
I first knew something was up when I looked at the job history for a simple maintenance plan. It had two steps:
- Rebuild all the indexes in the database – this took 10 minutes each night.
- Update statistics – this took 2-3 hours each night.
What was going on? Statistics in SQL Server are small, lightweight objects. Indexes are larger and contain more data. Why would updating statistics take so much longer?
Maintenance Plans light the fuse
I love the concept of maintenance plans, but I don’t love the way all the tasks are set up.
In the case I was looking at, the Update Statistics task was being used with two values that are set by default:
- Run against all statistics
- Update them with fullscan

“All” statistics means that both “column” and “index” statistics will be updated. There may be quite a lot of statistics — most people leave the “auto create statistics” option enabled on their databases, which means that queries will dynamically cause the creation of more and more statistics over time.
Combined with “fullscan”, updating all statistics can become a significant amount of work. “Fullscan” means that to update a statistic, SQL Server will scan 100% of the values in the index or column. That adds up to a lot of IO.
Why ‘SELECT StatMan’ repeatedly scans tables
If SQL Server needs to update column level statistics for the same table, it could potentially use a single scan and update multiple stats, right?
Because of the runtimes I was seeing, I was pretty sure that wasn’t happening. But we can take a closer look and see for ourselves.
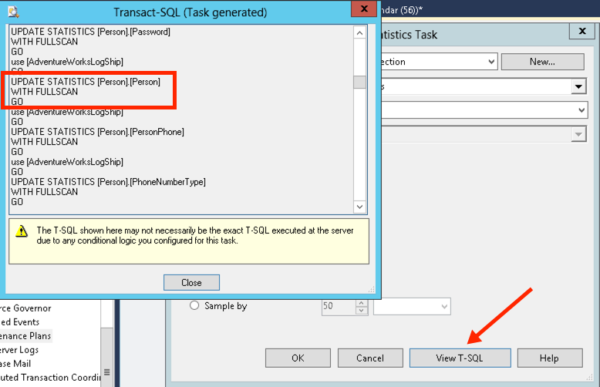
In our maintenance plan task, if we hit “View TSQL”, a window pops up showing us the comamnds that the plan will run. (I love this feature, by the way!) We will use one of these commands to test things out in a bit.
First, let’s make sure we have some column level statistics on our database. It already has indexes and their associated stats. To create some column level stats, I run these queries:
|
1 2 3 4 5 6 7 8 9 10 |
--create two column stats using 'auto create statistics' select * from Person.Person where MiddleName like 'M%'; select * from Person.Person where Title is not null; GO --Create two filtered stats on Title create statistics kl_statstest1 on Person.Person (Title) where Title = 'Mr.' GO create statistics kl_statstest2 on Person.Person (Title) where Title = 'Ms.' GO |
That will create two “auto” stats what start with “_WA_Sys”, and two stats that I named myself. To check ’em out and see ALL the index and column stats on the table, we run:
|
1 2 |
exec sp_helpstats 'Person.Person', 'All'; GO |
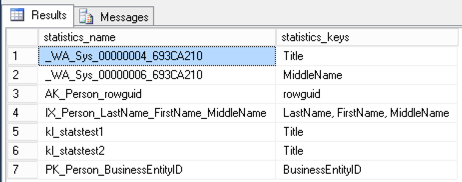
Sure enough, this shows us that we have seven stats total– three are related to indexes.
Alright, time to run that sample command excerpted from our maintenance plan. I start up an Extended Events trace to capture IO from sp_statements completed, then run the command the maintenance plan was going to use to update every statistic on this table with fullscan:
|
1 2 3 |
UPDATE STATISTICS [Person].[Person] WITH FULLSCAN GO |
Here’s the trace output –click to view it in a larger image:
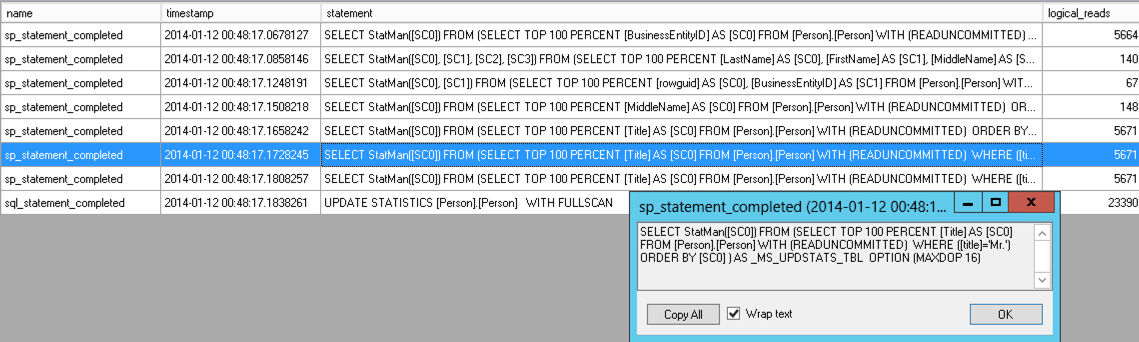
Looking at the Extended Events trace output, I can see the commands that were run as well as their logical reads. The commands look like this:
|
1 2 3 4 5 |
SELECT StatMan([SC0]) FROM (SELECT TOP 100 PERCENT [Title] AS [SC0] FROM [Person].[Person] WITH (READUNCOMMITTED) WHERE ([title]='Mr.') ORDER BY [SC0] ) AS _MS_UPDSTATS_TBL OPTION (MAXDOP 16) |
The “logical_reads” column lets me know that updating four of these statistics had to do four separate scans of my table– and three of them are all on the Title column! (Doing a SELECT * FROM Person.Person shows 5,664 logical reads by comparison.)
