
How to Find ‘Secret Columns’ in Nonclustered Indexes
sp_BlitzIndex® just can’t keep a secret. That’s a feature, not a bug. I wrote sp_BlitzIndex® specifically so that it would rat out some things that SQL Server is doing behind the scenes to secretly help you out– because it’s really better if you know about it.
What are secret columns?
SQL Server needs a unique way to navigate to every row in an index. It also needs to maintain a relationship between every nonclustered index and its base table. In order to accomplish these two tasks, SQL Server always makes sure to add one or more columns to a nonclustered index. If you don’t add the columns yourself, it goes ahead and does it secretly. (“Secret columns” is a term I made up, because a term didn’t exist yet.)
In most cases, people create nonclustered indexes on tables that have clustered indexes. When this happens, SQL Server will make sure that all of the columns from the clustering key of the table are ALSO in the nonclustered index. Exactly how it happens is a little complicated. Here’s a quick summary of the rules involved:
- If the nonclustered index is NOT unique, SQL Server makes sure that the columns from the clustering key make it unique behind the scenes
- This is done by promoting the clustered key columns to the key of the nonclustered index (otherwise they can be “included” columns)
- If the clustered index columns are NOT unique, an additional secret column called a “uniquifier” will have already been added to it– and that sneaks into the nonclustered index too
This made my head spin around the first time I tried to sort it all out. Please don’t try to memorize that!
sp_BlitzIndex® helps make this easier
I never expect anyone to remember this stuff. I built sp_BlitzIndex® so that it would give you the information you need about what’s going on in a specific index without having to memorize a whole lot of rules.
Let’s take a look at a specific example. The AdventureWorks sample database has a table named Production.WorkOrderRouting. We can take a look at the indexes, missing indexes, columns, and foreign keys on this table in sp_BlitzIndex® by running the command:
|
1 2 3 4 |
exec sp_BlitzIndex @database_name='AdventureWorks', @schema_name='Production', @table_name='WorkOrderRouting' |
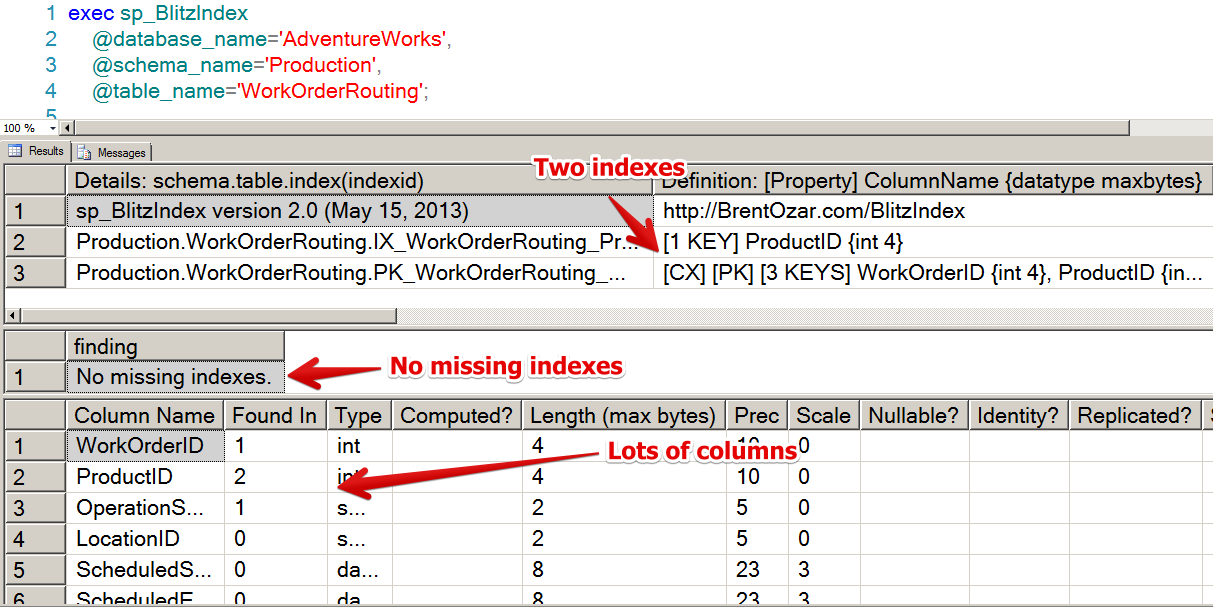
This shows us that the table has two indexes. One of these is the clustered index:
![]()
The definition indicates this with the code “[CX]”. It’s also a Primary Key, indicated by the “[PK]”. Primary keys are always unique in SQL Server, so this is a Clustered PK (which is by definition unique). Because this is the clustered index we know that it will contain EVERY column in the index all of the data. The data is sorted by three key columns: WorkOrderID, ProductID, OperationSequence.
