
Azure SQL Managed Instances and Database Corruption
Disclaimer: I love Azure SQL Managed Instances (MIs) so far. They’re really cool, and I’m having a fun time playing with them. I’m about to describe a bug, and I’m sure this bug will be fixed soon, so it shouldn’t stop you from previewing Managed Instances. This post is not “MIs are t3h suxxors” – it’s just making sure you understand that this is new technology, and if you’re going to bet your business on new technology, you need to test it by pushing the limits. That’s what we do here. This isn’t the kind of blog that mindlessly parrots press releases: we’re real world users, so we beat the hell out of technology before we recommend it to customers. I’m sharing this to explain the kind of work we do, and why we put so much effort into getting tools like sp_Blitz so you can get the right alerts at the right time. Now, on with the show.
Corruption has always been kind of a gray area in Azure’s Platform-as-a-Service offerings. Yes, Microsoft manages your backups, and they can recover the entire database to a point in time for you, but it’s not clear what happens if you want to attempt corruption repair for specific objects. It’s not like you get access to the log backups and can do a page level restore.
(I can hear the cloud zealots screaming already, “There’s no corruption in the cloud!” Buckle up, watch, and learn.)
So while working on getting sp_Blitz fully compatible with MIs, I found it pretty interesting that Microsoft isn’t running CHECKDB for you. When sp_Blitz returned an alert about CHECKDB not being run, I thought it was a bug in sp_Blitz until I dug deeper:
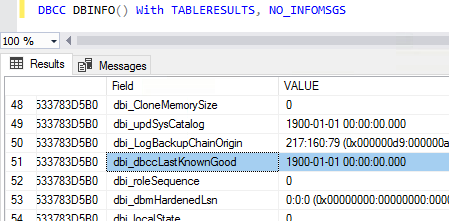
When they say the robots are taking your job, I guess they’re doing exactly the same kind of job you would do. Don’t lie: I’ve seen a lot of your servers, and you suck at corruption detection and recovery too. The robot is taking your exact job. Probably going to take smoke breaks even though he doesn’t smoke, just like you.
Note that neither maintenance plans nor Ola Hallengren’s maintenance scripts will work in MIs yet either: MI’s SQL Agent doesn’t support those kinds of scheduled tasks yet. (Props to Erik for catching that one.)
MIs might have a first line of defense in Automatic Page Repair. With mirroring and AGs, when the primary detects corruption, it’ll ask the secondary replicas for a clean copy of the page, repair it on the fly, and log it in sys.dm_hadr_auto_page_repair or sys.dm_db_mirroring_auto_page_repair. So I wondered, if the new HA/DR fabric solution isn’t showing replicas in the usual AG replica DMVs, do we get automatic page repair? I bet we do, because the startup error log shows this:
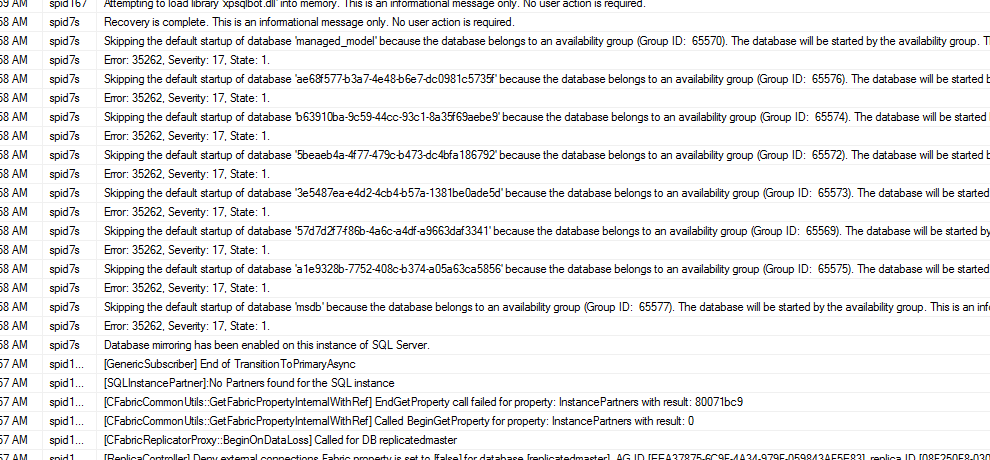
Note that even model and msdb are in that list, and in other parts of the log, master is shown as replicatedmaster. That’s kinda awesome – it’d be amazing if we get automatic page repair for system databases, too.
Side note – even with automatic page repair, if SQL Server writes trash data into the database, you end up with corrupt copies of the data everywhere. Classic examples include the 2012/2014 online index rebuild bug, the 2008-2014 UPDATE/NOLOCK bug, the 2008 compressed partitioned table bug, the 2008-2012 table variable bug, etc. These aren’t common issues by any means, and they’re all fixed today. However, for every bug, there was a range of time where it was active in the field and wasn’t fixed, and that’s what I’m worried about. No software is bug-free – so what happens when we hit a bug?
Let’s find out.
Testing Corruption of the Master Database
Corruption happens. It’s just a fact of life – storage is gonna fail. Microsoft’s SLAs for storage only give you 3-4 9’s, and there’s nothing in there about never losing your data. Nothing against Azure, either – I’ve lost entire VMs in AWS due to storage corruption.