IO was lower for statistics related to nonclustered indexes because those NC indexes have fewer pages than the clustered index.
A better way to update statistics: Let SQL Server pick the TABLESAMPLE
If you just run the TSQL command ‘UPDATE STATISTICS Person.Person’ (without telling it to scan all the rows), it has the option to do something like this:
|
1 2 3 4 5 6 7 8 |
SELECT StatMan([SC0], [SB0000]) FROM (SELECT TOP 100 PERCENT [SC0], step_direction([SC0]) over (order by NULL) AS [SB0000] FROM (SELECT [Title] AS [SC0] FROM [Person].[Person] TABLESAMPLE SYSTEM (3.547531e+001 PERCENT) WITH (READUNCOMMITTED) ) AS _MS_UPDSTATS_TBL_HELPER ORDER BY [SC0], [SB0000] ) AS _MS_UPDSTATS_TBL OPTION (MAXDOP 1) |
It dynamically figures out a sample size by which to calculate results! (It can pick a variety of options– including scanning the whole thing.)
How to configure faster, better statistics maintenance
Avoid falling for the pre-populated settings in the “Update Statistics” task in the maintenance plan. It’s rare to truly need to use FULLSCAN to update stats in SQL Server, and even when cases where it’s justified you want to implement that with statements targeting the individual statistics to update. The basic “UPDATE STATISTICS Schema.TableName” command is pretty clever– the issue is simply that Maintenance Plans don’t make it easy for you to run that!
Unfortunately, if you use maintenance plans there’s no super simple solution– it forces you to specify either fullscan or a specific sample. There’s no way to just use the basic “You compute the minimum sample” with that task.
You’ve still got good options, they’re just a few more steps:
- You could use a t-sql related task or a custom SQL Agent job to run sp_updatestats
- You could use a free index and statistics maintenance script. The example I’ve linked to is super clever, and avoids updating statistics where it has just rebuilt an index!
- You could also let auto update stats take care of the issue– that’s often just fine on small databases or where there aren’t major data fluctuations
And each of those options should chew up less IO than updating all index and column statistics with FULLSCAN.

91 Comments. Leave new
I actually had a strange performance issue result from stats being updated this morning – a job went from 44 minutes right after the update took place. First thought: developers deployed something 😉 After a little analysis and a new NC index, all was well. After that, however, I still wanted to find out what happened so I turned to my maintenance jobs.
To investigate my index/stats maintenance history, I have a report I created to query Ola’s logging table if anyone is interested. Turns out the table I put an index on had it’s stats updated, obviously throwing the execution plan out of whack. You would have to update the data sources and parameter defaults, but that’s about it.
http://allen-mcguire.blogspot.com/2014/01/rdl-for-olas-index-maintenance-logging.html
Ah – posts don’t like greater than/less than signs – job went from under a minute to over 44 minutes 😉 Some of my words got hacked out.
Allen–
That link no longer goes to the article on your website. Do you still happen to have the post?
CW
The URL looks like it’s just been updated. Here’s an updated link, or you can search for the term RDL on his blog in the search box at the top right.
Thanks Kendra
So would you recommend to SET AUTO_CREATE_STATISTICS OFF ?
Hi Klaas,
I recommend leaving that ON — statistics are extremely helpful to the optimizer for query plan quality.
I just wouldn’t update all your statistics with fullscan. The statistics are good and lightweight, but the maintenance plan task isn’t great.
Hope this helps!
Kendra
OK
I started doubting because of ‘most people leave the “auto create statistics” option enabled’.
I even never looked at maintenance plans. The day I became a DBA I started searching the internet and since that day Ola’s been doing my maintenance for me.
Not long after that I found you and your colleagues.
I thank you for your answer and even more for helping me every day of the last two years.
Do you recommend using sp_updatestats with the resample parameter?