Where are the secret columns?
In this case, the secret columns are all in the nonclustered index. The nonclustered index looks very narrow and simple at first. It has only one key column, ProductID:

Scrolling over, sp_BlitzIndex® claims that things aren’t so simple. There are three secret columns in this nonclustered index, and they have been put in its key:

Those are the exact three columns from our clustered index! (WorkOrderID, ProductID, OperationSequence)
Exactly how many columns are in this nonclustered index?
You may have noticed that the ProductID column appears twice in sp_BlitzIndex® for this nonclustered index. It was defined as a key column, but now we’re saying that it’s a secret column as well.
Question: Does that mean the column is stored twice? No, the column is NOT stored twice. The effective definition of this nonclustered index is that it has THREE columns in it (not just one, as the creator might have thought). The columns are in the following order: ProductID, WorkOrderID, OperationSequence
SQL Server will only ever add columns from the clustering key to an index if you have not specified them in the index. It will never have to store a column twice. I repeat, there is no penalty if you list a column from the clustered index in your nonclustered index. (Yay!)
To determine the columns that will be in an index, look first at the index definition. Then add in the “secret” columns which haven’t already been included.
Why doesn’t sp_BlitzIndex® remove “duplicate” secret columns?
Well, it’s complicated. I made this design choice for a few reasons:
- I wanted to preserve the definition as the index was created
- The definition may state a column as an include that is made into a key column by SQL Server secretly. The easiest way to show this is to show both
- I wanted to show the secret columns on their own so it would be more clear that they will stay in the nonclustered index even if you remove them from the stated definition
A more complex example
Maybe you’re not sure if I’m telling the truth about these secret columns. The good news is, I can prove it. First, let’s look at a more complex example.
We’re sticking with the Production.WorkOrderRouting table. What happens if we add a more complex nonclustered index? This new nonclustered index has two different columns from the clustering key — one as a key column, and one as an included column. I create the new nonclustered index with this command:
|
1 2 3 4 5 |
CREATE INDEX ixtest ON [Production].[WorkOrderRouting] ( PlannedCost, ProductID, ActualCost) INCLUDE (ActualEndDate, OperationSequence) GO |
sp_BlitzIndex® shows that the new index is assigned IndexID=4 for the table.

Definition: [3 KEYS] PlannedCost, ProductID, ActualCost
[2 INCLUDES] ActualEndDate, OperationSequence
Secret Columns: [3 KEYS] WorkOrderID, ProductID, OperationSequence
There’s some overlap here. To interpret this, we know:
- The key columns in the user definition will be present in the order specified
- Secret columns are being added to the key of the nonclustered index in this case. So any secret column that was listed as an “included” column of the user definition will be promoted by SQL Server.
Based on the rules, the functional definition of this index is:
5 Keys = PlannedCost, ProductID, ActualCost, WorkOrderID, OperationSequence
1 Include = ActualEndDate
We effectively had WorkOrderID added to the key (it wasn’t listed), and OperationSequence promoted to the key from the include.
Let’s prove it!
To prove it we’re going to use a handy new DMV in SQL Server 2012 and the built in DBCC PAGE command.
These are both undocumented tools. Please do not run this in production. Seriously, I’m not kidding. There are bugs with this stuff sometimes, OK? Why risk it? This is suitable for AdventureWorks on a test instance far from production, your boss, and your resume.
