T-SQL & Development
How to Batch Updates A Few Thousand Rows at a Time
You’ve got a staging table with millions of rows, and you want to join that over to a production table and update the contents. However, when you try to do it all in one big statement, you end up with lock escalation, large transaction log usage, slow replication to Availability Groups, and angry users with pitchforks gathered in the Zoom lobby.
In this post, I’ll explain how to use a combination of two separate topics that I’ve blogged about recently:
- Fast ordered deletes: how to delete just a few rows from a really large table
- The virtual output tables: how to get identity values for rows you just inserted
Setting up the problem
I’ll start with the Stack Overflow database (any version will work) and make a copy of the Users table called Users_Staging, and I’ll change a bunch of values in it to simulate a table we need to import from somewhere else:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT * INTO dbo.Users_Staging FROM dbo.Users; GO /* Change some of their data randomly: */ UPDATE dbo.Users_Staging SET Reputation = CASE WHEN Id % 2 = 0 THEN Reputation + 100 ELSE Reputation END, LastAccessDate = CASE WHEN Id % 3 = 0 THEN GETDATE() ELSE LastAccessDate END, DownVotes = CASE WHEN Id % 10 = 0 THEN 0 ELSE DownVotes END, UpVotes = CASE WHEN Id % 11 = 0 THEN 0 ELSE UpVotes END, Views = CASE WHEN Id % 7 = 0 THEN Views + 1 ELSE Views END; GO CREATE UNIQUE CLUSTERED INDEX Id ON dbo.Users_Staging(Id); |
If I try to run a single update statement and update all of the rows:
|
1 2 3 4 5 6 7 |
UPDATE u SET Age = us.Age, CreationDate = us.CreationDate, DisplayName = us.DisplayName, DownVotes = us.DownVotes, EmailHash = us.EmailHash, LastAccessDate = us.LastAccessDate, Location = us.Location, Reputation = us.Reputation, UpVotes = us.UpVotes, Views = us.Views, WebsiteUrl = us.WebsiteUrl, AccountId = us.AccountId FROM dbo.Users u INNER JOIN dbo.Users_Staging us ON u.Id = us.Id |
Then while it’s running, check the locks it’s holding in another window with sp_WhoIsActive @get_locks = 1:
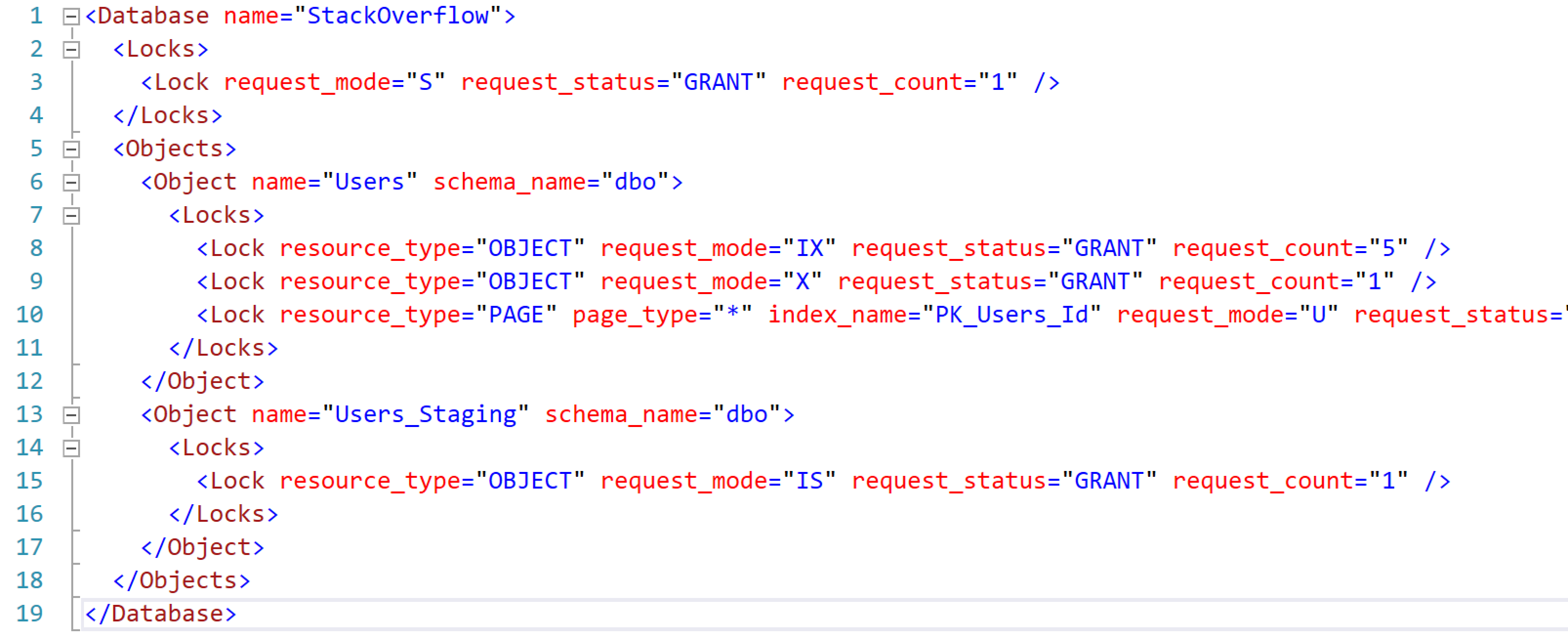
See how the Users table says “OBJECT” request_mode “X”? That means my update query has gotten an eXclusive lock on the Users table. That’s your sign that other queries will be screaming with anger as they wait around for your update to finish.
