
If you wanna count the number of rows in a table, I’ve usually said, “It doesn’t matter what you put inside the COUNT() – it can be COUNT(*), COUNT(Id), COUNT(1), or COUNT(‘Chocula’), or even COUNT(1/0) – it all works the same.”
And that was true right up until I added a columnstore index.
Start with the Stack Overflow database – any size will do – and do a plain ol’ COUNT when no nonclustered indexes are present:
|
1 2 3 4 5 6 |
DropIndexes; GO SELECT COUNT(*) FROM dbo.Users; SELECT COUNT('Chocula') FROM dbo.Users; SELECT COUNT(1/0) FROM dbo.Users; GO |
The actual execution plans for all three queries are the same:
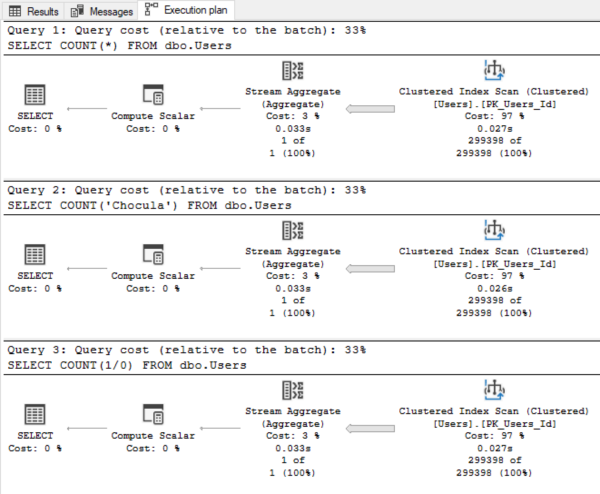
Add a nonclustered rowstore index on any column and try the queries again:
|
1 2 3 4 5 6 |
CREATE INDEX Id ON dbo.Users(Age); GO SELECT COUNT(*) FROM dbo.Users; SELECT COUNT('Chocula') FROM dbo.Users; SELECT COUNT(1/0) FROM dbo.Users; GO |
And again, all three query plans are the same because SQL Server optimizes away the contents of the COUNT(), using the index in all three cases:
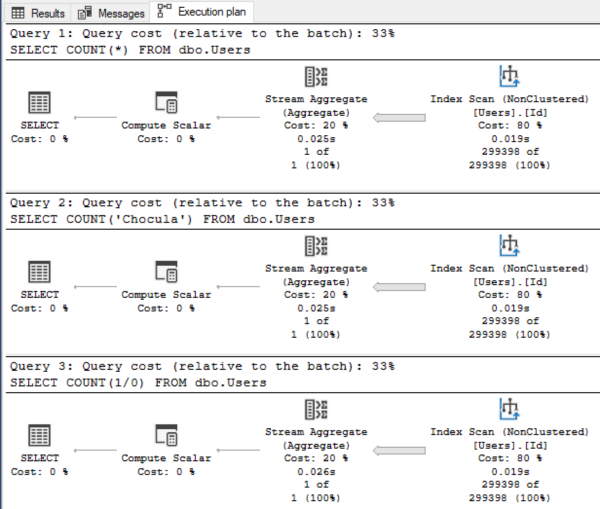
The index gets used every time. So for years, ever since Jeremiah Peschka or Kendra Little (I can’t remember which one) showed me that 1/0 trick, I’ve used COUNT(1/0) because it’s funny.
Well, the laughing stops when you add a nonclustered columnstore index:
|
1 2 3 4 5 6 |
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI ON dbo.Users(Age); GO SELECT COUNT(*) FROM dbo.Users; SELECT COUNT('Chocula') FROM dbo.Users; SELECT COUNT(1/0) FROM dbo.Users; GO |
Because only two of those queries work at all! The first two work fine, scanning the nonclustered columnstore index, but the COUNT(1/0) fails with the obvious error:
|
1 2 |
Msg 8134, Level 16, State 1, Line 20 Divide by zero error encountered. |
The estimated execution plans for all three queries are now slightly different:
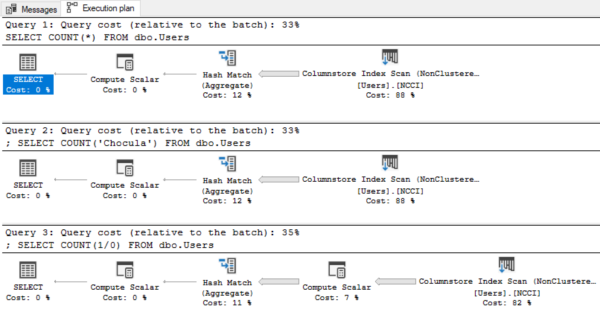
The COUNT(1/0) plan has a Compute Scalar operator that the other two plans don’t have, and here’s the disappointing definition:
|
1 |
[Expr1006] = Scalar Operator((1)/(0)) |
Diabolical.
So what’s the lesson here? Well, don’t be amusing with your T-SQL, I guess, because sooner or later, the query optimizer behavior you depended on can change.

6 Comments. Leave new
Ouch!
I’m sure they will optimize constant propagation eventually. . .
Heh,,, it’s not nice to fool mother optimizer. Get the butter! You’re going to need the lubrication after that! 😀
Pardon me, but can you teach me what’s so diabolical of this scalar operator definition? I failed to understand.
It breaks the entire query, doing a 1/0 operation.
Oh, it was because of the ‘divide by zero’? Thank you.
Interessting … it work´s correct with compatibility 130 and lower.