First, I’m going to find a single page from the leaf level of this new nonclustered index. I love the new sys.dm_db_database_page_allocations DMV because it makes this super easy, as long as I know that my new index has ID=4 (I got that from sp_BlitzIndex® earlier):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT top 1 allocated_page_page_id, allocated_page_file_id, page_type_desc, page_level, next_page_page_id, previous_page_page_id, is_allocated, is_mixed_page_allocation FROM sys.dm_db_database_page_allocations (DB_ID('AdventureWorks'), /*database-id*/ OBJECT_ID('Production.WorkOrderRouting'), /*object_id */ 4, /*index id */ NULL, /*partition id */ 'detailed' /*mode*/) WHERE page_type=2 /* index page*/ and page_level=0 /*leaf of the index */ ORDER BY page_level DESC, next_page_page_id DESC; GO |
![]()
Next, I have SQL Server dump the contents of that index page to my screen. I do that by using this (not officially documented) commands:
|
1 2 3 4 5 6 7 8 9 10 |
--This trace flag prints DBCC PAGE data to our screen. --Otherwise it'll just go to the error log. DBCC TRACEON (3604); GO --Plug in the page --I'm looking in file #1 --Page 24882 --Dump style = 3 DBCC PAGE('AdventureWorks',1,24882,3) GO |
And VOILA! I get back a dump of all sorts of information about what’s on that single page of data– including exactly what’s being used as key and includes for that index!

Were we right?
Sure enough we can validate our theory. The “secret columns” put a new column in our key and promoted one column from the include.
The good news is the order of the keys we specified was preserved, and no column had to be stored twice. That’s awesome!
The bad news is that SQL Server didn’t tell us about this on our own. We had to use a special tool to figure it out. And while this is somewhat of a party trick, it’s probably not something you can trot out to fascinate the crowd at your next family reunion.
Frequently asked questions
I’m overwhelmed! What if I don’t get this? Breathe deep, I promise it’s OK. If you’re just getting started, that’s understandable. Just remember that the columns in “secret columns” will be added to the nonclustered index if they aren’t already there. That’s all you really need to get going.
Is it good to have all those columns in the clustering key? Not necessarily. You want the clustering key to be narrow– having a lot of columns or even a few large columns in it can clearly bloat all your indexes on the table and cause lots of problems. Before you get too comfy, remember it’s not always bad to have more than one narrow column in a clustering key, particularly if they create a unique, static key that is useful for range queries and has a healthy write pattern.
Isn’t it actually more complicated than this?
Isn’t this complicated enough? Sure, “Row Identifiers” (“RIDs”) come into play for heaps and there’s those pesky “uniquifiers”. That’s a bit much to explain in one post. (If they impact you, sp_BlitzIndex® will show you those, too.)
How do I get sp_BlitzIndex®? Download sp_BlitzIndex® here.

20 Comments. Leave new
I’ve been telling people that it adds the clustered index as included columns on nonclustered indexes for the past two years. I’m not sure if I should thank you for setting me straight or complain that I have to go back and tell people I was wrong.
Thank you for the detailed explanation!
Well, that’s pretty darn close to correct– I think for most people it’s good enough to help them understand the concept.
Honestly I just say “it gets added to the nonclustered index” most of the time without specifying. Because if you do try to specify it takes about ten minutes and eyes start to glaze over. 🙂
Nice explanation. I plan to add that index info into my addin for SQL Management Studio called xdetails. But I didn’t do it yet because I was busy studying for MCM exams. First page of addin is free for everyone forever, the rest pages are free for SQL MCM and MVP.
Nice Article
Thanks for such a comprehensive article. I do have one question, though – if we get the clustered index columns “for free” when we create a nonclustered index, why does SQL sometimes complain about a “missing” index that contains columns from the clustered index? Doesn’t this part of SQL know about its own secret columns?
The missing index feature is great, it’s just not super smart all the time. On most versions of SQL Server it will sometimes ask for indexes that already exist (not even counting secret columns– it asks for an index that explicitly already exists). Check out this connect bug I filed on it back in 2009 for more info: http://connect.microsoft.com/SQLServer/feedback/details/400578/query-plan-missing-index-recommendation-doesnt-check-if-an-index-actually-exists
Joe,
The missing index feature will ask for these columns to be part of the nonclustered index because it can’t guarantee that your clustered index will always be the same. If an index would be rendered useless (or just much less efficient) with the lose of the column(s) in the clustered index, it’s always better to explicitly add them to the definition. It doesn’t add anything to the cost of the index but avoids future issues.