I’m not a huge fan of the Resample option. Let’s say someone’s troubleshooting an issue and they try updating statistics on an index with fullscan to see if it solves a problem.
It doesn’t solve the problem, but suddenly ‘resample’ is now being applied by maintenance repeatedly. And probably the person who was doing the test doesn’t even realize that they caused a change.
If there are individual statistics which need a higher sample, I like to have an agent job update those specifically with documentation about what issues are corrected — because there’s always a chance that the queries they help won’t even be run in a few years.
Hi Kendra,
I am using update statistics with resample repeatedly but it often happens the maintenance is stopped midway due to time constraints (going onto business hours)
Does this affects the db maintenance when I re-run the update stats with resample on the next available slot?
Meera – yes, make sure you’re using Ola Hallengren’s index maintenance scripts so that you’re not updating statistics that have already been updated recently: https://ola.hallengren.com
Thanks Brent.
Not sure if this is a stupid question. Can we ever consider deleting the auto created statistics ( _WA_Sys_) if the update statistics query is taking too long to complete? I have tables with above 200 auto created statistics!
Would this have an impact on the system performance?
Meera – for questions, head on over to a Q&A site like https://dba.stackexchange.com. Hope that helps!
How does SQL server choose “OPTION (MAXDOP ??)” when running “UPDATE STATISTICS Schema.TableName” and sp_updatestats?
Is there a way to override this? I suspect I can fasten my stats update if I can set maxdop setting manually.
Check out Paul White’s answer to this stackexchange question for the answer to this: http://dba.stackexchange.com/questions/20387/parallel-statistics-update
As an aside, if you use Ola’s scripts to update your statistics periodically, there is an option to pass in MAXDOP if you wish. It’s pretty slick.
http://ola.hallengren.com/sql-server-index-and-statistics-maintenance.html
You can pass in a MAXDOP hint, but that’s really for the index scripts.
Have you actually checked and verified that it impacts the specific maxdop on the statistics update? If you read Paul White’s answer that I linked to, you’ll see he mentions that there’s no way for the user to specify the maxdop hint manually, which is what I have observed as well.
Good point Kendra – I haven’t run a trace on the script so I’m not certain, but I trust your observations and Paul’s analysis are correct 😉
Would you recommend to SET AUTO_CREATE_STATISTICS ON for TBs sizes databases?
(In my cases, they are about 5TB for Main DB and 1TB of Staging DB)
Mahesh – I’d turn that around and ask two questions:
1. Do you care about query performance in those databases?
2. Are the tables fairly mature, meaning you’re not changing the entire contents of the tables every day?
Unless your applications fully handle creating statistics and you can know for certain that you have statistics for all the queries that need it, don’t turn off the automatic creation of statistics.
Appreciate your quick responses. I was weighting switching to handle the stats update using maintenance script vs my current DB setting which is set ON (assuming the auto update is interfering my OLTP/batch job perf.). We do have index maint. jobs and fragmentation on tables are very low <5%. MAIN DB is active 500+ user OLTP systems having 100s of transactions per minute, few are batch imports, etc and some query run/do lookup on transaction tables. Lately the system is reporting poor perf., we are investigating other aspects, along this.
Is there a way to find out if the auto update stats is interfering/hampering perf?
One quick observation: Statistics creation and statistics update are very different things, and it sounds a bit like you’re confusing them.
For some performance considerations on updating statistics, you should read this post: https://www.brentozar.com/archive/2014/01/update-statistics-the-secret-io-explosion/
Sorry for the confusion (typo/copy paste mistake), my initial q was for AUTO_UPDATE_STATISTICS.
I periodically run a profiler trace and monitor “Auto Stats” just to get a feel for whether or not there is excessive auto updates of stats going on. In some cases the application design is such that tables are constantly inserted/deleted from so the stats were perpetually updating, which likely would lead to performance issues. In very particular cases I disable the auto-update of stats on tables using sp_autostats – I never disable it at the database level.
There are so many ways this approach could backfire, I’m not even sure where to begin.
It also works in many cases where you have a very small table that’s inserted/deleted from very, very often. It does work, but it’s not someone for the inexperienced – agree.
Just for other readers of the comments, Allen and I tend to disagree on just about everything related to performance tuning– and disagreement is a good thing! There’s no one single approach to performance tuning or managing a SQL Server and my way definitely ain’t the only right way.
I moderate the comments on my posts and note where I wouldn’t recommend the approach just so it’s clear what the author thinks is risky or not.
Guys,
Excellent job, I was passing for this issue and when I looked this post I solved all my problems. Thank you.
What would be the impact if Update Statistics (with full scan) job stopped?
Using SQL standards edition (64-bit)
Possibly there would be no impact. Possibly queries might perform differently.
Thanks for quick reply… no impact mean could be no data or statistics corruption?
Why queries might perform differently?
