
 When SQL Server is purely making an estimate up out of thin air, with no freakin’ idea what the real answer is, it doesn’t give you any kind of warning. It just produces an estimate that looks scientifically accurate – until you know how it’s actually getting calculated.
When SQL Server is purely making an estimate up out of thin air, with no freakin’ idea what the real answer is, it doesn’t give you any kind of warning. It just produces an estimate that looks scientifically accurate – until you know how it’s actually getting calculated.
Let’s ask SQL Server how many users have cast more than ten million votes. You can use any Stack Overflow database for this:
|
1 2 3 |
SELECT * FROM dbo.Users u WHERE u.UpVotes + u.DownVotes > 10000000; |
To give SQL Server the best possible chance to calculate it, I’ll even create a couple of indexes, which will also create perfectly accurate fully scanned statistics on the relevant columns:
|
1 2 |
CREATE INDEX UpVotes_DownVotes ON dbo.Users(UpVotes, DownVotes); CREATE INDEX DownVotes_UpVotes ON dbo.Users(DownVotes, UpVotes); |
When I run the query, it doesn’t actually produce any results:
But if I look at the execution plan, the estimates are a little off:
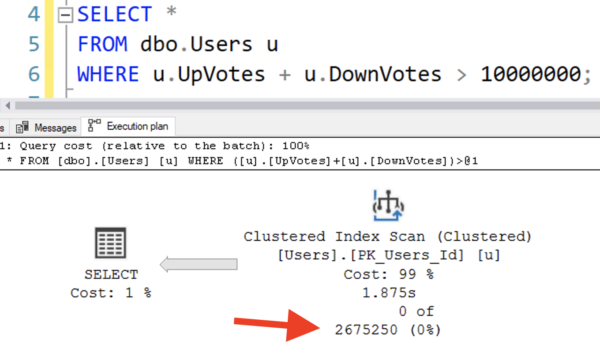
SQL Server estimated that precisely 2,675,250 rows would come back – but none did.
So where does that 2,675,250 number come from? It would sound like it was the result of some really scientific calculations, but in reality, it’s just a hard-coded 30% of the number of rows in the table.
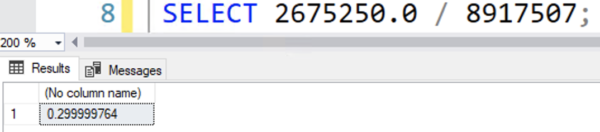
There’s absolutely no logic behind that estimate.
30% is a purely made-up number, and it’s hard-coded: you get the same answer if you use greater than OR less than, and with ANY NUMBER YOU COULD PICK. In my case, I picked ten million rows, but you can put any number in that query, and you still get a 30% estimate.
When SQL Server makes an estimate up out of thin air based on hard-coded rules like 30%, it needs to warn us with a yellow bang so that we can jump to fixing that specific problem.
The bigger your query gets,
the more important this becomes.
I started with a really simple example with a small blast radius: that estimation error doesn’t really harm anything. However, in real-world queries, you start to layer in joins and ordering, like finding all of the users and their badges:
|
1 2 3 4 5 |
SELECT * FROM dbo.Users u INNER JOIN dbo.Badges b ON u.Id = b.UserId WHERE u.UpVotes + u.DownVotes > 10000000 ORDER BY (u.UpVotes + u.DownVotes) DESC; |
You would hope that SQL Server would go find the users first, and then short-circuit out of the rest of the query if it didn’t find any matching users. You would have also hoped that we didn’t have a hard-coded estimate of 30% here too, though, and I’ve got bad news about your hopes. I’m here to turn your hopes to nopes, because here’s the live query plan:
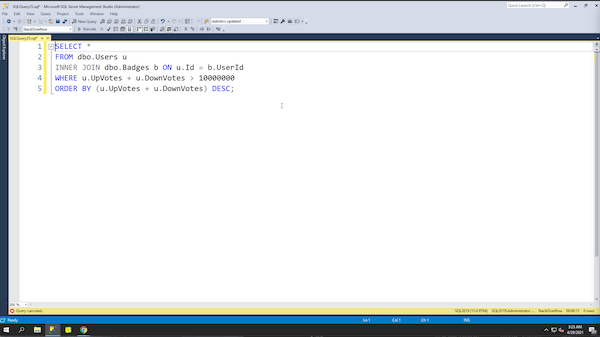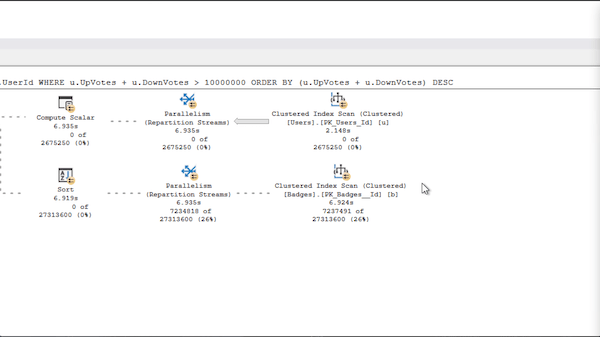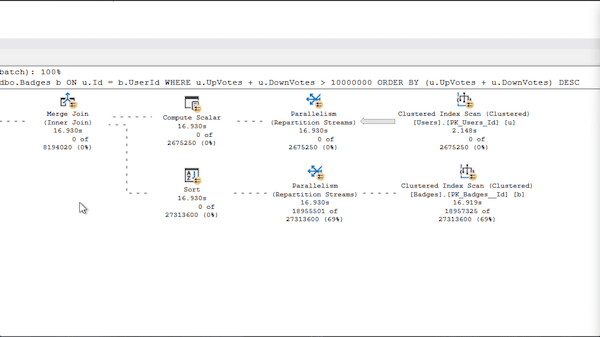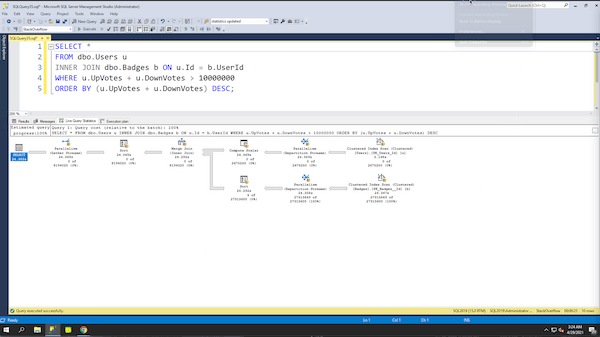
SQL Server scans both tables at the same time because it assumes so many users will match – might as well start work on the Badges table, right? No sense in waiting around to short-circuit – we’re going to be working with millions of Users rows! Better get this party started.
After you learn about this, your next steps should probably be:

12 Comments. Leave new
Is this because of the field1 + field2 calculation being used ? If just a single field were being used, would SQL use the real statistics ?
