
During Training
We were talking about computed columns, and one of our students mentioned that he uses computed columns that run the REVERSE() function on a column for easier back-searching.
What’s back-searching? It’s a word I just made up.
The easiest example to think about and demo is Social Security Numbers.
One security requirement is often to give the last four.
Obviously running this for a search WHERE ssn LIKE '%0000' would perform badly over large data sets.
Now, if you only ever needed the last four, you could easily just use SUBSTRING or RIGHT to pull out the last four.
If you wanted to give people the ability to expand their search further, REVERSE becomes more valuable.
Oh, a demo
You must have said please.
Let’s mock up some dummy data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
USE tempdb; DROP TABLE IF EXISTS dbo.AllYourPersonalInformation; CREATE TABLE dbo.AllYourPersonalInformation ( id INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED, fname VARCHAR(10), lname VARCHAR(20), ssn VARCHAR(11) ); INSERT INTO dbo.AllYourPersonalInformation WITH ( TABLOCK ) ( fname, lname, ssn ) SELECT TOP ( 1000000 ) 'Does', 'Notmatter', RIGHT('000' + CONVERT(VARCHAR(11), ABS(CHECKSUM( NEWID() )) ), 3) + '-' + RIGHT('00' + CONVERT(VARCHAR(11), ABS(CHECKSUM( NEWID() )) ), 2) + '-' + RIGHT('0000' + CONVERT(VARCHAR(11), ABS(CHECKSUM( NEWID() )) ), 4) FROM (SELECT 1 AS n FROM sys.messages AS m CROSS JOIN sys.messages AS m2) AS x; CREATE INDEX ix_ssn ON dbo.AllYourPersonalInformation (ssn); |
We should have 1 million rows of randomly generated (and unfortunately not terribly unique) data.
If we run this query, we get a query plan that scans the index on ssn and reads every row. This is the ~bad~ kind of index scan.
|
1 2 3 |
SELECT COUNT(*) AS records FROM dbo.AllYourPersonalInformation AS aypi WHERE aypi.ssn LIKE '%9156' |
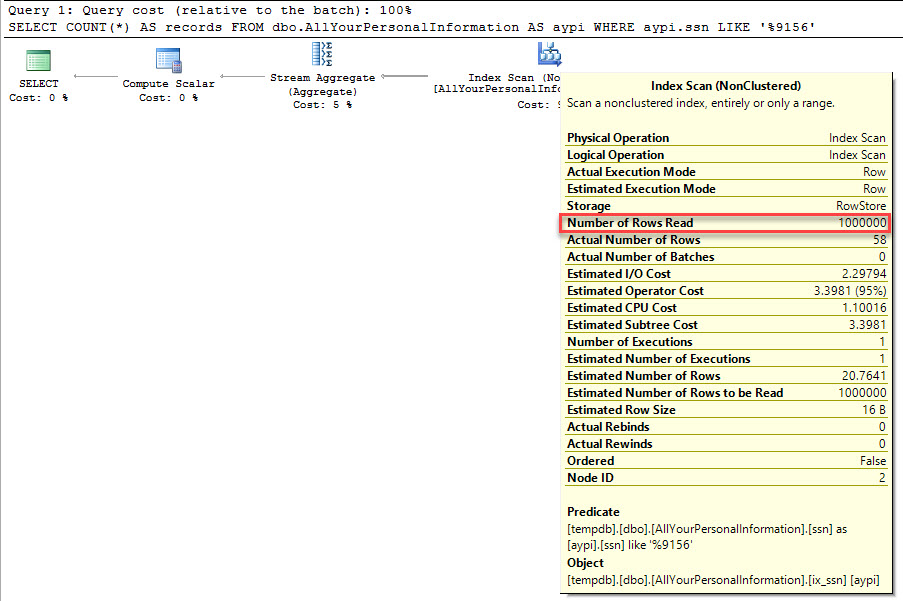
Let’s add that reverse column and index it. We don’t have to persist it.
|
1 2 3 4 |
ALTER TABLE dbo.AllYourPersonalInformation ADD reversi AS REVERSE(ssn); CREATE NONCLUSTERED INDEX ix_reversi ON dbo.AllYourPersonalInformation (reversi); |
Now we can run queries like this — without even directly referencing our reversed column — and get the desired index seeks.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT COUNT(*) AS records FROM dbo.AllYourPersonalInformation AS aypi WHERE REVERSE(aypi.ssn) LIKE REVERSE('%9156') SELECT COUNT(*) AS records FROM dbo.AllYourPersonalInformation AS aypi WHERE REVERSE(aypi.ssn) LIKE REVERSE('%90-9156') SELECT COUNT(*) AS records FROM dbo.AllYourPersonalInformation AS aypi WHERE REVERSE(aypi.ssn) LIKE REVERSE('%082-90-9156') |

What I thought was cool
Was that the REVERSE on the LIKE predicate put the wildcard on the correct side. That’s usually the kind of thing that I hope works, but doesn’t.
Thanks, whoever wrote that!
And thank YOU for reading!

10 Comments. Leave new
Norwegian Encryption
Mind Blown! Every once in a while someone uses a function you wondered if there was ever a use for, and it’s a-maze-ing!
Not too many use cases for reverse() – thanks for sharing!
That was me during the Expert Performance Tuning for SQL Server 2016 and 2017 class 🙂 Thanks for blogging on this one.
Yes! Thanks for attending and for the inspiration, James!
The newer queries can also reference the column reversi with similar query execution plans, but I guess the point of the article is not to break code (which I get)
SELECT COUNT(*) AS records
FROM dbo.AllYourPersonalInformation AS aypi
WHERE aypi.reversi LIKE reverse(‘%9156’)
This example contradicts SQL “rule” that functions in predicates prevent the use of indexes.
Greg – that’s not a rule, air quotes or not. They may prevent an index seek, but saying they prevent the use of indexes is absurd.
Ouch! I wasn’t bashing your example. Poor phrasing on my part. And I didn’t pay attention to the actual Predicate in the seek operator (and missing the heart of the article).
I posted about the behavior of indexed columns inside functions in the WHERE clause and the SEEK not being performed on your new NC index. And if we don’t use that index, using the scan is essentially not getting any at all.
I located an article from Bill Graziano that discusses this pattern of using a computed column and new index and getting an index seek even though we aren’t using the new computed column.
I played with the query and we lose the SEEK if you change the WHERE clause such that the filter doesn’t match the defintion of the computed column (i.e. This is inline with Bill’s analysis that the optimizer is searching for a computed column and filter match)
Learned than one thing in a single post. Thanks
Yup, we use this too — works great.