
Identity Columns Can Have Gaps, and That’s Okay.
Say you’ve got a table with an identity column, something that’s supposed to start at 1 and go up to a bajillion:
|
1 2 3 4 5 6 7 8 9 10 |
DROP TABLE IF EXISTS dbo.Orders; CREATE TABLE dbo.Orders (Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, OrderDate DATETIME2, CustomerName NVARCHAR(50)); GO /* Put a starter row in there: */ INSERT INTO dbo.Orders (OrderDate, CustomerName) VALUES (SYSDATETIME(), N'First'); |
And you use that identity number for invoice numbers, or customer numbers, or whatever, and you expect that every single number will be taken up. For example, your accounting team might say, “We see order ID 1, 3, and 4 – what happened to order ID #2? Did someone take cash money from a customer, print up an invoice for them, and then delete the invoice and pocket the cash?”
Well, that might have happened. But there are all kinds of reasons why we’d have a gap in identities. One of the most common is failed or rolled-back transactions. To illustrate it, let’s start a transaction in one window:
|
1 2 3 |
BEGIN TRAN INSERT INTO dbo.Orders (OrderDate, CustomerName) VALUES (SYSDATETIME(), N'Second'); |
In another separate session window, run another insert, not bothering to do a transaction:
|
1 2 |
INSERT INTO dbo.Orders (OrderDate, CustomerName) VALUES (SYSDATETIME(), N'Third'); |
At this moment, here’s what our order table looks like:
- Id 1 – taken by the first setup insert
- Id 2 – taken by the second insert, but it’s in a transaction, and that transaction hasn’t been committed yet
- Id 3 – taken by the third insert, which is finished, because there wasn’t a transaction involved
If our transaction fails for some reason, or we roll it back, and then we check to see the contents of the table:
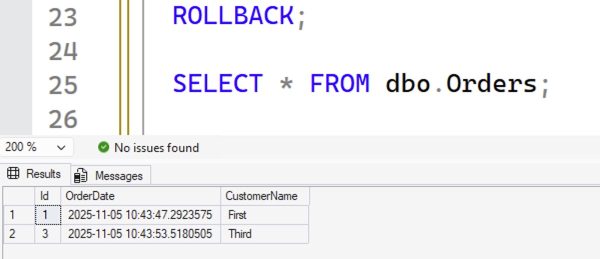
Order ID #2 is missing. That ID won’t get reused, either: if we continue on with another insert, and check the table’s contents again:
|
1 2 3 4 5 |
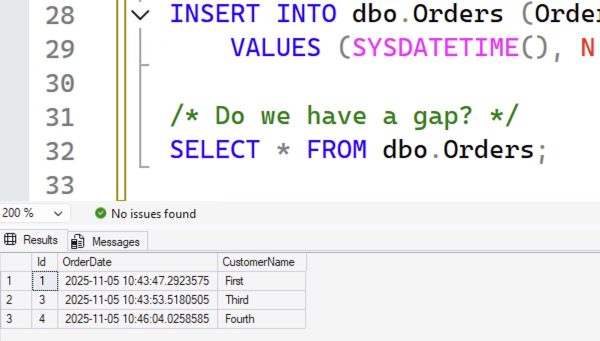
INSERT INTO dbo.Orders (OrderDate, CustomerName) VALUES (SYSDATETIME(), N'Fourth'); /* Do we have a gap? */ SELECT * FROM dbo.Orders; |
There’s a gap, and we don’t particularly need to mind it:
Deletions and rollbacks are by far the most common cause for gaps. Another niche cause is the identity cache, a built-in, on-by-default performance feature that speeds up inserts by having a few identities ready to go, just like Jason Bourne.
All this to say you can’t really rely on SQL Server’s built-in identity columns for external uses like auditing.

13 Comments. Leave new
The Identity Cache feature came to my attention several years ago when our sequentially-numbered truck delivery ticket numbers would mysteriously jump by 1000 every time the machine lost power. (Don’t ask…)
We ended up installing a UPS and disabling the Identity Cache in SQL Server.
This is a great example of something that demonstrates a behaviour so often it’s often seen as a defect when it doesn’t.
I’m going to link to this page the next time this comes up.
Another case is when results seem ordered even when there is no ORDER BY clause.
Nice demonstration.
We observed a significant gap caused by identity cache behavior and rollbacks across both SQL Server and DB2 platforms.
Thanks, Brent.
While they seem okay for DBA’s, if the customer see’s the gaps, they don’t like it. We had this case where we were also loosing thousands of identities due to power outages or other reasons. Our customers would continue to ask why this was occurring and what happened to those orders. We finally got rid of the auto-increment and just queried top 1 pk in the table and used that in our stored procedure to cut down on needless traffic.
You understand that the TOP 1 solution will also have the same gaps if they’re used inside a transaction and there’s a rollback, right?
Session A: starts a tran, gets the top 1, inserts a row with Id 12345
Session B: starts a tran, gets the top 1, inserts a row with Id 12346
Session A: hits an error or rolls back their tran
Session B: commits
Now you have a row 12346 in there, but no 12345. The next row inserted won’t be 12345, it’ll be 12347.
That’s a really good point, it’s possible. However, the odds of that happening in relatively low usage (100 records/day) are astronomical. But it does make me think about any potential concurrency issues.
Wish there was a better choice. That should be on one of your famous T-Shirts: “There are no answers, only better choices.” 🙂
What about a sp that returns the first missing number, so you are “filling the holes”?
Sure, you could totally craft that – but it will have multiple performance challenges. First, you’re going to have to *find* that number, which is going to be resource-intensive, and then you’re going to have to hold a lock on it while you work, lest someone else claim that same number at the same time.
Anecdotal, but…. Back when I was a wee nipper in my 20ies, I got chewed out by a CPA for 10 minutes straight for having caused a large (150’ish) gap in a numberseries. Quite impressive, he didn’t repeat himself once.
[…] Brent Ozar explains why there can be gaps in identity columns: […]
Just curious, but does using a sequence and FETCH NEXT inside a transaction solve the problem, or does the same rollback problem occur regardless?
By all means, you’re welcome to take the open source database and the queries above to run experiments to find that out! I wish I could cover every possible variation in a blog post, but I’m sure you understand why I can’t quite pull that off. 😉
I understand small gaps due to rollbacks/failures and gaps of 1000 due to the loss of cached IDs. But we had instances of gaps of tens of millions (biggest instance was 120M gap) and I cannot figure out how that can happen. We delete from that table but not chunks this big (table only has 88M rows).
We found out only when we ran out of INT IDs and inserts started failing. We had to renumber the IDs to get rid of the problem.