Now, sometimes that’s what you actually want: sometimes you want to rip the Band-Aid off and get all of your work done in a single transaction. However, sometimes you want to work through the operation in small chunks, avoiding lock escalation. In that case, we’re going to need a batching process.
How to fix it using the fast ordered delete technique and the output table technique
I’m going to encapsulate my work in a stored procedure so that it can be repeatedly called by whatever application I’m using to control my ETL process. You could do this same technique with a loop (like while exists rows in the staging table), but I’m choosing not to cover that here. When you get your own blog, you’ll realize that you also get to control what you write about … and everyone will complain regardless. Here we go:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE OR ALTER PROC dbo.usp_UsersETL @RowsAffected INT = NULL OUTPUT AS BEGIN CREATE TABLE #RowsAffected (Id INT); BEGIN TRAN; WITH RowsToUpdate AS (SELECT TOP 1000 * FROM dbo.Users_Staging ORDER BY Id ) UPDATE u SET Age = us.Age, CreationDate = us.CreationDate, DisplayName = us.DisplayName, DownVotes = us.DownVotes, EmailHash = us.EmailHash, LastAccessDate = us.LastAccessDate, Location = us.Location, Reputation = us.Reputation, UpVotes = us.UpVotes, Views = us.Views, WebsiteUrl = us.WebsiteUrl, AccountId = us.AccountId OUTPUT INSERTED.Id INTO #RowsAffected FROM RowsToUpdate us INNER JOIN dbo.Users u ON u.Id = us.Id DELETE dbo.Users_Staging WHERE Id IN (SELECT Id FROM #RowsAffected); COMMIT SELECT @RowsAffected = COUNT(*) FROM #RowsAffected; END GO |
When I execute that stored procedure, the locks look like a hot mess, but note the lock level on the Users object:
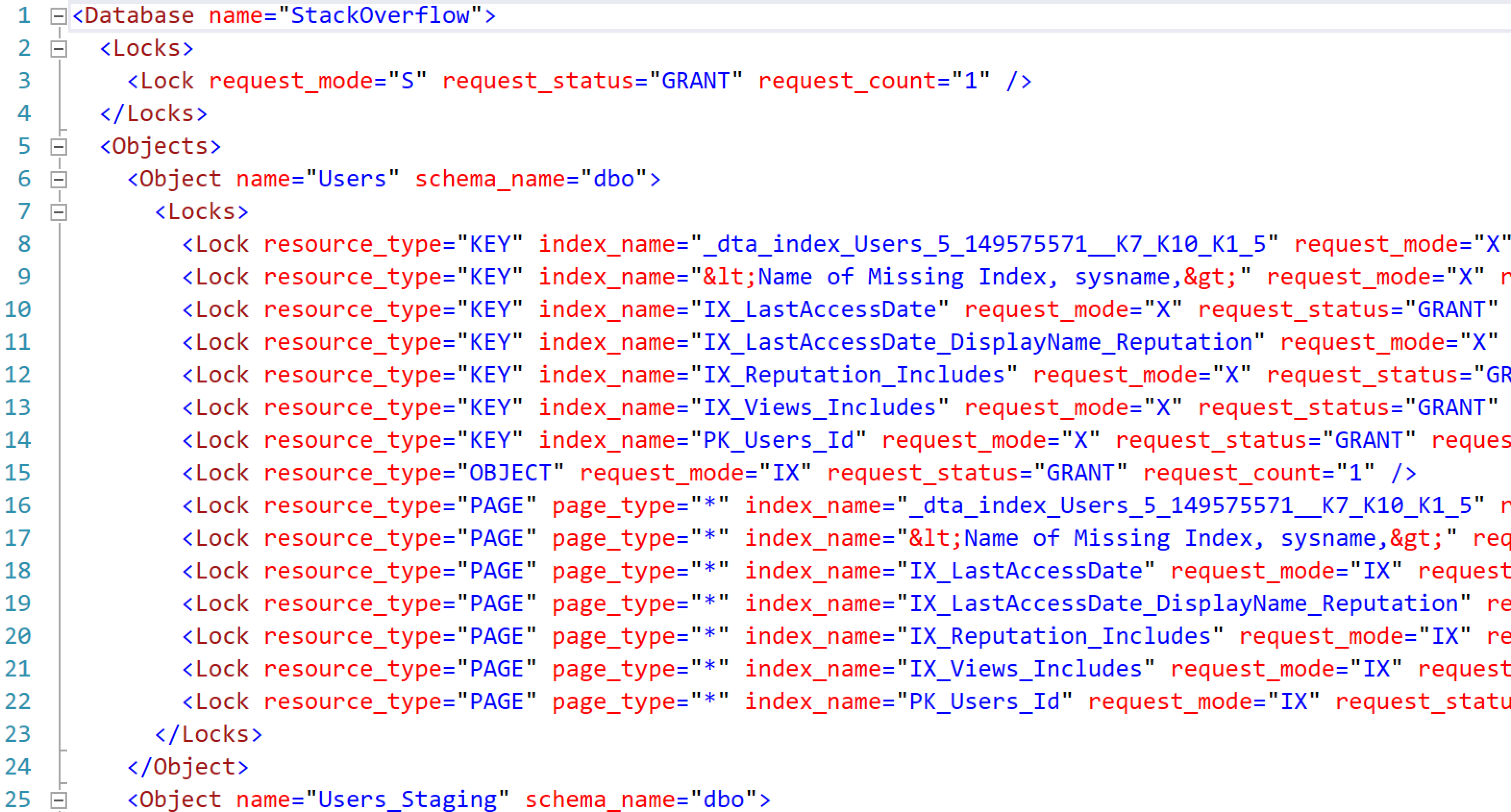