To answer this question you need to understand what statistics do in SQL Server. You can learn that by watching Jes’ video here: https://www.brentozar.com/archive/2014/12/video-statistics-beyond-performance/
I’ve read articles showing that at fullscan, update statistics can run in parallel. We have a 4 TB database and my research indicated we would have to drop below 50% sample rate to get as much work done in a given time as fullscan. Over years of working with our developers on this application, we’ve concluded that sql server’s default sample rate ( very very low ) just wouldn’t work for us.
We’ve been updating stats with fullscan for a few years now, and the only “downside” is seeing high IO in tempdb ( in particular ) during the maintenance window. But no blocking or deadlocks.
You would only see blocking if the statistics maintenance blocked something else (such as a reindex command) , which then blocked other things.
How long is your maintenance window, and how long does your update of statistics with fullscan take?
Randy,
I appreciate your input. We’ve been using Ola’s index stats scripts for a while but have recently had some really bad situations with pegged CPU and horrible DB performance across the board. There was no degradation, just night and day crap performance on all queries. Microsoft had to be engaged and each time they asked me about stats I said sure we update them nightly(with the method Kendra mentions here). And then they update them with a full scan (along with a few indexes which weren’t required the day before) and boom everything is back to normal. Once I saw your comment about their sample being too low I’m now suspicious of this as well. We may have to go to fullscan all the time too.
We use Ola Hallengren’s indexoptimize in a slightly customized way. Its limited to 3 hours on weeknight’s and certain huge indexes are excluded. Those are processed on Saturdays where it is limited to about 8 hours.
In both windows I create a temp table of statistics that have been modified, ordered with highest modification ratio first
AND ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2)>.5
AND sp.rows>50000
ORDER BY ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2) DESC,last_updated
Then indexOptimize is called for a single statistic in a cursor loop.
@UpdateStatistics = ‘ALL’,
@Indexes = @tablecommand,
@OnlyModifiedStatistics = ‘Y’,
@StatisticsSample= 100,
@TimeLimit = 1800,
@MaxDOP = 8,
@LogToTable = ‘Y’,
@delay=1
Would you be willing to share your script that limits the amount of time that the maintenance jobs are allowed to run? We have a large database and would like to limit updates to non peak hours.
Just in case Randy isn’t subscribed to comments, the IndexOptimize script is here by Ola Hallengren: https://ola.hallengren.com/sql-server-index-and-statistics-maintenance.html
Thanks for the link!
I had gone through that page, but didn’t find TimeLimit in the list of parameters – turns out it is only documented by example G – “Rebuild or reorganize all indexes with fragmentation on all user databases, with a time limit so that no commands are executed after 3600 seconds”.
Our database is a bit big and maintenance jobs without a stopping point will run into prime hours.
I’m hoping to engineer a method which will allow IndexOptimize to update statistics on a table by table basis pausing at the end of the maintenance window, then pick up again at the beginning of the next window where it stopped.
Oh, I don’t think it’s restartable by default. You could email Ola and ask if he has recommendations for that– he’s really responsive and helpful.
I looked this up because I was seeing a large amount of CXPACKET waits during the update statistics window even though the MAXDOP in our environment is set to 1 (I know, don’t lecture me – this is Dynamics AX and the folks who installed it are following guidelines that I am investigating). I read the stackexchange posting and it indicates that these stats ‘can’ be run in parallel. It appears to me that they are being run in parallel, but I don’t see the MAXDOP hint in the generated SELECT as indicated in the posting. Is it there but I don’t see it?
There’s no shame in MAXDOP 1 when it’s a vendor app written specifically for that setting and tested with it. 🙂
Why are you worried about CXPACKET waits in a maintenance period?
For several reasons:
1. In a global company the maintenance window Is shrinking and overlaps production.
2. I always want to know the deal with waits that are high
3. Curiosity
If the generated SQL had the option I would not have asked. The steps before and after in the MP turned the MAXDOP to 0 and 1 respectively though that should not matter according to what I read. Could you please just let me know if you have the answer?
Thanks
I’m not trying to be tricky– what you see in the screenshots in the post is what I’ve seen, where the hint appears. If you Google this and read other sources about this, they also mention the maxdop hint.
I’m just not sure how I can provide more info than the screenshot in the post, so I was looking for more info on what the problem was, which can sometimes lead to a more complete answer.
Other than the extra time and i/o load of a FULLSCAN, is there ever a disadvantage of doing a FULLSCAN vs a SAMPLE? I’ve been running under the assumption that if you have time, do the FULLSCAN, since it’s the most complete and therefore the most accurate. Otherwise, how do you determine whether it’s ideal to do a SAMPLE vs a FULLSCAN?
Hi Jay,
It’s a little bit like taking two Advil a day in case you get a back ache. If you start getting performance pains and you’ve already loaded up your maintenance window until it’s full, you have less room to negotiate. You also have no idea if things will get worse if you stop taking the Advil, and you’re REALLY not going to want to do that if you’re in pain.
