Performance Tuning
Find Recent Superstars: Answers & Discussion
Your query exercise for this week was to write a query to find users created in the last 90 days, with a reputation higher than 50 points, from highest reputation to lowest. Because everyone’s Stack Overflow database might be slightly different, we had to start by finding the “end date” for our query. I’m working with the 2018-06 export that I use in my training classes, so here’s my end date:
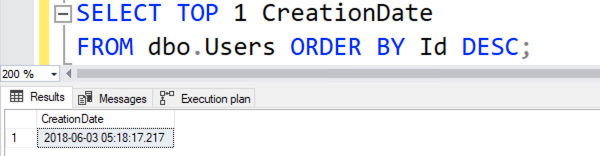
So if I’m looking for that date range, here’s the query I came up with:
|
1 2 3 4 5 |
SELECT TOP 1000 Id AS UserId FROM dbo.Users WHERE CreationDate > DATEADD(dd, -90, '2018-06-03 05:18:45.117') AND Reputation > 50 ORDER BY Reputation DESC |
You might have written a slightly different query, so of course your homework may start to diverge from mine. More importantly, EVERYTHING on your system might be different from mine, so the rest of our homework is going to diverge a LOT. Here’s how my system is configured:
- SQL Server 2022 Developer Edition
- 2018-06 Stack Overflow database in 2022 compatibility level
- Cost Threshold for Parallelism 50 (and changing that, changes the query plans a LOT in this example)
Question 2: Does It Perform?
The second part of our challenge was to compare the number of logical reads that our query does, versus the number of reads it would take to just scan the whole table. Let’s find out:
|
1 2 3 4 5 6 7 8 9 |
SET STATISTICS IO ON; SELECT TOP 1000 Id AS UserId FROM dbo.Users WHERE CreationDate > DATEADD(dd, -90, '2018-06-03 05:18:45.117') AND Reputation > 50 ORDER BY Reputation DESC /* Versus a table scan: */ SELECT COUNT(*) FROM dbo.Users WITH (INDEX = 1); |
The results:
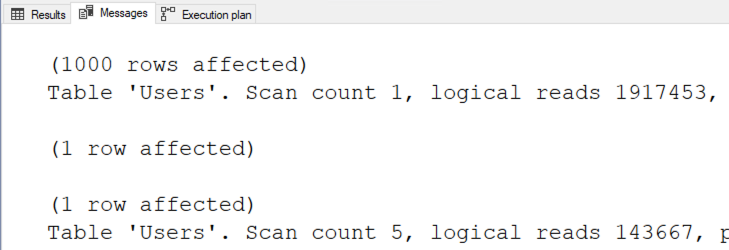
Redmond, we have a problem. Our query is doing more reads than scanning the entire table ten times over! What the hell does my execution plan look like?
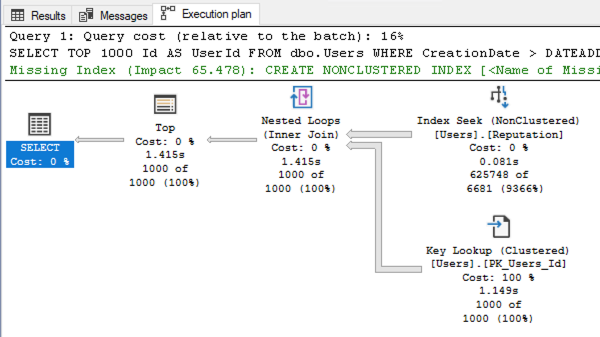
SQL Server is seeking on Reputation, and then scanning backwards from high values down to low. Check out those estimated-versus-actual numbers on the index seek:

SQL Server thought, “I’m going to scan from high reputations to low. There are a LOT of people with Reputation > 50, and there are a LOT of users created in the last 90 days, so I bet I won’t have to check too many CreationDates on the key lookups before I’ve found 1000 users that match.”
The core of the problem is that:
- There are a lot of users with Reputation > 50
- There are a lot of users with CreationDate > ‘2018-06-03 05:18:45.117’
- But SQL Server doesn’t know there isn’t a lot of overlap in those two groups.
Fun Trivia About Parallelism
This query plan doesn’t get parallelism because SQL Server doesn’t use parallelism for backwards range scans, something I learned from Paul White’s excellent post. To see the scan direction, right-click on the Index Seek operator and click Properties, and check out the scan direction:

Neato mosquito. Anyway, moving on.
Question 3: Making It Perform Better
The core of this week’s problem is cardinality estimation: SQL Server doesn’t understand that there’s very little overlap in the Venn diagram’s circles for high Reputation and recent CreationDates. Your first instinct is probably to solve that problem, but let’s step back for a second. If a table scan performs better than using an index…

|
1 2 3 4 5 |
SELECT TOP 1000 Id AS UserId FROM dbo.Users WITH (INDEX = 1) WHERE CreationDate > DATEADD(dd, -90, '2018-06-03 05:18:45.117') AND Reputation > 50 ORDER BY Reputation DESC; |
By adding an INDEX = 1 hint, we can force a table scan, and cut our logical reads by 10X. (And for bonus points, we even get parallelism.)
The drawback to this solution is that if the indexes change later, and a better index presents itself, our query won’t be able to use it. But hey, the whole point of this exercise was that we weren’t able to change the indexes. Sometimes at clients, I’m dealing with very mature databases with a core set of indexes that are needed to support a workload, and we can’t juggle indexes just to fix a single SQL Server estimation problem. In that case, Skeletor wins.
In Case You’re Not a Skeletor Fan
We do have indexes on CreationDate and Reputation. What if we have SQL Server find the people who match each filter individually, and then find their overlaps first before doing the key lookups? That’s the solution Peter Kruis went for:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
WITH CTE AS (SELECT u.Id FROM dbo.Users AS u WHERE u.Reputation > 50 INTERSECT SELECT u.Id FROM dbo.Users AS u WHERE u.CreationDate >= DATEADD(DAY, -90, '2018-06-03 05:18:17.217')) SELECT TOP (1000) u.* FROM CTE AS c JOIN dbo.Users AS u ON u.Id = c.Id ORDER BY u.Reputation DESC; |
The first part of his query plan is the CTE, which finds the reputation and creationdate people separately:

Note the estimates vs actuals on the join of the two result sets. SQL Server thought there was a lot more overlap in the Venn diagram: SQL Server expected to find 45301 rows, but only found 2644. But here’s the cool part: it doesn’t matter that the estimation is wrong here, because there are no key lookups here to get screwed up, no memory grant problems, etc.
Peter’s rewrite drops down to about 10,000 logical reads – about 14x better than Skeletor’s approach, and about 200x better than SQL Server’s original approach.
Peter rewrote the query with the knowledge of the indexes that were present on the database. Peter’s approach works well because there are separate indexes on Reputation and CreationDate. If a single covering index got added in later, Peter’s approach wouldn’t be able to leverage it to perform well – but that’s okay, after all, because remember that we said we can’t touch indexes in this challenge. This is a good, typical approach I use in mature databases where I can rely on the indexes to stay fairly stable over time.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
[…] Post your solutions in the comments, and feel free to ask other folks questions about their solutions. If your solution involves code and you want it to look good, paste it as a Github Gist, and then include the Gist link in your comment. Then, check out my answers & discussion. […]