So let’s demo it. Normally, this kind of thing might be hard to do, but at the moment, DBCC WRITEPAGE is enabled (although I expect that to change before MIs hit General Availability.) I used Erik’s notorious sp_GoAheadAndFireMe to purposely corrupt the master database (not TempDB. I modified it to work with a user database instead, ran it, and in less than ten seconds, the entire instance went unresponsive.
For the first 3-4 minutes, login attempts would fail:
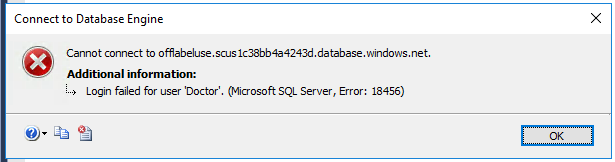
From 5-20 minutes, the connection started, but:
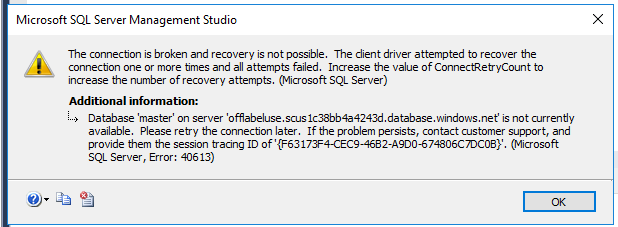
After half an hour, Object Explorer still couldn’t connect, but at least I could connect a query window to run connections, so I checked msdb.dbo.suspect_pages, and it was empty. However, CHECKDB() in master caused my connection to eject:
|
1 2 3 |
Msg 64, Level 20, State 0, Line 0 A transport-level error has occurred when receiving results from the server. (provider: TCP Provider, error: 0 - The specified network name is no longer available.) |
I sent the MI details off to Microsoft for analysis, and they’re working on a fix.
So what did we learn?
In traditional DR technologies like log shipping, database mirroring, and Always On Availability Groups, the fact that the master database isn’t replicated can actually be a good thing. When you fail over your user databases and only your user databases, you’re able to escape from system-database-level problems (or in the case of mirroring and log shipping, escape cluster-level problems.)
When you go with MIs, you’re gambling that Microsoft’s administration-as-a-service is going to be more reliable than your own administrators (with some tradeoffs around expense as well.) I think in the vast majority of cases, that’s a really, really, really safe bet. It’s not a guaranteed bet, though, as we see here.
Everybody has work to do. You need to run CHECKDB on your MIs, and Microsoft needs to improve compatibility to let you do it more easily, and corruption occurs, MS needs to do a better job of recovering – or give you some kind of plan B.
Because think for a second: what’s your disaster recovery plan for a Managed Instance failure?

7 Comments. Leave new
Hi Brent, thanks for the post. I followed some of those steps but to corrupt an user database and what I actually notice is that after the corruption, the MI is constantly restarting, let’s say every 20 seconds (not sure).
If we keep trying to connect eventually we get the connection (just before another restart) and straight after we can read the last few error logs. I am using the sp_readmierrorlog (https://github.com/dimitri-furman/managed-instance/tree/master/sp_readmierrorlog). With that I can see a dump stack and then a restart. Not sure why yet.
Rafael – OK, I’m not sure if you’re asking a question – if you have a question about Managed Instance behavior that you need support with, your best bet would be to contact Microsoft for support. Otherwise, can you rephrase it to make it more clear what you’re asking? Thanks!
Sorry for not being clear, Brent. That wasn’t a question, I was just bringing up the fact that MI is constantly restarting after/because of the corruption.
When I check the errorlog I can see all standard startup messages, then a stack dump and then the last messages in the errorlog before the restart is nearly always these:
Error: 40554, Severity: 10, State: 1. (Params:). The error is printed in terse mode because there was error during formatting. Tracing, ETW, notifications etc are skipped.
Exiting because of event ‘stack_trace’.
Then SQL restarts again, and so on. Probably you managed to get a connection during this small gap when the databases were online and accepting connections and before the shutdown. And when you say: “However, CHECKDB() in master caused my connection to eject”, what I think (and I just think) is that wasn’t the CHECKDB that caused your connection to eject, but the SQL shutdown (which was going to happen regardless the Checkdb).
That’s definitely an issue with MI tho and I am looking forward to hearing back from MS. 🙂
Thanks.
Rafael
OK, gotcha. Just to be clear, if you want a response from MS, contact MS. They don’t leave support answers on my blog. 😉 This post has been out for months, and they’re aware of the issue, but they don’t usually post support answers here.
haha I know that (even tho that’s unfortunate as they would probably have more views here than on their on blog), I have open a support request. Thanks for letting me know anyways 😉
Just over 5 years later, and I’d love to see a followup to this post. I’ve seen no new angle from MS and I check regularly because I’d love to disable these long checks on our instances. Even more annoying that we have no recourse if they find corruption other than open a ticket. Is the little bit of early warning worth the additional time & reads if we’re just bystanders anyway? Based on Miscrosoft’s EULAs, I doubt they’ll ever clarify because they “make no guarantees…”. Software isn’t real. Pay no attention to the PAAS behind the curtain (that you’re paying for).
When you say followup, what do you think has changed?