Most applications and tables are fine with statistics updates done with a default sample. The question to ask is if your queries are fast enough and performance is good enough with minimal preventive maintenance, and only start taking medicine if it’s needed.
Kendra
Hi,
My Trace File Showing Lot of SELECT StatMan([SC0]) FROM (SELECT TOP 100 PERCENT of ….rows after insert statement to the temp table which increases the logical reads. How to avoid it.
What are you thoughts of doing an Update Statistics WITH FULLSCAN after a backup from 2008, restore to 2012 operation?
If you have enough time and it makes you feel better, I have no objection. 🙂
Does anyone know why Sql Server chooses such a low sample rate when auto updating statistics? It’s often well under 1%. Fast but not good. We’ve had to manually update our stats on larger dbs for some time now. We’re running it on our BI server on some of the staging databases and we have been running into schema locks.
Paul – it chooses lower sampling rates to save time when your tables grow to large sizes, and also when it’s been bossed around by someone previously picking smaller statistics sampling rates when manually resampling the table.
Thanks Brent, I guess the question is, why would it choose a value so low as to be statistically invalid? And if this causes problems for us, surely it causes problems for many others out there. If we can’t trust that the statistics are going to be representative (read, accurate) then having auto update stats seems pretty useless. Or am I being melodramatic?
Paul – because it might still be a valid rate. For example, if I’m sampling a list of GUIDs, I don’t need to scan the whole table to understand what they’re going to look like.
Hi All,
I am perusing this site to learn more about sql statistics. I am a statistician, so I thought I would clarify one thing: the percent of a population that is sampled is usually not particularly relevant to the precision or accuracy of the statistics.
The precision and accuracy of the sample depends on the number of elements in the sample (assuming that they are sampled randomly). The sample size depends on the precision that you need. This is why surveys can get a decent representation of a population with a couple thousand people, whether the population being represented is Peoria, the US, or China. The population size is almost irrelevant.
Two caveats:
1. If the population is finite, and you sample everyone, there is no uncertainty. The uncertainty is only about the guys (gender neutral) that you don’t sample, so sampling almost everyone can reduce uncertainty. For very large populations, though, once you sample (say) 10,000 elements your estimates are generally very precise. This caveat leads to what is called a “finite population correction,” but if you are dealing with millions of records, there is not much to be gained by sampling (say) half the records over sampling only about 10k. Note that for your purposes, the population of interest is all future data as well as what you have now. Unless your database is pretty static, the population is better considered infinite (all the data you may ever get).
2. If your population is quite heterogeneous along some lines that you can identify, you may benefit from a stratified sample. For example, attitudes of students who apply to college and those who do not may differ substantially, so a national estimate would benefit from separately sampling within these groups (where the set of all non-overlapping groups represents the full population) and then putting the estimates together.
I have no idea what SqlServer does in this regard, but would like to.
Jon – thanks for stopping by, but when you’ve got questions, your best bet is to post them to a Q&A site like http://dba.stackexchange.com rather than commenting on an unrelated blog post.
If auto create statistics ON creates a new column statistic every time someone includes a non-indexed column in the WHERE clause, I imagine a lot of column stats get created for one-off queries that are subsequently used rarely, or never.
Is there any established process for identifying column statistics which are just along for the ride, and perhaps removing them? Sort of like the unused index section in sp_blitzindex?
Thanks!
Andre Ranieri
There’s no DMV that records when statistics were last used. Column statistics are also extremely lightweight as long as you don’t have maintenance that’s updating them needlessly with fullscan– so much so that I don’t ever worry about dropping them.
Hi All,
Can we stop update statistic query on maintenance plan.I have started this activies on 26th evening.Till it is running .Our MS SQL 2008 R2 database size is 4.5 TB.Now it was running slow.Can we stop it and if we stop it manally what is problems comes.Kindly tell me ASAP.
Thanks
Laxmi Narayan Padhy
Laxmi – whenever you’ve got urgent support questions, rather than leaving a note on a blog, your best bet is to call Microsoft support. It’s $500 USD, and they work the problem with you until it’s fixed.
If that’s too much money, then head over to http://dba.stackexchange.com and post your question there. Hope that helps!
We use ola.hallengren maintenance plans on enterprise edition (2008 R2 SP4) nightly with online indexes and update modified [column and index] statistics with fullscan…
Does updating the statistics cause the execution plans in large stored procedures to become invalidated? That is, with an sp that we created a week or a month or a year ago with a handful of complex queries and temp tables, will it experience degraded or improved performance after a stat update? Would we need to do anything to the sp’s in order to update them and have them recompute an execution plan and save that into the sp? Will simply running the sp for the first time after a stat update save the new/updated execution plan into the sp even though we are not manually running an alter procedure? Thanks! Awesome article.
