It’s Been Decades. Why Don’t Databases Manage Themselves Yet?
This month, to mark the 20th anniversary of BrentOzar.com, I’m stepping back and looking at the big picture rather than blogging about database problems & solutions like I usually do.

When I started working with databases, we had to:
- Provision the right CPUs and memory
- Provision the right storage throughput and size
- Install the database
- Configure the database
- Protect it – which sounds easy, but that also includes designing the right high availability and disaster recovery solution
- Design the right tables, and put indexes on them based on how we wanted to query the data
- Write fast, accurate queries to load & retrieve data
- Troubleshoot the whole thing when it went wrong
Today, decades later…yeah.
We’re still doing all of that stuff. It’s just that we’re cave-people using rocks for tools instead of banging on things by hand.
Vendors aren’t focused on these problems.
Oh sure, they’re marketing that they’ve built something better, but when you start to rub your finger on the product, the wet paint wipes off and you see the conventional problems underneath.
Let’s take something really simple: let’s build a new Azure SQL DB:

You get sliders for vCores and data max size.
But notice the number with the biggest font size on the screen: 150. Your choices for vCores and data size determine log space allocated, and it’s important enough that Microsoft puts it in bold, but you can’t actually control it directly. If you want more log space, you have to increase data space.
So if it’s important enough to put in bold, we must know the right number for it, right?
Nope. In Azure SQL DB, space consumption is something that’s controlled only by the database server, not by administrators. You can’t fix it by backing up more frequently: Microsoft controls your backups. Microsoft is hinting that, “Yo buddy, you better know how large your transactions are and how far behind your AG secondaries get, and if you get this wrong, inserts/updates/deletes will fail.” They’re supposed to have fixed this with Accelerated Database Recovery, which the documentation says is on in Azure SQL DB and can’t even be turned off – but it’s still an issue, or it wouldn’t be the biggest number font on the screen. Or even worse, if it is fixed, why is it being featured so prominently, suggesting to users that they need to build a bigger server to handle a log file size that doesn’t matter anymore?
<sigh>
It’s 2021, and we’re back to 2001.
We’re still screwing around with micromanaging transaction log sizes, trying not to run out of disk space. On premises, we learned the easy fix long ago: just set log file sizes reasonably, and then leave autogrow on. If one database out of fifty happens to have a runaway transaction, they can grow temporarily. We’ll deal with it.
Scaling CPU? Self-re-configuring? Nope.
Forget about storage – what about sudden demands for CPU or memory? Serverless, self-scaling databases like AWS Aurora Serverless and Azure SQL DB Serverless say they solved it with auto-scaling. That’s not solving the problem – it’s just unlimited provisioning. You wake up to a $100,000 cloud bill when some bot scrapes your site or when an app ships with an N+1 bug.
I know first-hand because our own SQL ConstantCare® product is built atop Aurora. Last year, I blogged about how a single database view cost me $50/day for months, and you know what? I’m in that same exact boat again today. Our database costs gradually creeped up because we deployed more and more queries for new features, and some of the new queries weren’t well-tuned. I had an item in my backlog for weeks to go do more database tuning, and our Aurora costs crept up to over $200/day. I had to go bust open AWS Performance Insights, find the queries involved, tune them, check them into Github, have Richie fix the unit tests, and then deploy it.
Self-configuring databases? Not even close: Microsoft SQL Server 2019 and its cloud equivalents, Azure SQL DB, still ship with the same Cost Threshold for Parallelism setting that every freakin’ setup checklist still tells you to fix manually. Every release, it seems like we get thrown a bone for one or two configuration settings just so the marketing team can say the database is becoming more self-configuring. That’s great, but at this rate, it’s going to be 2070 before setup checklists can go away – if ever, because vendors keep adding features and dials that need extensive tweaking.
Self-patching? Well, kinda, but only in the worst way. In Azure, you don’t get a truthful changelog, and you don’t get to test before they do it to your production server, or when. Just this month, in March of 2021, Azure SQL DB finally announced that you can pick what window they’ll use for maintenance to take your server down, and get alerted before they’re gonna do it. You can choose between:

- Every day, 5PM-8AM local time, or
- Mon-Thurs 10PM-6AM
- Fri-Sun 10PM-6AM
That’s it. Those are your only choices. And that feature is only in preview, and only in select regions. If vendors really cared about database administrators, this stuff never would have gone into production like this.