Now, they say “OBJECT” request_mode=”IX”, which means INTENT exclusive as opposed to just straight exclusive. This means that SQL Server is starting some work, and it might need to escalate the locks to table level…but as long as you keep the number of rows & locks low, it won’t have to. In this case, my stored procedure runs & finishes quickly without escalating to a table-level lock.
There two parts of the proc that make this magic happen. This part:
|
1 |
WITH RowsToUpdate AS (SELECT TOP 1000 * FROM dbo.Users_Staging ORDER BY Id) |
Tells SQL Server that it’s only going to grab 1,000 rows, and it’s going to be easy to identify exactly which 1,000 rows they are because our staging table has a clustered index on Id. That enables SQL Server to grab those 1,000 rows first, then do exactly 1,000 clustered index seeks on the dbo.Users table.
The second magical component:
|
1 |
OUTPUT INSERTED.Id INTO #RowsAffected |
Tells SQL Server to track which 1,000 Ids got updated. This way, we can be certain about which rows we can safely remove from the Users_Staging table.
For bonus points, if you wanted to keep the rows in the dbo.Users_Staging table while you worked rather than deleting them, you could do something like:
- Add an Is_Processed bit column to dbo.Users_Staging
- Add “WHERE Is_Processed IS NULL” filter to the update clause so that we don’t update rows twice
- After the update finishes, update the Is_Processed column in dbo.Users_Staging to denote that the row is already taken care of
However, when you add more stuff like this, you also introduce more overhead to the batch process. I’ve also seen cases where complex filters on the dbo.Users_Staging table would cause SQL Server to not quickly identify the next 1,000 rows to process.
