
Improving Cardinality Estimation: Answers & Discussion
Your challenge for last week was to take this Stack Overflow database query to show the top-ranking users in the most popular location:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE INDEX Location ON dbo.Users(Location); GO CREATE OR ALTER PROC dbo.GetTopUsersInTopLocation AS SELECT TOP 200 u.Reputation, u.Id, u.DisplayName, u.WebsiteUrl, u.CreationDate FROM dbo.Users u WHERE u.Location = (SELECT TOP 1 Location FROM dbo.Users WHERE Location <> N'' GROUP BY Location ORDER BY COUNT(*) DESC) ORDER BY u.Reputation DESC; GO |
And make it read less pages only by tuning the query? You weren’t allowed to make index or server changes, and you weren’t allowed to hard code the location in the query since it might change over time.
The Core of the Problem
The main problem is that when we run a statement (like SELECT), SQL Server:
- Designs the execution plan for the entire statement all at once, without executing anything, then
- Executes the entire statement all at once, with no plan changes allowed
Think of it as two different departments, neither of which are allowed to do the job of the other. The design department sketches out the query plan, but it has no idea of what this part of the query will produce:
|
1 2 3 4 5 |
SELECT TOP 1 Location FROM dbo.Users WHERE Location <> N'' GROUP BY Location ORDER BY COUNT(*) DESC |
You might think, “Well, doesn’t SQL Server have statistics on Location? After all, we have an index on Location, right?” That’s true, and here are the stats:
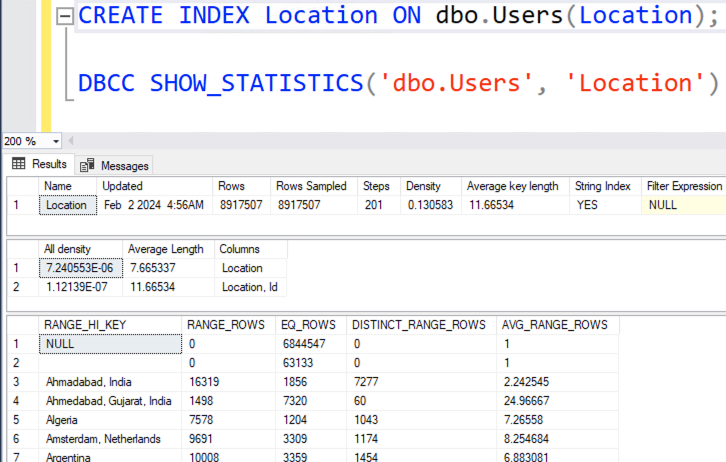
In my histogram, the table has 8.9 million rows, and NULL is 6.8 million of them. Easy then, right? Our top location is null! Use the 6.8M row estimate. Except… look at the WHERE clause of our query again:
|
1 2 3 4 5 |
SELECT TOP 1 Location FROM dbo.Users WHERE Location <> N'' GROUP BY Location ORDER BY COUNT(*) DESC |
We’re filtering out the nulls and empty strings. To get that estimate right, SQL Server would have to execute the query by evaluating the where clause, doing the group by, doing the order by, etc. That’s way, way beyond what the query optimizer will do.
The design department has to design a query plan without knowing the output of the CTE. It simply doesn’t know what the top location will be, so it makes a guess:
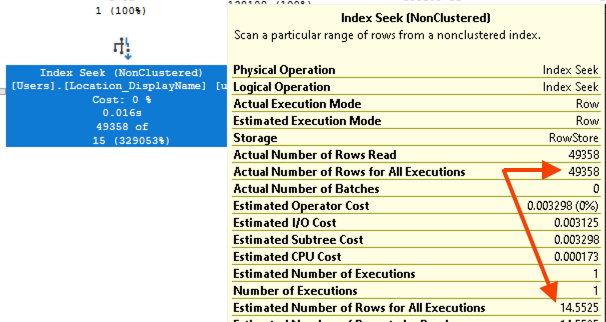
And of course that 14-row guess is nowhere near the 49,358 people who actually live in the top location. That’s fair: if the design department is forced to make a guess without being allowed to execute the query, then the estimate is going to be hot garbage.
