What’s Stopping You – from Snooping?
23 Comments
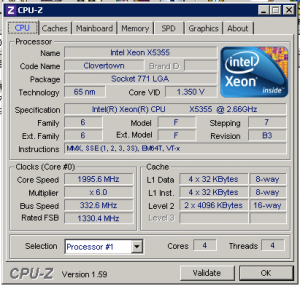
No, this isn’t a touchy-feely inspirational post that talks you into taking leaps and bounds in your career. I write those every now and then, but that ain’t today. Instead, today’s post is about a question: what’s stopping you from snooping in your company’s data? You, as someone with a lot of database access, have…
Read More