If you’re doing this work,
you should also read…
This blog post was to explain one very specific technique: combining fast ordered deletes with an output table. This post isn’t meant to be an overall compendium of everything you need to know while building ETL code. However, as long as you’ve finished this post, I want to leave you with a few related links that you’re gonna love because they help you build more predictable and performant code:
- Which locks count toward lock escalation – explains why I had to go down to 1,000 rows during my update batches
- Video: using batches to do a lot of work without blocking – from my Mastering Query Tuning class
- Take care when scripting in batches – how to do more savvy batching using indexes
- Error and transaction handling in SQL Server, part 1 and part 2
- Why you probably shouldn’t use the MERGE statement to do this
- Detecting which rows have changed using CHECKSUM and HASHBYTES
- The impact of updating columns that haven’t changed
- The impact of update triggers when data isn’t actually changing
Or, if you’d like to watch me write this blog post, I did it on a recent stream:

Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
– Why are you not just updating rows, that are changed (comparing their values it in the where, it would prevent some writes (except ALL rows where changed), and may prevent triggers / history tables / last_updated columns etc.
– Why are you not creating a @id, init it with 0 (or whatever is your lowest user ID – 1), add a WHERE id > @id in the CTE and set it to
SELECT @id = max(id) from #RowsAffected;
after the update. this way you would have your stating table untouched (either for further use or if something went wrong)
Thomas – may want to read the article again, a little more carefully this time, where I talk about options to leave your starting table untouched. Enjoy!
I thought ORDER BY was not allowed in a CTE.
It is if you also have TOP.
Thanks, I didn’t look closely enough. Seems to be running rampant in today’s responses. By the way, love the daily feeding of info.
Nice post, thanks Brent.
Another similar technique I’ve used to chop up large operations is to key off the statistics histogram of the clustered index. Usually this gives an automatic ~200 chunks and is easy to track (e.g. copied into a temp table).
Thanks Brent for the post.
As an alternative (and if you do not need to control the lock escallation as much), I have tended to do batched updates as an old fashioned label loop (I come form the heady days of SQL 4.21a when fancy cte’s and young whipper snapper things did not exist :-)) ) and this works well when I have to trickle updates, dels & inserts – the approach also means I do not usually need any staging logic and if the update is kicked out from deadlocking or errors it can be restarted without any remedial work in the code.
Feel free to use, ignore, laugh at ( ho ho ho we dont use that old Grandpa technique anymore)
BrentG
— =================================
DECLARE @err INT
DECLARE @rcnt INT
—
—
— set up my chunk size
SET ROWCOUNT 1000
— set up a loop
oldfashionedlabel:
BEGIN TRAN
RAISERROR(‘– %s %d and stuff here’,0,-1, @var1….) WITH NOWAIT
—
— trap some basics (very first thing after upd/del/ins stmt)
SELECT @rcnt = @@ROWCOUNT, @err = @@ERROR
— test for row count >0 and no errors, commit if good, rollback if not so good.
IF @err=0 AND @rcnt>0
BEGIN
COMMIT TRAN
— optional sledgehammer (or call out the guard)
CHECKPOINT
— swap partners, do-se-do, and back around
GOTO oldfashionedlabel
END
ELSE
BEGIN
ROLLBACK TRAN
END
— reset
SET ROWCOUNT 0
— =================================
It would have been better if you wrote this article a week earlier.
I’ve been doing the loop technique which, in my defence, is better than never updating anything at all.
Great post.
Alan – hahaha, my pleasure! Glad I could help.
Kudos for the ‘Zoom Lobby’ bit. Too funny!
Hi, Brent,
There is a logic error in (SELECT TOP 1000 * FROM dbo.Users_Staging ORDER BY Id). Suppose there are 5,000 brand new users with consecutive id, you pick first 1,000 ids, 0 will be updated and deleted from User_Staging; run the procedure again and exactly the same 1,000 rows will be selected, nothing will be updated nor deleted. it just never ends.
It works for your scenario because you copied Users table to Users_Staging; in reality, it’s from Users_Staging to User, new users may not exist on Users table.
Tony – yes, I described the update-only solution as the goal in the post. In, uh, the very first sentence. (Sigh) Reading is fundamental. 😉
It’s even in the TITLE of the post, for God’s sake.
thank you, Brent, I subscribed to your newsletter and I am not picky. I did this many, many times. But I control how many rows to be updated, the procedure only updates the rows in the parameter.
Your approach is very different from mine and you even named procedure as usp_UserETL, but the ids were not passed in. That’s why it triggered me to review and learn something new.
I finally needed this batch thing for some maintenance. Thanks for keeping good knowledge around for that special moment, kind Sir!
You’re welcome! Glad I could help.