegaRAIDCacheCadeSoftware2-0.aspx and https://www.google.no/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&ved=0CC4QFjAA&url=http%3A%2F%2Fwww.dell.com%2Fdownloads%2Fglobal%2Fproducts%2Fpedge%2Fen%2Fperc-h700-cachecade.pdf&ei=0NgdUoHtIcmE4ATPgoDQAw&usg=AFQjCNEPq3AHRM4KSd5Oju0e0abeSgk7tw&sig2=AbYfaT3NjYwLySqTS5hJ8w). This would be a much safer option than consumer gear.
I know and understand that there are budget constraints here, but like you said – if you’re already shelfing out for 8 enterprise cores then there really shouldn’t be any excuse to use consumer hardware in a critical production system.
Hi, Eric. Keep up with the learning on SQL Server, and a lot of the answers will become more clear. You’re on a great start already by reading blog posts!
The customer actually does need 4TB of SSD. They currently have 1.5TB of data, and they’re projecting to double that in the next year. Due to the application design, they have to erase and reload the entire dataset periodically. (Not a bug in the design – this is a somewhat common use case for people who need to do analytics on new datasets frequently.) They have a limited time window to dump & reload it, but they can take fairly long outage windows when they’re not doing analytics. Because of that, they’re completely comfortable upgrading the firmware on the drives during outages.
When you say you wouldn’t use anything other than SLC in write-intensive database scenarios, that’s totally fair from a systems administration point of view, but you might be surprised at the real-life success stories that are happening these days. Businesses are sometimes totally fine with replacing $10k worth of SSDs once per year to get the latest-and-greatest performance.
Thanks again for the comment though!
Brent,
Thanks for the reply. I do understand that they are perfectly willing to replace the SSD’s every year for $10k, but that does also imply that the SSD’s haven’t failed yet.
One thing I didn’t mention is that consumer-grade disks (HDD, SSD) are usually bought in one large batch from a supplier, who also bought it in one large batch. This probably means that all your SSD’s are from the same production batch, which means that they would all fail nearly at the same time if you hit a bug or a hardware error. Combine this with the double writes of RAID 5, and you’re very close to a URE (Unrecoverable Read Error), where you’ve ended up in a situation where another disk failes while a parity rebuild is in progress.
In addition to the dangers of URE, you additionally have no chance of actually measure the lifetime of the SSD’s since the RAID controller doesn’t comply with the disks.
I’m not saying it won’t work, but I need to emphasize that setups like these needs _very_ good plans for disaster recovery.
Erik – hmm, are you saying that enterprise drives aren’t susceptible to the exact same problem? After all, they’re purchased in one large batch from the same supplier.
Just out of curiosity I tried to do a quick and dirty comparison of expected lifetimes of the drives. I realize that once you account for various raid levels and the additional writes required for those that it would skew the numbers fairly heavily in terms of actual lifetime, but this gives a decent baseline (assuming the math is right).
https://docs.google.com/file/d/0B6WeEpxpNxBzTTc4SmdsbUNMODA/edit?usp=sharing
Resources:
http://www.ubergizmo.com/2013/05/samsung-840-pro-review-256gb/
http://www.dell.com/downloads/global/products/pvaul/en/solid-state-drive-faq-us.pdf
http://www.dell.com/downloads/global/products/pvaul/en/enterprise-hdd-sdd-specification.pdf
Well – buying from an online store doesn’t guarantee anything, but larger enterprise-oriented storage suppliers buy disks in batches and then make sure that customers doesn’t get all their disks from one batch.
Probably more expensive than online shopping though!
Erik – that has not been my experience with enterprise server vendors, but I’m glad they’re taking care of you at least.
Hi Erik – Modern day consumer grade SSD (Samsung EVO 850), for a 512GB drive, the write limit is 150TB. The PRO drive endurance limit is 300TB for a 512GB drive. To completely fill up the write limit on the EVO 850 (non pro), you need to write 82GB everyday, 7 days a week, for a few years. Hardware is so commodity these days. The trend (see Openstack) is to buy cheap hardware but have a ton of them. The industry trend is moving away from enterprise and go commodity.
And upcoming SSDs simply blow that out of the water. Check out Intel’s upcoming Optane lineup:
https://arstechnica.com/information-technology/2017/02/specs-for-first-intel-3d-xpoint-ssd-so-so-transfer-speed-awesome-random-io/
“Intel’s 400GB SSD has a lifetime rating of 7.3 petabytes written, or 10 full drive writes per day. The 250GB Samsung has a warranty that covers only 0.1PB of writes over the drive’s lifetime, about 0.1 full drive writes per day. This highlights one of the big differences between enterprise and consumer hardware. The 375GB Optane drive bumps the lifetime rating up to 12.3PB written, or 30 full drive writes per day. As such, the 3D XPoint drive should be much more robust under heavy write workloads.”
TechReport has an article on actual observed endurance life of different SSD drives, including 840 Pro. Maybe that’s something worth looking into it.
Have you considered using/benchmarking different RAID controllers?
Have you considered using different RAM disk product? From what I see DataRam’s RAMdisk is slightly below the middle of the road.
When you are talking about Samsung SSDs, 840 is different from 840 Pro(which is different from 840 EVO) so it’s very important to clearly differentiate between them.