Somebody in the audience is going to say, “Does Azure Arc help?” Well, it purports to, in the sense that it puts both your on-premises SQL Servers and Azure instances into the same Azure control panel, gives you self-provisioning, and has policy-based management. Given Microsoft’s track record with Policy-Based Management and the Utility Control Point, both of which were grandly-announced features that quietly died off without getting fixes or improvements, I’m gonna wait to see if this is another one-and-done turkey.
Vendors are focused on selling,
and database administrators don’t buy databases.
As important as you think you are, you’ve likely never written a check for database licensing or cloud services.
The reason you have a job is that your employer implemented a database, it grew over time, and it grew beyond the self-managing capabilities touted by the brochure. You were hired long after the database choice was made. And no, you’re not really able to influence future purchasing decisions because that ship has sailed: your company picked a persistence layer, and when it comes time to pick additional persistence layers for new products, you’re only going to be one of many people sitting at the table.
Databases are bought by two roles: developers and executives.
When developers make database decisions, in most cases, they’re not experienced enough with multiple database platforms. They’re either familiar with one, and that’s the one they pick, or they’re not familiar with any, and they’re forced to make a selection based on the vendors’ marketing material, what their friends say, what they read on HN, or some meaningless database rankings site.
When executives make database decisions, they either work from feature lists like EnterpriseReady.io, looking for things like auditing, role-based access, Active Directory integration, or else…they work off the vendor’s brochure, and self-managing is just another feature in a feature list.
Developers and executives buy features.
I don’t mean this in a negative way! It’s the same way we buy appliances or cars or laptops. We have a rough idea of the features we need. Products rarely have all of the features we want – at least at the price point we’re willing to pay – and so we have to make compromises. We might accept a half-baked version of one feature because we want another feature so badly.
In 2021, every database’s brochure has “self-managing” slapped on the brochure somewhere, and every vendor will show just enough demos to hoodwink non-DBAs. “Self-managing” doesn’t have to be fully true in order to sell – just like “secure” or “performant” or “scalable.” Everybody uses these keywords. They don’t mean anything.
Even worse, self-managing is just one of the features people are looking for. Every time a database vendor slaps on another feature, that feature has dials and switches to configure it – and when the feature is brand new, those dials and switches have to be configured by hand. There’s never a best practices doc – the feature has to ship first before the real world learns the best practices, and we all write documentation to tell each other how to set the dials and switches.
Want proof? Check out the home page of Couchbase.com. Look at the kinds of features that they tout. They emphasize the power of the product, empowering you to do all kinds of things – but you still have to actually do those things, like size it, monitor & tune the queries, configure the security, and configure all the settings. It simply isn’t self-managing – and it doesn’t matter, because people love it. They’re going public with a $3 billion valuation. The market has spoken, and features are where the money is.
It’s a race between new features
and self-managing those features.
Sure, vendors can say that a brand-new feature is self-managing – but again, rub your finger on it, read the release notes, run an edge case performance test, and you’ll pretty quickly find the undocumented dials and switches that need to be turned just so in order to make this pig fly.
New features will always win the race.
They have to. Vendors are in their own race against other vendors, racing to ship features that nobody else has, or to keep up with features that someone else has already shipped.
This influenced my own career:
I gave up on production DBA work.
Ten years ago, when Microsoft first brought out Always On Availability Groups, I was ecstatic. I was doing a lot of production database administration work at the time – making sure SQL Servers were highly available and well-protected – and I saw Availability Groups as a better way to achieve that goal.
But then the features versus self-managing race started.
The good news was that Microsoft poured resources into AGs, adding all kinds of features to them. More replicas. Cross-database transaction support. Availability Groups that spanned multiple Windows clusters.
The bad news was that not only were these features not self-managing, they were practically unmanageable: the documentation was terrible, the GUI was non-existent, the damn thing broke constantly in crazy unexpected ways. (For fun details, read the past blog posts on TarynPivots.com, Stack Overflow’s DBA.)
By the time Microsoft said they were bringing Availability Groups to Linux, I said okay, I give, no more, time out. I had come to see SQL Server high availability as a Sisyphean task: I could never really be done with that miserable work, and even when I thought I was done, some new surprise knocked me flat out. Even worse, those surprises always came after hours, on weekends, on holidays, when all I really wanted to do was relax.
If you do want to learn Availability Groups, Edwin Sarmiento is about to open a new rotation of his class. He only does a few of these per year, and it’s a hybrid of consulting, coaching, and training. Learn more here.
I focused on development DBA work instead.