The Core of the Solution
If the problem is:
- Designs the execution plan for the entire statement all at once, without executing anything, then
- Executes the entire statement all at once, with no plan changes allowed
Then the solution is to break the statement up into multiple statements. In pseudocode:
- Find the top location, then
- Find the users who live in that location, after we know what the location is
But it’s not enough to just do them in two statements. If I just do this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE OR ALTER PROC dbo.GetTopUsersInTopLocation_TwoStatementsOneProc AS BEGIN DECLARE @TopLocation NVARCHAR(100) = (SELECT TOP 1 Location FROM dbo.Users WHERE Location <> N'' GROUP BY Location ORDER BY COUNT(*) DESC); SELECT TOP 200 u.Reputation, u.Id, u.DisplayName, u.WebsiteUrl, u.CreationDate FROM dbo.Users u WHERE u.Location = @TopLocation ORDER BY u.Reputation DESC; END GO |
Then the second query in the batch still has a crappy plan with bad estimates:
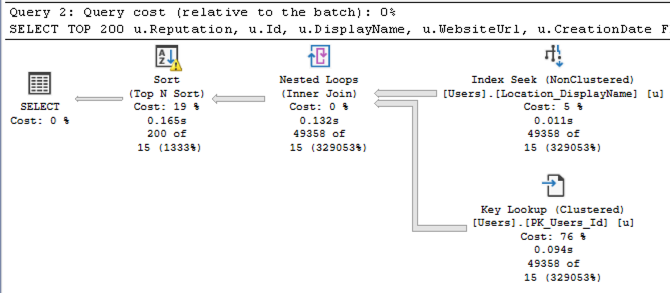
Because SQL Server doesn’t just build plans for a statement all at once, it builds plans for the entire stored procedure all at once, too. So the real core of the solution is:
- Find the top location, then
- Go back to the design department for a new plan to find the users who live in that location, after we know what the location is
The Easiest Solution: Option Recompile
One of the easiest-to-implement methods is to slap an OPTION (RECOMPILE) on the second statement in the newly fixed proc:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE OR ALTER PROC dbo.GetTopUsersInTopLocation_OptionRecompile AS BEGIN DECLARE @TopLocation NVARCHAR(100) = (SELECT TOP 1 Location FROM dbo.Users WHERE Location <> N'' GROUP BY Location ORDER BY COUNT(*) DESC); SELECT TOP 200 u.Reputation, u.Id, u.DisplayName, u.WebsiteUrl, u.CreationDate FROM dbo.Users u WHERE u.Location = @TopLocation ORDER BY u.Reputation DESC OPTION (RECOMPILE) END GO |
That tells SQL Server to go back to the design department at that specific point in the stored procedure, and build a new execution plan based on what we’ve learned so far. At that point in the plan, the @TopLocation’s value has been set, so instead of a crappy 15-row estimate, SQL Server estimates the exact 49,358 rows that’ll come back, as shown in the new plan:

The new plan has more accurate estimates, which drives:
- Adding parallelism into the plan
- Higher memory grant estimates for the sort, avoiding spills
- A clustered index scan instead of using the index on Location
You might think that last one is a problem, but it’s actually good, because we’re doing less logical reads than we did before:
- Original query: 160,419 logical reads
- Two statements: 160,419 logical reads
- Recompile: 155,726 logical reads
Option recompile has a bad reputation amongst DBAs because it does add additional CPU time to compile a new execution plan every time that the statement runs. Odds are, the top location isn’t changing all that often – so wouldn’t it be cooler if we could cache a plan for a longer period of time?
Harder, But Better: Caching a Plan
Ideally, we need SQL Server to sniff the most popular location, build a plan for it, and then cache that plan. One way to do that is by using dynamic SQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE OR ALTER PROC dbo.GetTopUsersInTopLocation_DynamicSQL AS BEGIN DECLARE @TopLocation NVARCHAR(100) = (SELECT TOP 1 Location FROM dbo.Users WHERE Location <> N'' GROUP BY Location ORDER BY COUNT(*) DESC); DECLARE @StringToExec NVARCHAR(4000) = N' SELECT TOP 200 u.Reputation, u.Id, u.DisplayName, u.WebsiteUrl, u.CreationDate FROM dbo.Users u WHERE u.Location = @TopLocation ORDER BY u.Reputation DESC;' EXEC sp_executesql @StringToExec, N'@TopLocation NVARCHAR(100)', @TopLocation; END GO |
Now, when SQL Server goes to execute the entire stored procedure, it builds the execution plan for the entire stored procedure. Here’s what it thinks:
- “I’m gonna declare a variable, @TopLocation.”