Interestingly enough, there’s a post on somewhat similar subject http://highscalability.com/blog/2013/9/4/wide-fast-sata-the-recipe-for-hot-performance.html
Nice find! Looks like they’re getting around it by ignoring the RAID controller altogether and doing the RAID in software. Interesting approach.
So, we did something similar to you with our R720s. Thing is, this stack of machines is racked in a facility four states away from us, so we’re counting on Dell’s pro support to go fix the machines if anything fails. Consequently, we had to buy Dell SSDs but buying enterprise SAS SSDs was, as you noticed, very cost prohibitive. In the end, since we were buying 24 machines we spoke to a dell sales rep who sold us Dell enterprise MLC SATA SSDs with part number DYW42. I can’t recall the exact price per drive, but it was less than $300 per drive. They’re rebranded Samsung SM825’s (MZ-5EA) drives.
Incidentally, our use scenario is rather strangely unique in that we dont have a lot of data to move around but we’d like the lowest practical latency. So, we ended up with eight 100GB SSDs per machine. Ended up making them a RAID5 w/ a hotspare.
I’m writing because, for us, we’re not worried about wearing out the SSDs. If they wear out, we call Dell, they’ll send someone to the datacenter and swap em out for us. Nevertheless, I’ve been tracking the smart attributes. The machines were delivered and installed 11 months ago and have been production/live for 9. Currently, the SSDs are showing between 70 to 94% health remaining. We have not had any failures yet nor have we had any of them replaced.
Also, as an aside, I was impressed to see the built-in PERC h710p (a rebranded lsi megaraid) recover the array to the hotspare in less than 10 minutes.
Incidentally, the most amazing part about these R720s to me were how quiet they were and how little power they consume.
Thanks for the comment and sharing your experiences.
Hi, following up on Ben’s question – do you have advice on separating data and log files as well as the temp db into separate RAIDs? Is it worth it, or with SSD’s is it just not as important and everything can stay on the same RAID?
Hi Chris. Go ahead and check out this post: https://www.brentozar.com/archive/2009/02/when-should-you-put-data-and-logs-on-the-same-drive/
What specific RAID Controller was used for this test? I notice several options on the Dell site. You seem to imply you’ve used Dual PERC H710P controllers, I just want to confirm explicitely that is the case. If so, Do your RAID 5 and RAID 10 benchmarks test arrays that spanned both controllers? (if that’s even possible).
Great article. I love both the results, and the explanation of methodology and reasoning why to do these specific tests. Thanks!
I’ve been considering the exact same server (albiet with overpriced Dell supported SSD’s), but need to try to spec it perfectly before I have it in my hands to benchmark. So your hands-on testing is very timely and informative. Thanks for sharing.
Paul – I don’t have the server results with me at the moment, but we maxed out the best RAID controllers we could get from Dell in that model, and I want to say they were 710s. We did indeed do benchmarks that spanned both controllers using striping at the OS level, although that’s not something I’d widely recommend. Glad you enjoyed the post!
Great post Brant! Also lots of helpful comments with other experiences. We are looking to move to a new server and your build here matches the config I would like to go with myself. I’m still a bit nervous about going with consumer grade SSDs but when all the pros and cons are weighed up the cost benefit is hard to ignore.
If you use the Samsung Drives and the dell controller tells you their unsupported – Do you still get notification’s that you had a drive failure?
Have you Tried using a real LSI 2208 with the Samsung’s are the drives supported then?
What about using Intel S3500 SSD’s Wouldn’t these be supported on the dell?
is the Samsung’s 840Pro that mush faster than the Intel’s S5300?
Hi Dan. These are a lot of great questions, and unfortunately, I can’t really do justice to them in a blog comment. If you’re building a new server, I’d encourage you to do those investigations yourself with the newest versions of hardware, RAID controllers, and SSDs to get the performance you need. I wouldn’t recommend anyone reuse my advice months later – SSDs, firmware, all this stuff changes.
When you mention the old setup, it’s very clear that neither VMware, nor virtualization is the problem. Saying you have an “iSCSI SAN” means nothing when you are talking about performance. Vendors will try to sell you “An awesome 18 TB iSCSI SAN” that in reality can only push 2000 iops over easy to overload 1GB connections. There are a whole series of ways to bottleneck iSCSI and the appropriate course of action is to find where the bottleneck is and eliminate it. Adding another physical server is a band aid for what is probably a larger infrastructure problem.
By switching back to physical you have just undermined this company’s ability to fully utilize their hardware, as well as eliminate all the other benefits of virtualization, like portability and vmware ha. Now they will have a disk powerhouse whose cpus are lightly touched, and they will need to buy more unwarrantable servers that are harder to maintain and recover in order to grow. There are all flash iSCSI storage appliances that will achieve much better ROI as well as the next generation of dell compellent offers usable storage that writes initially on a smaller MLC tier and migrates to SLC tier for reads improving both throughput and endurance, while maintaining 2TB of change data per day or more.
I’m glad I’m not this company’s sys admin. It’s a disturbing trend that the industry keeps shrinking the staff that implement and maintain their companies infrastructure and also encourages difficult to support one-off solutions like this.