Here’s a quick rundown of the difference between developer, development DBA, and production DBA:
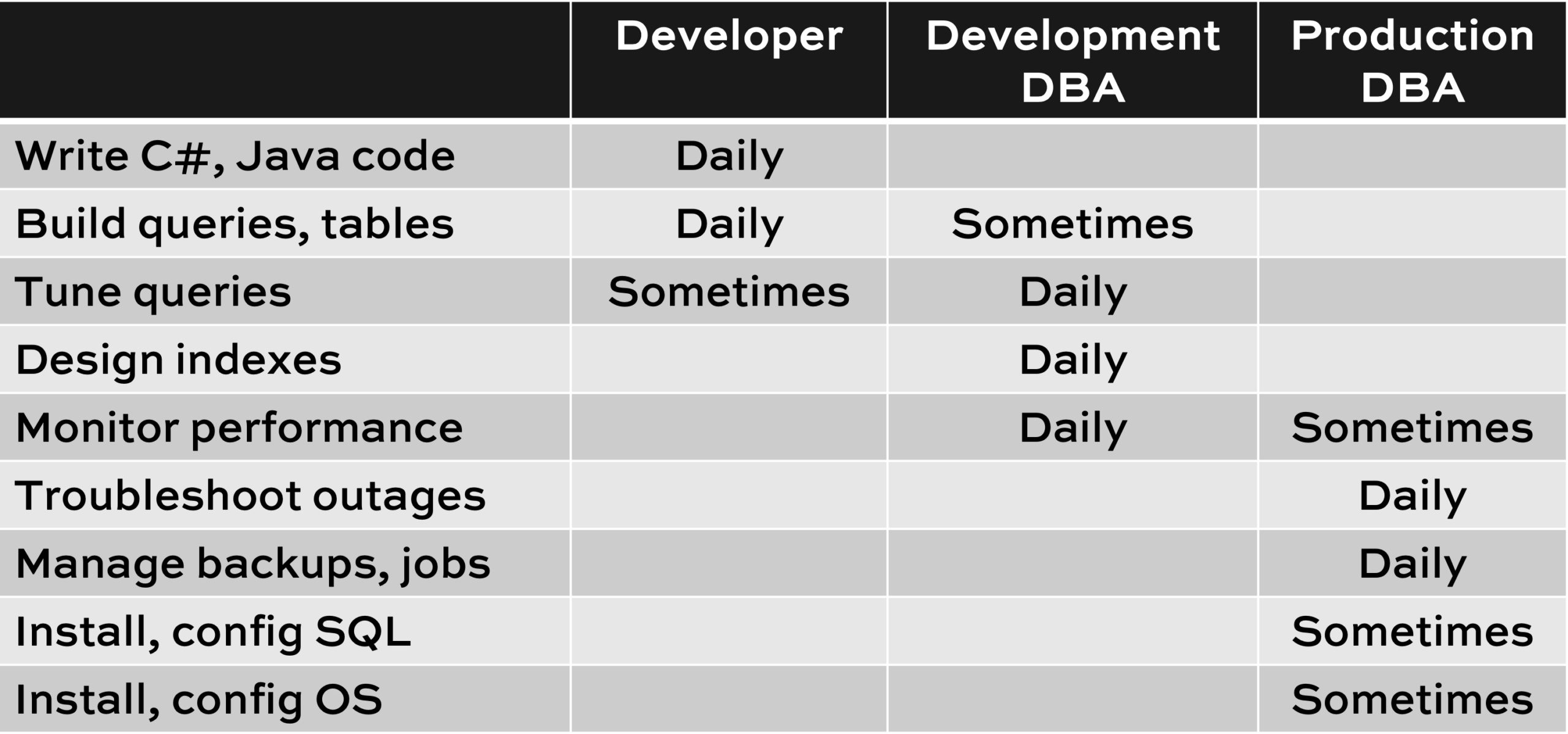
I chose to move from Production DBA to Development DBA. These days, my consulting work and my training classes focus on solving performance emergencies. I can at least schedule those engagements in advance because companies know when their performance is slowly getting worse, and we can work together during weekdays, business hours, in order to turn things around. (As opposed to production outages, which always hit at the worst possible times when I’ve just made a fresh gin & tonic.)
Production DBA work is still there, mind you, and every month I get emails from folks asking me to record new training classes on how to do it. I’m just flat out not interested in that work, and I’m not interested in doing training on it anymore.
So with that in mind, I put our Fundamentals of Database Administration class and Senior DBA Class on YouTube, for free, forever. They’re older classes, and they don’t have the best audio & video quality, but I’d rather just let them out there to the public to help the folks that need ’em. Hope that helps – and I also hope that database vendors start taking the self-managing thing more seriously, for the sake of production DBAs that still have to deal with this mess.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
wow. Just wow. I bookmarked this one so I remember to re-read often. I’m sending it to all my co-workers too.