Steve: great answer, thanks!
Are you sure about this one/do you have a source post from the product team confirming it? Since there’s known bugs in the area of asking for things that already exist, I’m suspicious this isn’t by design at all either.
Hi kendra.
Nice work as Always. 🙂
One Q-Q: Why my statistics job take longer the when i’m rebuilding all index on a database.
Usually it take 2 hours to rebuild and it’s taking 8 to update all statistics 100%.
Was reading and i have no clear explanation.
Thanks
You can have statistics both on columns and indexes– if you have auto create stats on (which is a good thing), you may have many statistics generated dynamically on individual columns.
I wouldn’t update statistics with fullscan as a general practice. Occasionally you may have a reason to give special treatment to an individual statistic if you’re solving a problem, but typically you don’t want to fullscan all the things for IO and concurrency reasons.
Just FYI, you might want to update your calling string for your sp. The parms are now DatabaseName, SchemaName and TableName, with no underscores.
Great sp! Thanks, I’m figuring out how to get around all my ‘issues’ as I am new to my existing schema and application. I have several queries I’ve written but this is very nice. It would be nice to have the current date, database name and object name in some of the queries for when I am doing these over time and comparing in Excel and filtering by object etc.
Again, thanks, and the secret column makes a lot of sense.
If you have non clustered indexes using the secret column as the first key used for a particular queries, are you then able to eliminate this key as it’s already brought in possibly out of order? I apologize if this has already been asked, just want to understand of the order or precedence for they index keys.
An example would be with the Clustered / Primary key:
[CX] [PK] [1 KEY] pkAsset {int 4}
Non clustered Indexs
[4 KEYS] pkAsset {int 4}, AcctCode {varchar 50}, fkProduct {int 4}, fkAccount {int 4}
[2 KEYS] pkAsset {int 4}, IsActive DESC
[4 KEYS] pkAsset {int 4}, fkProduct {int 4}, AcctCode {varchar 50}, SecondaryAcctCode {varchar 50}
[3 KEYS] pkAsset {int 4}, fkAccount {int 4}, fkProduct {int 4}
[7 KEYS] pkAsset {int 4}, fkProduct {int 4}, CurrValue {decimal 9}, CurrShares {decimal 13}, PendValue {decimal 9}, PendShares {decimal 13}, fkPriceCurrValue {int 4}
Does it make any difference on the size of the nonclustered if the secret columns are still added to the index definition? Having a size limit is sometimes a reason to put columns into INCLUDE and by omitting secret columns we could have some more room.
Aleksandr – why not test it yourself and find out? That’s one of the fun things about using sp_BlitzIndex with the table name specified, like sp_BlitzIndex @TableName = ‘Posts’. You can learn that lesson quickly with the mini-sized StackOverflow2010 database available freely here, too:
https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
I’d always encourage folks to learn by experimenting, especially when a question like this one is so easy to set up an experiment for yourself to learn and test.
“SQL Server will only ever add columns from the clustering key to an index if you have not specified them in the index. It will never have to store a column twice. I repeat, there is no penalty if you list a column from the clustered index in your nonclustered index. (Yay!)”
Am I reading this correctly ?
If I have a Clustered Index with 2 columns, and I have a NC index on a different column – and I alter the NonClustered index to either add or INCLUDE a column from the Clustered Index, there will be no extra storage consumption/increase in size on my NC index, because it was there, sort of, as a secret column anyway?
(ha, read your reply to Aleksandr above and will test at a time that isn’t 1am 🙂 )
If yep, then there is still a potential benefit in query bucks by adding one of the 2 Clustered Index columns to this NonClustered index ?
David – rather than asking us to repeat what we’ve already written, go ahead and run experiments for yourself to see. Hope that’s fair. Brent
aye – it is. 🙂 stay safe and stay awesome ! you’re an inspiration for us suffering accidental DBAs and we learn by doing, not by surfing
//offtopic, how’s the GDPR EU battle going? would love to take your trainings one day!!
Sure, read the latest update at the bottom of this: https://www.brentozar.com/archive/2017/12/gdpr-stopped-selling-stuff-europe/
Very well written. Thanks, Brent!