
kCura Relativity is a software product for law firms to find interesting stuff to help their case. To get you up to speed on what it does, here’s some of the posts I’ve written about Relativity in the past:
- Performance Tuning kCura Relativity – explains what the product is for and how DBAs can help make it faster
- Tiering kCura Relativity Databases – how to manage hundreds or thousands of Relativity databases
- Using Partitioning to Make Relativity Faster – when you have a 1TB+ workspace, this technique makes backups and maintenance easier
Today, I’m going to talk about the database mechanics – where data lives, and which tables you need to care about.
Relativity’s EDDS* Databases
The EDDS database stores Relativity’s system-wide configuration. (Just plain EDDS, no numbers or letters after it.) All of the users and processes will hit this database at various points of their work.
The EDDSResource database is like Relativity’s TempDB. I’m a huge, huge fan of this approach – this lets DBAs tune the EDDSResource independently from TempDB.
Each of the EDDS12345 databases (with a bunch of different numbers) is a legal matter, or in Relativity terms, a workspace. Think lawsuit or case, basically. As your lawyers take on new cases, each one will get its own new EDDS database.
You may also have an EDDSPerformance database, which houses kCura Performance Dashboard – a product that gathers performance metrics about your environment.
Distributed Environments: Spreading the Load Between SQL Servers
When you first get started, all of these databases could be on the same server. In the e-discovery business, though, growth happens really fast. Right from the get-go, you probably want to plan to separate them onto multiple SQL Server instances – in Relativity terms, a distributed environment with a couple of different SQL Servers:

We’ve got two SQL Servers, each with a couple of workspaces. (Obviously, Relativity scales WAY bigger than two workspaces on a single server, but I only wanna make these images so big, people.)
The EDDS database – the central config data – only lives on SQL1.
Both servers have their own EDDSResource database, and that’s for temporary scratch space.
But two standalone SQL Servers would be an insanely bad idea because if either server goes down, you’re screwed. Instead, you want to build a failover cluster of SQL Server instances, each instance living on a different physical box:
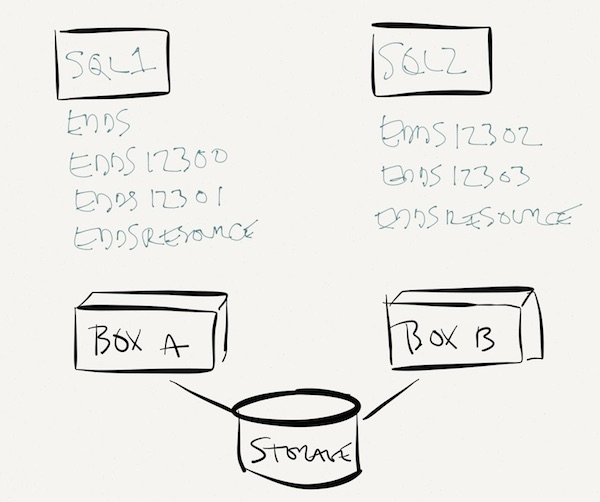
The databases live on shared storage, so if either box dies, the SQL Server instance can start up on the other box. Of course, this means you’ll have twice as many workspaces living on the same hardware, and that’s not a recipe for high performance, and you can mitigate that by buying a separate passive node. I’m not going into the intricacies of failover clustering here – for that, see our clustering resources.
How the EDDS Databases Affect Cluster Design
The EDDS database will consume performance resources. As your distributed environment grows larger and larger, the load on the EDDS database will increase. If other workspaces are sharing that instance, they may be bullied around by the EDDS database. In very large environments, the EDDS database may grow to the point where it needs its own SQL Server instance – or rather, you just don’t want to put any workspaces on that instance.
Any one workspace is confined to one database server. If you have a massive case going on with tens of terabytes of data, the load isn’t spread across the servers. One database still lives on just one host. While technically, SQL Server 2012 AlwaysOn Availability Groups does let you spread load across multiple servers, and technically Relativity 8.2 supports SQL Server 2012, they don’t support AGs for failover or spreading load yet.
You can move databases between servers to balance load, but it requires some downtime and work on the application side. You can’t just back up a workspace on one server, restore it onto another SQL Server, and take off. kCura has administration tools to help with this task, but it’s up to you to figure out which databases should be on which servers. This is where the concept of tiered workspaces comes in.
How to Performance Tune the EDDS Database
Because this database holds configuration data, and because the queries that hit here aren’t usually user-created, you generally don’t want to touch this database.
A few weeks after deploying a new release of Relativity, I recommend checking SQL Server’s index usage DMVs and plan cache to find out if there are any new problems that pop up. There may be a new query that needs a new index, or a unique way of doing a query in your environment that hasn’t been seen out in the wild yet.
When issues like that pop up, start by opening a support case with kCura rather than making index changes in here. In your support case, include the query text from the plan cache (if applicable) and evidence from your index DMVs to support the index change you want to make. You could actually make index changes inside this database, but generally speaking, that’s not a good first step. Let the Relativity support folks make the call there because any index changes here can dramatically affect all workspaces.
How to Tune the EDDSResource Databases
You don’t. It’s a temporary staging ground. You can skip this guy under most circumstances.
How to Tune the EDDSPerformance Database
Performance Dashboard is a relatively new product – at least compared to Relativity. Early versions of it desperately needed a few indexes, so using tools like sp_BlitzIndex® pay off big time here. I would highly recommend checking missing indexes in this database, but then after a couple of low-hanging-fruit indexes are applied, this database won’t be a performance issue.
Before making changes here, again, start a support case with the changes you’d like to make. In most cases, this is just a simple known issue and easy to fix.
How to Tune the Workspaces (EDDS* Databases)
Ah, now here’s the fun stuff.
Expanding on the process I discussed in my Performance Tuning kCura Relativity post, every database is a new case that goes through a lifecycle:
- The database is created. It’s technically restored from a “template”, a database that the users have set up as their standard starting point. Larger Relativity shops may have several templates to choose from.
- Some documents are loaded. We need to load data into the database server as quickly as possible.
- Users review the documents. They run searches looking for terms and attributes that might indicate evidence that would bolster their case. As they review documents, they make small edits to the metadata fields at the document level, like marking whether the document has been reviewed, who reviewed it, and whether or not it was interesting. We need to audit everything the users do (as well as things the system does, too.)
- We go back to step 2 a few times. More documents get loaded, and users run more searches. This cycle continues for some time, until the amount of documents trickles to a halt, but searches still continue for a while.
- The case becomes dormant. Legal matters can drag on for years, but we may need to keep this database online the whole time. The amount of changes drops dramatically – sometimes with no data changes for months or years – but the database has to be online, and it has to be backed up.
Some of the major tables in each EDDS* database include (and remember, lawyers, I’m simplifying this for the DBAs in the house):
- Document, File – things we loaded into Relativity to search through, like Excel files and Outlook PSTs
- AuditRecord_PrimaryPartition – a log of most Relativity events, like document loads or end user searches (when this is a problem, start by partitioning it out)
- Artifact – think of this like a system table for Relativity that lists every Document, plus other system objects
- CodeArtifact – prior to Relativity v8, this one table stored records for all choices for every Document. (Think multiple-choice fields, like what kind of file type it was.) This had scalability limits because it had multiple times more rows than the Document table, and query plans could get ugly. This was changed in Relativity v8, but I’m mentioning it here in case any of you out there are still on 7.5. (Get on this level.)