Yep – updating statistics can cause queries to recompile. It may be individual statements within a stored procedure and not every statement in the procedure. You don’t need to do it manually.
I do recommend using the parameters Ola has to manage stats update in the index maintenance script and not doing it as a separate step.
Sometimes improved estimates can lead to worse query performance, so for the complex procedure with lots of queries and temp tables the stats update could possibly make no difference, make it faster, or make it slower, it’s hard to say.
Kendra, thanks. We indeed are using the stat parameters in Ola’s scripts and not as a separate step. Thanks for your insights!
So, a little about Ola’s scripts. Love the IndexOptimize optimize proc, but a word of caution on the turning on INDEXing option. When I queried command log, all the update stats seemed to be very short, but the overall job run was over 5 hours. We noticed statistics was taking 3 of the 5 hours, even with @OnlyModifiedStatistics = ‘Y’. There seems to be a lot of overhead in his stats portion, so we disabled it for now, as it’s getting in the way of other maintenance, and either will replace it with sp_updatestats or modifying something like this, where it picks sample size based on number of rows on the table.
Any thoughts on what could be happening?
Gaby – well, let’s think methodically about this. If a query is running slow on your SQL Server, what would you do to troubleshoot that?
In this case, CommandLog shows UPDATE STATISTICS [stat name] with no arguments, meaning it is calculating a sample size before that step, which is where my current suspicion for “lag” is, although I’m researching some other issues from the sysadmins to eliminate anything external. Apologies, with a normal user query, there are a whole host of options such as sp_whoisactive, dbcc inputbuffer, dbcc opentran, and of course, DMV’s, but with something like this, a trace may be the only option?
One more thought on this. I had my Indexing options set to: ‘INDEX_REORGANIZE,INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE’. I just confirmed that a large number of my update stats are occuring right after a REORGANIZE. I found the other Ola article you posted and will try this option sequence you recommend instead: ‘INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE,INDEX_REORGANIZE’
Gaby – okay, go ahead and pick up the book Troubleshooting SQL Server by Kehayias & Kreuger, or watch our Developer’s Guide to SQL Server Performance video class at https://learnfrom.brentozar.com.
Here is an example of how I use Olla’s procedures. StatsToSkip is a list of statistic names that relate to columns containing large strings of XML or “raw” data.
USE myDatabaseName
GO
IF OBJECT_ID(‘tempdb..#StatsToCheck2’) IS NOT NULL
DROP TABLE #StatsToCheck2;
SELECT [so].[name] AS [TableName],
–[sch].[name] + ‘.’ + [so].[name] AS [TableName],
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated],
[sp].[rows] AS [RowsInTable],
[sp].[rows_sampled] AS [RowsSampled],
[sp].[modification_counter] AS [RowModifications],
CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18,2)) AS [PercentChange] ,
ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2) AS percentTwo
INTO #StatsToCheck2
FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON
[so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties] ([so].[object_id], [ss].[stats_id]) sp
WHERE [so].[type] = ‘U’
AND [so].[name] NOT in (‘TableNotNeedingMaintenance’)
AND ss.NAME NOT IN (SELECT statname FROM admin.dbo.statstoskip) –AND SP.last_updated.5
–AND sp.rows>5000000
ORDER BY ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2) DESC,last_updated
— select * from #statstocheck2
USE master
go
declare @maxDurationInMinutes int
set @maxDurationInMinutes= 600 —- ten hours = 600 minutes maximum for entire operation
DECLARE @starttime DATETIME;
SET @starttime = GETDATE();
DECLARE @db SYSNAME
SET @db = ‘MyDatabaseName’
DECLARE @tbl SYSNAME
DECLARE @stat sysname
DECLARE @tablecommand VARCHAR(200)
DECLARE c CURSOR READ_ONLY
FOR select tablename,Statistic from #StatsToCheck2
OPEN c
FETCH NEXT FROM c INTO @tbl,@stat
WHILE (@@FETCH_STATUS = 0 and DATEDIFF(MINUTE, @starttime, GETDATE()) 0
ROLLBACK
— Raise an error with the details of the exception
DECLARE @ErrMsg NVARCHAR(4000)
,@ErrSeverity INT
SELECT @ErrMsg = ERROR_MESSAGE()
,@ErrSeverity = ERROR_SEVERITY()
RAISERROR (
@ErrMsg
,@ErrSeverity
,1
)
END CATCH
FETCH NEXT FROM c INTO @tbl,@stat
END
CLOSE c
DEALLOCATE c
IF OBJECT_ID(‘tempdb..#StatsToCheck2’) IS NOT NULL
DROP TABLE #StatsToCheck2;
HI,
I need to update my statistics almost every for some tables, because the execution query takes around 50 minutes instead 10 Sec and there are small tables, how can i prevent this situation? those tables where i need to update the statistics have data chantes (Update, insert , delete) i dont want to disable the auto create stats: because other Plans can be affected. my last option is create a process to update the stats everty 1 day. Is there other option?