Paul – thanks for the comment. I wanted to clarify a couple of things:
“Adding another physical server is a band aid for what is probably a larger infrastructure problem.” – Yep, agreed. While I wish that I could fix larger infrastructure problems, sometimes that isn’t the solution that the client can afford. In this case, they were in a colo environment and couldn’t afford to replace the two core switch networks with 10Gb switches. The network was performing adequately for the rest of the servers, but wasn’t equipped to handle high throughput SQL Server data warehousing.
“eliminate all the other benefits of virtualization, like portability and vmware ha.” – This client didn’t need either of those benefits. I do like both of those benefits a lot, generally speaking, but as I wrote in the post, they weren’t a requirement for this particular server. Performance was.
“Now they will have a disk powerhouse whose cpus are lightly touched” – Don’t be so sure, actually. They’re doing process benchmarking as we speak, and they’re working the CPUs out.
“they will need to buy more unwarrantable servers that are harder to maintain and recover in order to grow” – If you mean grow databases, that’s not the case. They’ve got the headroom they need on this particular box. If you’re talking about growing other app servers, they’ll continue to invest in VMware for those needs.
“There are all flash iSCSI storage appliances that will achieve much better ROI” – Absolutely, but they’ll need 10Gb switch gear in order to work. When you factor in the storage appliances and two 10Gb switches for redundancy, you’re talking about a dramatically more expensive project. Now, if they were going to reuse that same storage for their virtual app servers, I’d agree with you – but their existing 1Gb iSCSI gear worked fine for the rest of their virtualization needs.
“as well as the next generation of dell compellent” – Yep, again, up against the pricing issue here. I’m not aware of a way to get the current Compellent lineup for $10k-$15k, but I’d certainly love to hear about that.
“I’m glad I’m not this company’s sys admin.” – There’s one spot where you and I agree. Thanks for the comment though!
Dan, Brent,
Samsung 840Pro generally performs better than Intel S3500 (which is the cheapo-brother of enterprise grade S3700 as we all know). We all undestand performance is extremely complicated with SSDs as there are tons of different tests, workloads etc and there is no direct correlation between consumer grade tests like ATTO and enterprise-grade tests which directly empower OLTP, webserver, sQL, data-mining techniques and real applications built on Oracle or Microsoft SQL basis.
Enteprise-class disks are not about performance PRIMARILY, the most differentiating factor is their ENDURANCE and the second most important is PERFORMANCE CONSISTENCY over time.
It’s common to see consumer SSDs do 80.000 IOPS (4k random) which heavily outperforms much more expensive enterprise SSDs which usually do around 15000 to 40000 IOPS, but consumer SSDs can NOT sustain that performance over time. I don’t speak months here, I speak MINUTES only. After some minutes, write performance of Samsung 840Pro can EASILY drop below 5000 IOPS (five thousand) down to approx. 1000 (one thousand) only. You don’t believe me ? Check any serious review (tweaktown.com, anandtech.com, tomshardware.com) and performance consistency graph, you will immediately notice what’s the thing separating boys from men.
Granted, when you have 8 or 16 such SSDs working in parallel, you are less likely to hit this saturation point. The more data you have, the worse.
Yes for sure, you also pay extra for brand, ENTERPRISE-GRADE FIRMWARE [!!!!] and enteprise-grade compatibility. As said, Dell RAID might incorrectly identify Samsung SSD and not provide their health status among other things, but there is no such problem with Intel drives. Dell, HP, IBM, SuperMicro, LSI, Areca, Adaptec, you name them all, everyone cooperates with Intel and wants to be as compatible as possible. That’s what Intel brings. Right.
Check serious reviews of Seagate 600, compare to Seagate 600 Pro for example here : http://www.tweaktown.com/reviews/5455/seagate-600-pro-enterprise-ssd-review/index.html and you will understand the difference. More overprovisioning, careful choice of NAND chips provides much better life (approx. 3x more) for the Pro version over the basic one which is still an order better than consumer SSDs. Usually there is something on the edge of 70TB written (around 40 to 50GB/day for 5 years) lifespan for consumer disks, Seagate 600 provides 350TB in the basic capacity, 600Pro nets more than 1000TB. That is really an magnitude of difference.
And that alone is still much less [!!!] than Intel S3700 guarantees. They speak about 3500TB guaranteed writes. Ouch.
That’s the difference. Yes, the price is extraordinary. Yes, there are businesses which can shell out $10k/year to replace SSDs and can tolerate some downtime. They saved dozens of hours until the lowish-grade array fails prematurely (IF !!), they can probably sustain two hours to recover. Some businesses are not like that. Some are. That’s the market. Different needs, different budgets.
I somehow tend to agree with Mike and his speach about virtualization, but that’s because I’m vmware-geek so I’m not objective here. I would personally try to spend the budget which was very nice to create better virtualized environment than building stand-alone host. No beating the dead horse here, we really do not have any major business/technical details to perform educated decision.
If I had the opportunity, I would like to build up my own SSD RAID based setup, with different software/hardware raids, local and remote over iscsi/fcoe/infiniband infrastructure. Different software will be used, windows2012 and linux (centos/nas4free/freenas) solutions, and thoroughly compared with REAL sql performance on real data sets. My preliminary experience so far is that – contrary to what most believe – software based RAID is actually MUCH FASTER than hardware based controllers. It is caused by using several different paths to storage (yes, 6Gbit SATA/SAS is the limit), much higher raw performance of current CPUs compared to what RAID controllers have. For example, I’m easily pushing 2GB/s from SSDs sequential read/write on my local computer with 4k random IOPS spiking over 300.000 IOPS and that’s nowhere near xeon e5/e7 CPUs with CPU not being the bottleneck at all !!