Just a few specific comments:
* Developers/executives buy features. You nailed this. I remember when Mongo came out and the top 3 bullet points were “no dba needed” and “no backups needed” and “no data modeling”. Brill-yunt. All executives heard for years was some dumbass DBA bitching that some new feature couldn’t be rolled out because the dba needed to do some dba magic that takes time. Just last week a customer told me they couldn’t move to azure sql b/c it didn’t have “torn page automatic fixation”. My response: Huh? Who even cares? When was that last an issue for you? And why is it an issue for you? Worry about tweaking your indexes to cut down on your out-of-control disk-to-memory transfers.” Developers love “no data modeling” because data modeling is hard and they can manage schema versioning in the app tier with mongo. Now, how m i gonna report off that?
* I worked for a large healthcare ISV and all we ever cared about was new feature functionality. Perf issues? no one cared. Bugs? Oh well, that’s yesterday’s dollar, we need to make tomorrow’s dollar. This is why developers have an aversion to “technical debt”. They know in most corporations it will never get paid down and they’ll spend years dealing with the fallout from short-circuiting good development processes. I’m a big fan of “no premature optimization” but you can’t do that if management won’t let you spend time fixing what you didn’t anticipate. This is even more pernicious with the Cloud Wars where vendors SAY certain features are fully supported but a little experimentation shows that those features are not complete. We’ve all come to learn that what is missing today will be missing in 10 years too. How many years did we wait for CREATE OR REPLACE syntax in SQL Server? Instead we all wrote tons of boilerplate IF NOT EXISTS…when Oracle had CREATE OR REPLACE since 1989. Autonomous transaction support? We still don’t have it. (But we do run on linux now).
* I totally agree with you on prod DBA career vs dev career and my career took a similar arc. I was frankly tired of dealing with HADR features when…this will be controversial…I saw those features being the root cause of so many failures/fail-overs. Seriously. We did a study on our prod sql servers and why they failed and it was usually due to some “process” that required a restart of the db server and the failover didn’t work, causing even more downtime. Who needs this headache? We actually ripped out AGs and FCIs and all that and went back to straight SQL Server and uptime increased…dramatically. And, processes were streamlined and easier to document/automate. Suddenly a jr dba was a viable option vs an expensive SENIOR DBA that had special Brent Ozar training. And this was around 2013ish. It didn’t take long for someone to ask, “why are we paying for enterprise again?”
* Question: why did you even care when AGs came to Linux? Seriously. Linux is pretty stable (there’s no UI and hence no one to poke around and say, “Whoa, why is “boost sql server priority” not clicked? I’m gonna go do that on Friday right before I leave for the weekend”. Seriously…windows core was the greatest thing to happen to stability. No more people poking around where they shouldn’t. I’m convinced Linux is so stable b/c no one is really sure what to tweak even if they had to!!! Start throwing AGs and glusterfs and … linux starts to get “weird”.
This is definitely a must-read post and possibly my new favorite from you.
–dave
Thanks Dave, glad you liked it! The reason I cared about AGs on Linux is that … I didn’t want to work on Linux. If you search for “Linux” in my past posts, you’ll see that I really WANTED to love Linux, but I just couldn’t ever make it work in my own personal career. It’s a great operating system, for sure, but…I just don’t really want to work on it.
Also, if you think Linux is stable because people don’t poke around, you haven’t done consulting. I’m constantly amazed where people will put their fingers, hahaha.
hahaha. spot on.
Some client once asked me, “how can I fix some data in some folder.”
me: Just rimraf it
client: what’s that?
me: just run
rm -rf /folderAnd yeah, the client actually did that…without googling what that is. so yeah, to your point, the argument could be made that it’s even WORSE on linux.
So from what I can see, and I have not been here long, I am sure that the old saying rings true BrentOzar.
Sharing is caring 🙂
Thanks man, loving your content and training style.
See you in the Fundamentals class soon.
The Log space example nailed it. The SQL Server implementation of transaction logs is shitty in the first place. Why isn’t it shrinked automatically after a successful backup? Why not using fixed size logs and rotation like other RDBMS does? It is not a mystery to me, I believe it is shitty by design. They could easily integrate some features to automate such things, but who cares, if you can do these things?
Kind of interesting, google’s cloud SQL has had the whole maintenance window issue fixed for years now. Also looking at the “newSQL” databases like TiDB they have a lot of this stuff fixed and seem to be constantly working on fixing more of it. I do agree that more traditional SQL databases, even the managed services for them require a lot more manual configuration and tuning than they should.