Salvador – sure, it’s time to start learning the fun of execution plans! Start here:
http://www.sommarskog.se/query-plan-mysteries.html
Well I see above I completely left out the call to Olla’s IndexOptimize stored procedure
USE mydatabase
go
IF OBJECT_ID(‘tempdb..#StatsToCheck’) IS NOT NULL
DROP TABLE #StatsToCheck;
SELECT [so].[name] AS [TableName],
–[sch].[name] + ‘.’ + [so].[name] AS [TableName],
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated],
[sp].[rows] AS [RowsInTable],
[sp].[rows_sampled] AS [RowsSampled],
[sp].[modification_counter] AS [RowModifications],
CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18,2)) AS [PercentChange] ,
ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2) AS percentTwo
INTO #StatsToCheck
FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON
[so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties] ([so].[object_id], [ss].[stats_id]) sp
WHERE [so].[type] = ‘U’
AND [so].[name] NOT in (‘USER_ACTIVITY_LOG’,’OTTS_HISTORY_NEW’,’XML_SERIALIZED_INSTANCE’,’FILE_RECORD’)
AND ss.NAME NOT IN (SELECT statname FROM admin.dbo.statstoskip)
–AND CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18,2)) >= 1.00
AND ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2)>.5
AND sp.rows>50000
ORDER BY ROUND(CAST(100.0 * sp.modification_counter / sp.rows AS DECIMAL(18,2)),2) DESC,last_updated
USE master
go
declare @maxDurationInMinutes int
set @maxDurationInMinutes= 600 —- ten hours = 600
DECLARE @starttime DATETIME;
SET @starttime = GETDATE();
DECLARE @db SYSNAME
SET @db = ‘MyDatabase’
DECLARE @tbl SYSNAME
DECLARE @stat sysname
DECLARE @tablecommand VARCHAR(200)
DECLARE c CURSOR READ_ONLY
FOR select tablename,Statistic from #StatsToCheck order by [PercentChange] desc, [StatsLastUpdated]
OPEN c
FETCH NEXT FROM c INTO @tbl,@stat
WHILE (@@FETCH_STATUS = 0 and DATEDIFF(MINUTE, @starttime, GETDATE()) 0
ROLLBACK
— Raise an error with the details of the exception
DECLARE @ErrMsg NVARCHAR(4000)
,@ErrSeverity INT
SELECT @ErrMsg = ERROR_MESSAGE()
,@ErrSeverity = ERROR_SEVERITY()
RAISERROR (
@ErrMsg
,@ErrSeverity
,1
)
END CATCH
FETCH NEXT FROM c INTO @tbl,@stat
END
CLOSE c
DEALLOCATE c
IF OBJECT_ID(‘tempdb..#StatsToCheck’) IS NOT NULL
DROP TABLE #StatsToCheck;
Left it out again. Well in the cursor loop it executes this. We’ll see if the comment demons strip it out again:
EXECUTE master.dbo.IndexOptimize
@Databases = @db,
@FragmentationLow = NULL,
@FragmentationMedium = NULL,
@FragmentationHigh = NULL,
@UpdateStatistics = ‘ALL’,
@Indexes = @tablecommand,
@OnlyModifiedStatistics = ‘Y’,
@StatisticsSample= 100,
@TimeLimit = 7200,
@MaxDOP = 8,
@LogToTable = ‘Y’,
@Execute = ‘Y’,
@delay=1
I’ve tried Ola’s scripts, but could never get them to work for me. You people are a lot smarter than I am. Being a part time dBA doesn’t help me to get any better.
Nice. I am surprised the maintenance plan does that.
Hi Kendra,
Great article, I’m trying to understand the TABLESAMPLE section. Do you have more insight on this?
The reason, I’m asking is that I noticed that the Hallengren script, is set to run as “update statistics TableName indexName… and I’m comparing it with my own script… In my script depending on the number of rows the table has, I decide a sample # percent or Sample # rows… for example, If I had a table that 120M rows, I would decide to sample 3M rows.
My way takes more time than letting SQL pick the sampling as Hallengren does.
I tried to run the query that you have in the TABLESAMPLE section but couldn’t get it to work… I’d love to find a way to get the sampling that the updated statistics command used or would use when not specifying any SAMPLE. Any idea?
Hi John,
Kendra is blogging over here these days.