Yeah, storage is extremely complicated (what’s not today?). Thanks for posting your results, Brent, I know it has been a lot of work to get them.
Regarding your claim that consumer SSDs are provisioned for 70TB write endurance, see http://techreport.com/review/25559/the-ssd-endurance-experiment-200tb-update
Brent,
Are there any hard drive controller alternatives to the Dell PERC that are optimized for SSDs (larger cache, etc)? We currently have an R815 with PERC H700 with six 960gb SSDs but am getting terrible read/write performance.
VM – Yes, but that’s not something I’m really prepared to blog about at this time. It takes a lot of work to do justice to that kind of topic.
I agree with the comments by Lubomir on the DC S3500 and Seagate SSD Pro 600. These two SSD’s are good value when you consider they are only 50% more than consumer level SSD’s.For example the 480GB models are around $600ea. Whilst they are not in the same class as “true enterprise” SAS SLC write intensive drives they are at least a drive that the drive that the manufacturer (drive manufacturer) has tested in a server-use scenario. Its also interesting to note that Dell’s pricing is very good on the SLC drives compared to buying them on the open market so its really just with these new aggressively priced entry level drives that they are not on-board with (and possibly for good reason).
If you look at the endurance test on the techreport you will also see that the Neutron GTX is actually a very similar drive to the 600 Pro and so far the 240GB drive has survived 600TB written with great consistency. The 600 Pro of course has enterprise firmware and a super capacitor to protect against data loss (corruption from incomplete writes) with power failure. Due to its price being so close to consumer drives in fact I have fitted a few to PC’s and laptops with great results. The LAMD drives also don’t slow down when near full either.
If its a server for internal testing and it has to be a consumer SSD (ie you have no concerns about loosing data or having super capacitors) then this is a very interesting option (I expect this will also start turning up in business desktops and laptops)
http://www.tomshardware.com/reviews/sandisk-x210-ssd-review,3648-13.html – The pricing is less than the 840 Pro
Also in the point made about using software raid I think part of this comes down to the fact that SSD’s already have a raid controller (of sorts) in them and at the moment the industry is moving towards PCIe based storage and sata express as the the current interfaces were designed more with mechanical disks in mind. Dell have also address the issue of the PCIe cards being so expensive by offering some more options. The most interesting new option on the PowerEdge range is this.
http://www.micron.com/products/solid-state-storage/enterprise-pcie-ssd/p420m-ssd
The 1.4TB models are starting to become affordable and you could always buy two and present them as one volume in the latest versions of Windows Server.
I agree with Brents comments on using a San and virtualisation, having dealt with environments using SAN’s without 10GE you just end up with bottlenecks. The best results I have seen have been with decent hosts like 720’s with lots of built-in storage (eg if you use 8x 600GB 10K drives in a raid5 or 6 array the performance is very decent with the 1GB cache H710 controllers). Or if you go down the SAN route then make sure you have the Compelants with the tiered storage and 10GE (aggregated for 40Gbit) on both the network and SAN side (set-up using VLANs). It is somewhat frustrating at the moment that Dell don’t offer something in between using 10 or 15K mechanical drives and the expensive SSD options. Its slowly been getting better however they have a * limited warranty on the SATA drives which is only three years when the entry level DC S3500 and 600 pro drives have a 5yr warranty when purchased direct – I do however agree with a max TBW clause for these cheaper drives as the manufacturers sell them as a entry level server SSD for read intensive applications. I am sure with the right firmware update it would be easy enough for the raid controller to pick this up from the drive and log it within OMSA.
Don’t you lose TRIM support by putting SSDs in a RAID array? Will this impact your performance an time goes on and your drives are filled?
Dave – yes, you lose TRIM support, but the performance impact varies by the SSD. Some drives don’t need TRIM as much, and if you go by the hardware links I put in the review, you’ll see which ones are less affected. For example, at StackOverflow, we ran with the same Intel SSDs for about 2 years without any performance degradations.
A little bit somewhat inaccurate. 🙂
See https://serverfault.com/questions/227918/possible-to-get-ssd-trim-discard-working-on-ext4-lvm-software-raid-in-linu
Apparently recent versions of Linux kernel support passing TRIM to software raid setup.
Mxx – actually, the inaccuracy is yours. 😉 Note that this article talks about hardware RAID, not Linux’s software RAID. Thanks for stopping by, though.
Brent,
I literally have a server spec’d out just like yours: Dell R720, 128GB RAM, dual RAID controllers. I plan to use 4 of the 960GB Crucial M500 SSDs in a RAID 10 array. Is this one of the SSDs that will do okay without TRIM? That is my biggest concern before I build this SQL Server 2012 box.
John – rather than asking an individual blogger, you’re best off checking the reviews for the drive you’re using.
Thanks for the quick reply!
Brent,
One more question: Did the SSDs snap into the brackets properly? Just concerned that they won’t mount in the chassis the same way a mechanical 2.5″ drive would.
Thanks!
John – sorry, can’t tell you there. I don’t get hands-on with that kind of thing anymore – I work from home, and other folks rack the servers.