Excellent article Brent!
I was wondering if you had any thoughts on Oracle’s “Autonomous Database”, other than it’s expensive LOL!
You mean the company that called their database “Unbreakable” back in 2005?
BWAAAA-HAAAA-HAAA!!! You said “Scaling CPU? Self-re-configuring? Nope.” That’s totally wrong. It scaled perfectly in your example. If you don’t think so, look how much you ended up paying them. It scaled perfectly to make them the most money possible without any real help from you. 😀 😀 😀
Ok… dropping the ironic sarcasm and terrible attempt at humor, very nice and very true article, Brent. Thanks for taking the time to write it up.
Hahaha, thanks Jeff!
Thanks for the videos, Brent.
Senior DBA class shows 27 videos, with last 7 marked as private. Is that intentional?
Dude. Ditch Microosft and go to Snowflake cloud data warehouse. Truly self managed. You will be pleasntly surprised.
Oh awesome! I had no idea they were self-tuning these days. So you always get the same monthly bill regardless of how many queries you run?
Or did you not read the post?
Too soon?
Yip, same monthly bill for 2 years now.
You may also mention a ‘renaming trick’. For example, “SSRS reports” were renamed to “PowerBI Paginated reports”. Cool name, but same 15-years old product
You raise some great points.
To make an rdbms self managing requires a pretty hefty CMDB that contains not just definitions of “what is”, but also “What should be”. It also requires a ton of automation. Both these things take a long time to build. Most DBAs do not have that kind of time.
That being said there is also another concern. Automation is extremely powerful and there are plenty of good use cases for it in almost any environment. But how much and when/where is really company and environment specific. Not everything should be automated, and certain things that should be in one environment, shouldn’t in another.
Thanks sir!
Great post Brent – i thought i noticed more of your great tutorials on Youtube recently – thanks, that’s awesome – especially during these lock-down months 🙂
..from a Prod DBA thats managed to side-step AOAG – i can almost relax most weekends 😉
Great insight Brent. Thank you for sharing this. It really helps to see someone of your caliber say this as I thought I was going crazy trying to get my DBs to “just run” without much further input.
You’re welcome, my pleasure!
Thank you Brent for sharing all these materials for free. Our work is changing so fast that we do need a clear recap sometimes, and your post is really helpful.
Best article summarizing the actual state of all the “automagic” database features in SQL Server!
I’m forwarding the URL to my supervisor, a great manager and hardware/OS administrator, who genuinely does not quite understand why database servers take so much time to administrate in the production environment. And, who wishes we had the money to use features like AG. Maybe your article will convince him otherwise.
Because so much automation is missing from SQL Server, I’ve taken the time to automate as much as is reasonable using SQL Agent jobs. This has worked well for me; I sleep at night.
I forgot to say that I have a rule that I have strictly adhered to on the servers I administrate: Simplicity.
I strive for simplicity in everything I implement on the database servers. The less complicated something is, the less likely it is to have something go wrong. My Simplicity rule precludes me from implementing some things (like AG), but my employers’ servers do not want for anything.
We have had 5+ (9’s) of uptime every year for the last 4 years on our database servers (not counting Microsoft monthly maintenance windows; our SQL Servers are on VMs in the Azure Cloud). The database servers don’t even have short periods of degraded performance unless some newly deployed application code has a flaw. It’s never the database servers.
4 years of results are my argument for Simplicity. And that rule precludes me from implementing many/most of the new “features” Microsoft touts. I have avoided most of them like the plague they can be.
Ah!!! Preach it Lee!!!! I totally agree!
On the subject of servers managing themselves, look what MS did to TempDB by making the equivalent of TF11117 permanent with no overrides! I guess they forgot that they haven’t yet fixed the sort problem with SET IDENTITY_INSERT ON, which forces a sort of the table in, you guessed it… TempDB. Just imagine what happens when you have a nice little TempDB of a 100GB and you’ve been able to go for a decade without anything bad happening and you go to rebuild a little ol’ 50GB table by copying the data to a new one and you have the “recommended” 8 TempDB files and they all try to grow to 50GB with a cap at 100GB. BOOM!!!!
It would have been simple to shrink the one TempDB file back down to where it belongs but, thanks to the idiocy that insisted that TempDB should be hardcoded with no override, I was instead stopped absolutely cold.
As I used to say, “If you make something idiot proof, then only idiots will use it”. Stop trying to help the idiots by crippling the rest of us!
I started in 1996 with Sybase and SQL SERVER later… a lot of years ago and still kicking…
Thanks for the post, following you for years and you are still the best.