As to your question, I’m not sure which part of the query you’re talking about isn’t working. The ‘step_direction’ syntax isn’t supported for user queries, but you could do:
SELECT col
FROM dbo.Table
TABLESAMPLE SYSTEM (1 PERCENT)
If you want your code to use the default sampling that Ola’s scripts do, stop specifying a percent or rows, and don’t include RESAMPLE as part of the command. SQL will fall back to its own internal algorithm to figure out how much to look at during stats update.
The latter is what I prefer to do, unless I find the default sampling gives me a histogram that doesn’t accurately reflect table cardinality.
Hope this helps!
I use Ola’s scripts and specify the sampling that I want, generally 100 percent
— ,@StatisticsSample = 100
EXECUTE master.dbo.IndexOptimize @Databases = ‘autoqa’
,@FragmentationLow = NULL
,@FragmentationMedium = ‘INDEX_REORGANIZE,INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE’
,@FragmentationHigh = ‘INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE’
,@FragmentationLevel1 = 15
,@FragmentationLevel2 = 40
,@Indexes = ‘autoqa.dbo.Persistent_object_reference_new’
,@UpdateStatistics = ‘ALL’
,@OnlyModifiedStatistics = ‘Y’
,@StatisticsSample = 100
,@LOBCompaction = ‘N’
,@TimeLimit = 3600
,@MaxDOP = 8
,@LogToTable = ‘Y’;
Randall – I’d suggest that those fragmentation thresholds are way, way too low – especially if you may take indexes completely offline due to just 15% fragmentation. This might make sense in a server with very long overnight maintenance windows where tables can disappear for a period of time, but otherwise it makes me kinda nervous.
Check this out: https://www.brentozar.com/archive/2014/12/tweaking-defaults-ola-hallengrens-maintenance-scripts/
Thanks Brent. I’ve been following your research and recommendations about the overemphasis on fragmentation. In prod I’m using 30 and 50 so as I understand it, below 30 nothing happens, between 30 and 50 a reorg is attempted first if possible, then online, then offline. Rebuilds are attempted online above 50% fragmentation, otherwise offline. Is this still too low? The index rebuild/reorg jobs run for a couple of hours in the evening on weeknights and several hours on Saturday but, in a sense, we have no maintenance window — customer files may show up and be processed anytime. I almost never see issues from the index maintenance though.
Randall – what you’re explaining doesn’t match the code you posted.
[…] UPDATE STATISTICS: the Secret IO Explosion […]
Is there any disadvantage of using update statistics for any row changes or using updatestatistics regardless of any row is modified?
There’s no point in updating statistics for data that hasn’t changed, unless the last statistics update was insufficient to capture a good picture of the data. That’s when you’d want to look at higher sampling rates, or filtered statistics for specific values.
Is there away we can differ the stats update for one particular table during its ETL?
We have auto create and auto update statistics on. We have a table with 10M rows and 300 columns and have lots of statistics on it. We load this table on nightly basis with truncate and insert with minimal-logging. I noticed it still take a longer to load, further digging into it found heavy usage of tempdb during the load thereby I narrowed to find it might be doing stats update. I dropped all stats on the table and ran the load it performed in half the time. Then again this table got stats build up -seem it is queried for multiple ways heavily. I m trying to think if I can differ stats update during the ETL job?
For random questions, head over to dba.stackexchange.com
Thanks!
Caution: Muddy waters ahead. The UPDATE STATISTICS statement has a number of options, including ALL|COLUMNS|INDEX. Great. Per the horse’s mouth: “Update all existing statistics, statistics created on one or more columns, or statistics created for indexes. If none of the options are specified, the UPDATE STATISTICS statement updates all statistics on the table or indexed view. ” Fine, rich prose. Concise, even. Well, kind of. Which columns will be updated should one choose the COLUMNS option? “One or more”. Got that? Me neither.
Hello Kendra and Brent,
I am wondering what the implications are for setting @StatisticsSample as NULL instead of giving it a value because I would like the update statistics job to calculate the statistics sample as I cant predict how many rows are altered per each day on my highly transactional tables. This update statistics job is very important to us as we host billions of rows of data and our databases are extremely sensitive to blocking and slow performance. We do not defragment our databases therefore we completely rely on the update statistics jobs and would like to know if setting the parameter (@StatisticsSample) value to NULL would finish the statistics job in least/optimum amount of time with less intrusion or blocking! Please advice.
As always your knowledge and professionalism are outstanding. A vendor has suggested that I not delete hypothetical statistics (_WA_xxxx) because it is causing blocks in a vendor supplied etl. I have been dropping hypothetical stats for many years with absolutely no performance problem. Vendor indicate query store shows a hypothetical stat is missing (because of the drop) . Any advice would be most helpful
Bill – thanks, glad you like our work. My guess is that you might be confusing system-created stats with hypothetical stats/indexes. System-created stats also start with _WA_sys, and they’re real stats – you don’t generally want to drop those.
[…] UPDATE STATISTICS: the Secret IO Explosion […]