John, they should all fit. Some SSDs might be slightly thinner, but screw holes should match to standard 2.5″ specs. See https://en.wikipedia.org/wiki/Hard_disk_drive#Form_factors
Hi Brent, first of all, once again for the awesomeness on Lisbon workshop and presentation.
When talking about SSD’s on PCI cards you mentioned:
You can’t take four of these drives and RAID 10 them together for more space, for example. (Although that’s starting to change with Windows 2012?s Storage Spaces, and I’m starting to see that deployed in the wild.)
Can you pinpoint where to look more information on this option? Or at least where to start. I can’t find it 🙁
Thanks, glad you liked the course! Windows Server doesn’t support software RAID 10 without Storage Spaces. There’s no option because it just doesn’t exist. 😀 Hope that helps!
Yes, it clearly answers it, thx.
Hi again, one more question. I guess it depends on my SLA with my hardware vendor, but I prefer to ask just in case. What about warranty (with Dell, for example, as in StackOverflow case) when installing SSD’s or any other drive not supplied by Dell? Will this void the warranty? Thanks!
Right, check with your vendor.
Well, it seems that the Samsung 840 Pro’s 512 meg of cache really kicks in when using it as a single drive RAID set. Also I wonder if you used 2 retail LSI cards if you can span your RAID set so that you can 16 lanes on your server? I have seen the LSI RAID cards saturate an 8 lane PCIe 2.0 bus in RAID 0 and RAID 10 with just 4 512 gig Samsun 840 Pro’s. On the Virtual Server front if you were using VMware ESX 5.5 and 2 TB of SSD Read cache you should be able to sVMotion that host from SAN to DAS before the workload times. As I recall 5.5 also uses the Host RAM as disk cache. For the R720’s you would have to make sure the SAN and RAID cards are negotiating PCIe 3.0 and not falling back to 2.0. I am not sure that the chipset has ever been tested with that kind of IO from 2 PCIe 3.0 8 lane RAID cards with SSD’s in them. Just the I/O of a few Samsung 840 Pros can overheat the CPU on the lesser brand RAID cards.
Joe – we were using Dell’s RAID cards. About the virtualization – yes, true but only I you had a VMware host with local SSDs, which this company didn’t. Thanks!
Wow! Extremely helpful post! Thank you for posting and to everyone for your insightful comments!
I’m about to replace all 8 of the 300Gb 10K drives that came with our R720 with 8 750Gb 840 EVO’s. At first I was a little skeptical about using consumer SSDs – but after reading this I feel confident that it will all workout just fine.
The only question I have is this: With 1,100+ P/E Cycle’s, are we really concerned that these drives will fail after just a year of operation?
I’m still learning about SQL servers, so I’m sure I’m missing something here. But 240+ TBs of writes seems like a lot to consume in just one year. Especially when your spreading the load over 4 or 8 drives. Am I wrong?
For the record, the R720 we’re about to upgrade is a Citrix VDI server. Not a SQL Server. So the concern over write endurance might not be as profound on a server running virtual desktops as a server running a database.
Thanks again for such a wonderful article. I know it takes a lot to put these things together, but the internet appreciates it 😀
Alexander – if you’re asking if hardware fail at some point, the answer is yes.
If you’re asking me if I know the exact date/time your hardware will fail, the answer is no. 😉
The article I mentioned in my earlier comment had an update http://techreport.com/review/26058/the-ssd-endurance-experiment-data-retention-after-600tb
Look how much worse TLC drive faired against MLC…
Mxx – what’s your question for me?
Brent, it was for Alexander to look at longevity of TLC drives.
Thank you Mxx!
You defiantly can’t pin point an exact date for any drives demise. But with those performance tests ill at least know when I should start getting worried, and to be honest… that’s all I really care about. As long as I can see the pending doom I can plan for it accordingly.
My concern was with the comments about the drives needing to be replaced every year. To me that didn’t make sense because of the high P/E Cycles for the drives in question. Granted they’re not anywhere near as high as their enterprise brethren. But to me they’re high enough that the drives should last far beyond just one measly year. I think the performance review you posted backs that up even further.
I was just wondering if I had missed something here. A factor that I wasn’t aware of that could cause these drives to die so quickly.
For me, even if the drives only last up to their rated 240TBs of writes, that’s still going to take an awful long time to hit it (at least 3 to 5 years). That’s an acceptable life span for only $2,900.00 in SSDs
I would not use EVO drives, use Samsung Pro. The cost difference is small but the endurance difference is large.
Mike – do you have any evidence to point to?
Brent — Do you know of any other brand/model besides Intel’s 530 Series that do not cause OMSA to report ‘non-critical’ warnings?
Arun – the Intel enterprise series usually doesn’t, but you’ll want to try buying single ones of your chosen drives, put them into your server, and see how they interact with the current version of your RAID controller firmware and OMSA. Dell’s been more lenient lately with more and more drives not triggering the warnings.
Thanks for the prompt response Brent!! We work on limited budgets so I don’t enjoy the privilege to experiment much. We have an immediate need to source a few SSDs (ideally that are <$350 per piece) which are compatible with Dell PowerEdge R720xd server with PERC H710p controller.
Our workloads typically include OLTP transactions. Can you please suggest something that might work for our setup?