Index tuning isn’t necessary on most of these tables because the queries that hit these tables are all managed by Relativity itself. The kCura developers sit around the office trying to figure out how to make those queries go faster, and they come up with some pretty good ideas. (Well, they also surf my site when they’re bored. Did I mention that they’re attractive people?) You shouldn’t need to touch indexes or queries here, other than the same every-new-version check that I described about EDDS.
Except for the Document table.
Oh, boy, the Document table.
Why the Document Table is Fun to Tune
Relativity lets end users write whatever crazy searches they want against the Document table. Wanna find every email with “S” in the email address? You got it. Need to see every PowerPoint created in June last year? Can do. Interested in every file whose extension is MP4 but the data is actually a PowerPoint slide deck and has hidden slides? No problem. You can build these searches in a GUI without understanding anything whatsoever about how SQL Server works, and Relativity will build the T-SQL for you.
To make matters even more fun (HA! see what I did there, lawyers? “matters”, oh, I kill me), the end users can add new fields to the Document table any time they want. If they want to add a new decimal field called LooksSuspicious, it happens with no DBA intervention or change request. Relativity generates the ALTER TABLE commands on the fly, and then users can populate that field and run searches against it.
Index tuning becomes really challenging because we may never be done loading documents. To load documents, we want as few indexes as possible for faster insert speeds. To search for documents, we want lots of indexes so we don’t have to scan the Document table. As DBAs, we’d like to ask the users, “Are you done loading now? Because I can add indexes to make this go fast.” The answer with Relativity may always be, “No, I might load some more tomorrow.”
And what I find the most interesting is that every EDDS* database can be wildly different. Every team that’s involved with every legal matter may have totally different approaches to loading, searching, and managing their documents. That means you have to treat every EDDS* database as its own unique indexing challenge.
At any given time, you might have a hundred EDDS* databases, each for a different legal matter, each with their own Document table. Each has different numbers of fields and indexes in each case.
You can’t conquer each of these databases individually. You simply have to use my tiered workspace approach, define the small databases that will work just fine on their own, and go tackle the largest and most active databases with traditional index performance tuning methods.

8 Comments. Leave new
Thanks for this overview! Wrt the audit table archive database, do you also employ SQL server partitioning and read only file groups to speed archive db backups? Or are you just doing SAN backups when the archive db gets big?
Chris – glad you liked it. My main goal with Relativity is to make it easier to manage at scale, and techniques like partitioning and read-only filegroups – while powerful – are the opposite of “easier to manage at scale.” 😉 By the time a Relativity host needs to split out the audit table, they’re also facing multiple terabytes of data per server anyway, so they need to be well on the road to SAN backups.
Thanks for the great posts! Are there any good forums you would recommend for administrating a Relativity environment?
CW – yeah, get a login to their support portal. It’s very active.
Good man
Wow, this is fantastic. I always used to wonder about this distributed sever, you explained it so clearly.. Thank you, Brent
Hi Brent,
I have noted the date on this article and the posted video about designing an SQL Server to support Relativity and wonder: Is a failover cluster still the preferred method for high availability or can we start thinking in the direction of availability groups?
kCura give the impression that availability groups in 9.5 are supported but I still have my reservations especially when they are run in synchronous mode.
Regards,
Kev
Kev – yeah, I’d still recommend an FCI because databases are automatically protected as soon as they’re added. That’s not the case with AGs.