- “I’m gonna set the contents of that variable with this here query, so I’ll build a plan for that.”
- “I’m gonna declare another variable, @StringToExec, and set its contents to a string.”
- “I’m gonna call sp_executesql with the contents of that string.”
But when it designs this execution plan, it doesn’t build the plan for what sp_executesql is gonna do. That’ll be done later, at the time sp_executesql is called. When sp_executesql is called, SQL Server will be spoon-fed the contents of @TopLocation – so parameter sniffing works in our favor! The plan will only be built once and the plan will stick around as long as practical in the plan cache.
A similar solution would be to break out the SELECT TOP 200 query into a separate child stored procedure, and that would have the same effect.
One drawback of both of those solutions: they’re not appropriate under this circumstance:
- The @TopLocation keeps changing, and
- The @TopLocation has dramatically different numbers of people who live in it, and
- The statistics on the Users table don’t change quickly enough to keep up with those changes, and
- Our plan cache is stable enough to keep the original plan around
But that’s quite unlikely.
How’d you do? What’d you think?
I hope you had fun, enjoyed this exercise, and learned a little something. If you’ve got comments or questions, hit the comment section below.
I know some folks are going to say, “But why didn’t you cover temp tables?” The problem with temp tables is that they’re like OPTION (RANDOM RECOMPILE), as I discuss in my Fundamentals of TempDB class and Paul White discusses in his temp table caching series. They’ll work great in standalone testing, and then at scale, your users will keep asking why they’re getting someone else’s execution plan.

16 Comments. Leave new
Option (RECOMPILE) seems like a nice solution since that sproc probably isn’t executed thousands of times per second.
Great post!
Thanks, glad you liked it!
Thanks Brent for putting these together; really helpful to see a real-world type scenario with several potential gotchas and solutions for us to learn from! Enjoy learning/ refreshing my skills this way
My pleasure! It’s a lot of fun.
I love this new query exercises series, thanks Brent!
Thanks, glad you like ’em!
“In my histogram, the table has 8.9 million rows, and NULL is 6.8 million of them. Easy then, right? Our top location is null! Use the 6.8M row estimate. Except… look at the WHERE clause of our query again:”
The optimizer could reorder the histogram by the EQ_ROWS column and ignore the two values we know we are not interested in (NULL and ”) ? Am I right in thinking the optimizer would not be able to use this approach because there are only 201 buckets in the histogram and “in theory” the top location value could be one of those without its own bucket?
Having thought about this a little more, maybe the reason it doesn’t do this is like you say, it would be kind of like running another query (against the histogram) which would require memory for the sort, as well as having to evaluate each range hi key to see if our where clause is filtering it out etc which is starting to get more intensive…..
Bingo! You nailed it.
Hey Brent,
Have you seen this: https://smartpostgres.com/posts/improving-cardinality-estimation-answers-discussion/
It looks suspiciously familiar.
Not sure if they are copying you, but…
BTW, nice challenge. This is exactly the type of thing I try to urge the developers in my company to think about. Too often people want to run everything in one go rather than separating it out to give the SQL Server “design department” a chance to do its work properly.
I like the dynamic SQL version too. That may be a harder one to convince some managers of because there still is a very pervasive idea that dynamic sql is bad!!!
Actually, Brent, my apologies, that is you!!!! Ha ha!! Silly me.
No worries! I haven’t finished the branding on that site yet – I’ll be more prominent on there soon.
My brain is so cooked today, man… how does:
WHERE Location N”
filter out nulls? Because I’d love something cleaner than:
WHERE nullif(trim(col1),”) is not null
Thank you for everything you’ve taught me over the years, btw… sorry I’ve failed you on this one!
I’m not sure what you mean by “how does it filter out nulls” – if you’re asking IF it filters out nulls, try it and you’ll see that it does. Can you rephrase your question?
Today years old, Brent… today years old.
Not to hijack a great conversation about CE with some 101 crap about three valued logic, but seriously. It seems years ago when some SQL mentor taught me about NULLs, my naive takeaway was that a query engine would return unknowns because the comparison “wasn’t false”. I’ve been dragging that with me. For. Decades. Where’s that little emoji who is slapping his own head?
It feels like I’ve been mispronouncing my own name. Public humility is a great teacher.. ?
Awww, there you go! At least you’ve got it now!