Then buy one and see if it works. If it doesn’t, return it. 😀
I bought a bunch of Intel 530’s a built a server with 100% SSDs (including OS). Created three RAID volumes (one RAID-1 and two RAID-5s).
I used them on DELL R720xd and they worked like a charm. The non-critical errors do show up, but I can live with them.
Just wanted to add a note that Ramdisk appears to perform worse than SSD in virtualized environments (at least in AWS).
Craig – yep, the whole nature of virtualization means that you could be on wildly different host hardware at any given time. It’s impossible to make blanket generalizations like that, even in a vendor like AWS, because they have multiple host types with different performance (both different memory and different SSDs.)
Hi guys,
After reading this post and a few others I thought I would jump in and try it.
I got my 2.5″ caddies off ebay as Dell parts were so inept I could get them quicker that way (they could be copies, but they appear well made) by months.
I bought one drive as suggested to see how things would go. In my case I bought a Intel 530 Series 120GB SSD.
The part number on the box appears to be – SSDSC2BW120A401
The controller recognised the drive straight away and all lights functioned correctly. In my case the controller is an Perc H710P mini (firmware 21.2.0-0007).
I was able to create a RAID0 drive no issues (it is only one drive after all).
The DRAC shows everything as green and shows both the physical and virtual disks as I would expect them.
Plus Linux version I am running sees the new drive. I have not created any partitions etc as yet.
This is all in a Dell R720 BIOS version 2.1.2. The LCD panel is blue and shows no errors etc
The only annoying thing is that Dell OpenManage has got a nice Yellow Exclamation mark for this server now.
Which I kind of expected……….but this SSD is so much cheaper that what Dell is offering…….
Cheers
Cool, glad you liked it! SSDs are awesome.
I have an adaptec 5805 raid card with 8 x Seagate Cheetah 15K.5 146GB 3.5″ Internal Hard Drive (ST3146855SS). These drives cost around $50 on Amazon. I seem to have drives die on me (click of death). Given your level of experience I’d figure I’d make a post. I do not know if there is some sort of low life expectancy on these drives or what. For 50$ – the hassle is not worth it. I am considering switching to SSD drives. I use these drives in different scenarios (non-production) as a hobbyist to test out different products lately it has been operating system deployments. Thank you for your contributions I was searching the net for reliable SSD drives in a raid setup and found this article – very good information thanks for sharing.
I missed this conversation 1st time around, and came across it recently!
Brent – did you try changing stripe sizes on your Raid array? If SQL is writing in 64K blocks, and SSD are writing 4K blocks, then there may be some benefit to playing with this.
I didn’t see any discussion of how you configured your RAID 5 arrays. Our experience has been that an odd number of drives performs better (4+1, 8+1).
I’m intrigued by the thought that we can get higher performance (at the cost of reliability) by using a single SSD rather than a RAID array.
Toby – yes, we did work with stripe sizes and different numbers of drives. We didn’t publish the complete findings here – I’d definitely encourage folks to do their own experiments because these numbers change rapidly with different RAID controllers, firmware versions, drives, etc.
Hi Brent
Very quick question, in your RAID 10 v single disk test, the CrystalDiskMark screenshot shows the single disk having a usable capacity of 476GB, i.e. a 512GB drive (you also state you went with 16 Samsung 840 Pro 512GB SSDs, I assume these are what you used for the tests?).
The RAID 10 of 8 disks only shows a usable capacity of 953GB, i.e. 1 TB.
Surely a RAID 10 of 8x 512GB disks should be showing close to 2TB?
Is this a mistake, or am I misunderstanding?
Did you compare 1x 512GB Samsung SSD to 8x 512GB Samsung SSDs in RAID 10?
Also why do you believe it is the controller and not something else that accounts for the discrepancy? It is my understanding those controllers can support up to 32x SSDs; seems somewhat odd they cannot handle 8 disks in RAID 10?
Brian – great catch! I was doing repeated back-to-back tests with different NTFS allocation unit sizes, multiple files on different drives simultaneously, etc, so several times during the test, I split the same 8-drive R10 into two different volumes.
Sure, the controllers can support lots of SSDs in much the same way that one horse’s back can support multiple riders. It’s just not gonna go as fast. 😀
How did you get your high write speed with raid 5? I get only ~800 MB/sec with 6x Samsung 850 PRO @ RAID 5…but the read speed was throw up to 2,8 GB/sec!
Did you read Brent’s notes on write caching on the raid controller? I’ve had a similar experience with tuning that setting making a huge impact with an SSD configuration like this.
Brent,
We are getting a proposal from our storage engineers to put our DB storage onto a Hitachi G200 system. They are proposing that we would get 16 400GB SSDs that would be exclusive to our DB cluster. The DB connection would be directly connected over 10Gb fiber and there will be other users that are using another pool of disks. However they are recommending we use RAID 6 for the arrays instead of RAID 10.
What is your take on using RAID 6 on a SAN solution for SQL Server with SSDs for the drives?
Are there any questions regarding the configuration of the SAN, specifically the dedicated fiber channel that they are assigning us that I should be asking?
Regards,
Aaron
Aaron – unfortunately, personalized storage configuration guidance is a little beyond what I can do in a blog comment.
Hi Brent,
No problem I completely understand. I just wanted to pose the questions as I haven’t seen any recommendations where a Raid 6 was used.
Aaron
My understanding is that the driving motivation for RAID 6 has been the likelihood of an Unrecoverable Read Error occurring during a rebuild operation, causing the entire array to be corrupted. This primarily occurs in large capacity consumer grade devices with lower MTBF.
For an enterprise grade SSD which is generally lower capacity and has extremely low rates for Unrecoverable Read Errors I would expect to use RAID 10 (for deep pockets) and RAID 5 for not-so-deep. You’re less likely to encounter an error during the rebuild
Toby
Hi Toby,
Thanks for the reply.
Raid 10 is what I’m leaning towards as it’s been a strong recommendation for a while for the fault tolerance and it is what we are currently using for our local storage. But I wanted to give Raid 6 a fair chance if in the SAN world it has a good track record for performance and fault tolerance for OLTP applications.
Regards,
Aaron
I would go with raid 50. i have done extensive testing on 8 disk arrays and Raid 50 offer the best of both worlds.
Thom – are you saying that no matter what the RAID controller is, no matter what the workload is, RAID 50 is the fastest solution? That’s interesting.
Thom,
With RAID 50 only having a one drive fault tolerance wouldn’t you be extremely nervous about having more than one drive failing before the first hot spare, if one is even available, is fully online? I think Brent mentioned an actual scenario like that in his SSD Hot and Crazy video. http://www.youtube.com/watch?v=FVPmsrXpKjI
I’ve experienced that personally on HDDs and it’s not fun. I could see a case for that on a development environment when data loss and down time for recovery from backups may not be as costly as it is in production.
Since I originally asked the question I’ve decided to go with RAID 10 instead of RAID 6 just for the fact that I feel more comfortable with it and I can get the budget for it even though the storage folks feel RAID 6 would work just fine. I’m not 100% against it but until it’s racked, configured and I can stress test it I’m more comfortable going with practices that have been used for years vs what is on a product spec sheet. But that is just my personal preference since once you get the budget for these things it’s a bit hard to go back for more money so I like to over engineer vs hope for it works.
Brent,
of course not. However with what Aaron was talking about i found that raid 50 is superior to raid 6. you get the same space, better speed, and addressing his comments, you could add a 9th drive as a hot spare but the having two raid 5 arrays the chance of the second failure if the same array is not as great as a failure in the 2nd array
Hi Brent, Wonderful article!
I was wondering if you could comment with a quick follow-up for this machine?
We tried a similar setup but with older Intel SSDs on a Dell MD1000 and the disks dropped frequently (about once per month or two). It was a nightmare.
Has this R720 dropped any disks since you originally posted? Have you had any other problems or learnings?
Thanks again!
Heathclif – with all due respect, older solid state drives from a different vendor, hooked up to an external drive array, isn’t a similar setup at all. 😉
No, the client hasn’t reported dropping any drives.
Haha, good to hear that they haven’t reported dropped drives over two years.
What PERC card model specifically were you using?
Any idea how many gigabytes they are writing per month to the array?
Thanks again!
Heathclif – I use the top ones available during the server builds (off the top of my head, I don’t remember the model numbers each time). These guys were redoing a multi-terabyte database from scratch once per month.
Curious if Dell was just ripping us off for our enterprise SAS SSDs, we also did a test build on a Dell R720xd with a PERC H710P 1GB NV and fifteen Samsung 840 Pro SSDs in RAID-6 in mid-2013.
It seemed fine for a few weeks, but then dropped multiple SSDs and failed the array after running for around 2 weeks as a cluster machine serving around 30 million users in a largely write-once serve many workload. These SSDs were *not* written to death. Since it was just a cluster machine, we suffered no downtime, but it was disappointing.
Maybe the latest PERC firmware version or the 850 Pro is better, but using cheap consumer SSDs in an enterprise production environment in a RAID has been problematic and I wouldn’t recommend it unless you have a lot of time to test, or you’re on a shoestring budget but for some reason simultaneously need > 15k RPM spinner random access or massive storage that an enterprise SAS spinner can’t provide.
On a side note, consumer SSDs can work very well in a non-RAID setup (as long as you have the usual mirrors, backups, and consistency checks). We’ve had zero Samsung failures and one Micron failure in that setting. The just frequently get marked as failed in a RAID, at least for the Dell 6i and 700 series RAID cards we’ve used.
If you have spare time, require a RAID, and feel like mixing water with oil, make sure you buy the SSDs from somewhere with a great return policy, run em hard for 30 days, and cross your fingers 🙂
Samsung M.2 2280 256GB, PCIe 3.0
Lucart – did you have a question, or did you just come here to post random strings of text?
If it’s the latter, I’ll join in: rectangle. America. Megaphone. Monday. Butthole.
2 years on, how are the Samsung SSDs holding up?
Paul – I haven’t talked to the client in a while.
WOW SMB SQL Server!!! Sorry I never looked closely…
Seems to be a server on steroids… How many SMB’s would want to cough up $56k in SQL Server licenses and do it again in 3-5 years. LOL This sounds like an enterprise shop that wants to mask SQL application issues with SSD’s. It is a nice approach and one that I hope they get the ISV to fix the root problem.
I bet the App running on this SQL box is over $100k…
The Average Joe – no, it’s an internally written app. Thanks for stopping by though!
It’s an old post, but overall still good advice IMHO. Some things you might want to consider though.
SSD’s without capacitators often fail when you experience an unexpected failure. There is quite a bit of information about that online; it’ll scare you to death how often this actually happens. 🙂 Since it’s in a RAID configuration, there’s also a higher possibility that this happens to all disks at once.
To solve it, it’s better to get disks that have a capacitator, like the Intel DC’s. They’re pretty cheap as well, and solve this problem.
Second, changing block sizes to 32 or 64 KB is probably better than the default of 4 KB for SSD’s. A block size higher than 32 or 64 KB for the RAID controller also makes no sense. It’s probably best to set them both to 64 KB.
Third, If you have 8 disks, you probably want to make 2 virtual disks of 4 disks in RAID-5. That way, you can put the data (MDF) on disk 1 and the log files (LDF) on disk 2. It’ll probably make your database faster.
Last – and I’m not sure if this is true or fiction – I’ve seen a lot of posts that suggest it’s best not to allocate every last bit for the SSD’s, thereby saving room for TRIM-like operations. Personally I think this is a story of the past, but to be honest I’m not sure.
As for benchmarks, I’m using 4x Intel DC 3610 (800 gb) and hit approximately 2400 MB/s
Stefan – there’s a lot of “probably” in that comment. 😉
Haha yes, sharp observation. 🙂 I believe people should never rely solely on blog posts or comments, there are simply too many variables like workload, exact hw specs, etc that will result in a different outcome; on the other hand simply putting it to the test will always give you the right answer. If you look closely, the ‘probably’s are only in the sections that heavily depend on the scenario at hand and stuff that I couldn’t test.
As such, I generally feel that modesty of the person writing the comment outperforms a narcissistic definitive answer in these cases. 🙂
Stefan – bingo. When you find yourself chaining several “probably” phrases together as guidance, it’s time to focus on just one part of the advice, and give it better justice. Explain the details behind the logic.
Otherwise, it’s not so much modesty as it is overgeneralization.
“Adaptive read ahead” or just “read ahead” ?
“adaptive read ahead” cache the next 4 parity stripes if you read 4 stripes in a row
“read ahead” cache 4 parity stripes all the time
“Adaptive read ahead” performs better as more adaptative
What specific RAID Controller was used for this test? I notice several options on the Dell site. You seem to imply you’ve used Dual PERC H710P controllers, I just want to confirm explicitely that is the case. If so, Do your RAID 5 and RAID 10 benchmarks test arrays that spanned both controllers? (if that’s even possible).
Great article. I love both the results, and the explanation of methodology and reasoning why to do these specific tests. Thanks!
I’ve been considering the exact same server (albiet with overpriced Dell supported SSD’s), but need to try to spec it perfectly before I have it in my hands to benchmark. So your hands-on testing is very timely and informative. Thanks for sharing.
Adam – your best bet is to redo the load tests yourself since so much time has passed. (The 720 isn’t even a current Dell model now.) I’d always recommend the most number of best RAID controllers you can get – today’s SSDs are crazy fast, and tomorrow’s will only be faster.
I LIKE IT
what is the best SSD right now? I confused on choosing SSD for my PC
This isn’t a PC SSD review site, sorry.
Hey, Brent. GREAT post. This kind of stuff really intrigues me. I am curious about a statement you made…
“The R720 has two separate RAID controllers, each of which can see 8 of the Samsung drives. The drawback of this server design is that you can’t make one big 16-drive RAID 10 array.”
How did you actually end up configuring your setup on these two different raid controllers? How many arrays, partitions in the array, etc.?
Also, If you only had one Raid controller, all drives in one array, and then partitioned out accordingly, do you think that would be a setup for future performance issues? I am just thinking that having everything on one controller and all in the same array might be cause for some concern?
I am still so new to all this but it’s all so interesting.
Brandon – make sure to read this part:
The objective of this post isn’t to give you step-by-step configuration advice 6 years later – the objective is to show you the level of testing you need to do with your own hardware in order to come up with the right mix for your own workloads. Hope that helps!
For sure, I didn’t neglect that part at all and have been doing some extensive testing on our system here. I am just curious how you ended up configuring it… do you recall how it ended up?
One thing I can’t seem to find any info about is if there is a down side to have 1 RAID 10 array with different logical partitions for the various drives (OS, Data, Logs, TempDB, Backup) or if they should be split out into their own arrays, I guess that is why I am curious how your system ended up.
No, I don’t recall offhand – it was 6 years ago, and I’ve worked on hundreds of servers since then. Sorry!
No problem, haha! What about my 2nd question. Is there a down side to 1 RAID 10 array for everything or should they be split out into different arrays?
Brandon – seriously, the advice is different per server config. You really have to get to know each environment and understand its pros and cons. I really wish I could do personalized system configurations for people in blog post comments, but that’s not realistic, okay? Thanks for understanding.
Understandable again. Not even a best practice though? I am not looking for you to personally configure my system just trying to learn what best practices are as I grow as a DBA.
Thanks.
Nope – what’s a best practice for one RAID controller can be a worst best practice for another.
I wish your career would be as easy as following a best practices checklist for everything, but that’s just not how IT works. Hope that helps!
Great article. It’s doing well. Interesting conclusions. Interesting information.
We have Dell PowerEdge R720XD and your information is very useful.
Thank you !