Yep!
We will always have “IN ( )”
I’ve fixed more than one slow query by replacing where itm.date between ‘2021-05-01’ and ‘2021-05-03’ with where itm.date in (‘2021-05-01,’2021-05-02′,’2021-05-03’) .
Oh lumme thanks for that! I started out on DEC Rdb (yes I’ve been doing this longer than you and know about 0.1% as much as you do!) and they had a kind of thing (can’t remember the name) where they would fire off several threads of different execution plans and then switch to the most productive one after a bit depending on how fast the rows were coming back. Anything like that going on in SQL Server? Rdb was a brilliant database, way ahead of its time…
From my DB2 DBA days (well before the turn of the century), this was known as ‘default filter factors’, when statistics for something doesn’t exist.
(Maybe there is also a similar list for SQL Server that’s published but I never looked). DB2 published a list by predicate type. I believe for an equal value it’s something like .04 for example, and something with a > or < in it is .33 if I remember correctly.
Anyway, today stuff like this in SQL Server tends to hit us on the 1st of the month with the 'views from hell'. New data with dates for the 1st of the month might not necessarily have any (or good) stats just yet. So these 'default filter factors' kick in and that 2 second report is now running for 6 hours until it's killed, plan flushed, statistics run or a good query plan from history is found and pinned for it.
After 2 steps it will work on my 2010 Stack db:
1. alter table dbo.Users add votes as (UpVotes + DownVotes)
– the estimates are wrong
2. create index ix_votes on dbo.Users(votes)
– estimates are good
Btw. Please come back to your post about query tuning in Oslo. The query you tuned is an example how not to do it. I left 2 comments how I tuned it and why the query is wrong (mini cross join example).
It’ll even work after step 1 if you update the statistics on the freshly added column. However, we can’t go adding columns to tables every time SQL gets bad estimates. We’d have thousand column tables, which presents new challenges.
I’m not sure what you mean about Oslo – I get hundreds of emails per day, and I can’t do free personal advice for everyone. It sounds like you’re at the right point of your career to hop into my training classes, though, where I have plenty of time to do in-depth Q&A with the students. For that, click Training at the top of the screen. Thanks!
Brent,
I will attend in your trainings rather sooner than later cause I see a lot of value in them. But I need to find some time and when I catch up with other stuff then I will join Fundamentals class.
I am not looking for personal advice. I rather wanted to point one thing for your post from 2020 you can use on your blog and teach something your views. It is interesting because I wanted to do the same steps on my computer and I wanted to check if I can do more as I did on Oracle (I am switching from Oracle to T-SQL and your videos and are great).
My comments are about 2 things you started doing in your live session:
– I always wanted to understand the query first because if you do optimisation then you have to test it and the query someone sent you was wrong
– You started from 58 seconds and stopped when it was 29. And I extended one step from transmission and I could go to below 1s.
Link to this is:
https://www.brentozar.com/archive/2020/08/watch-brent-tune-queries-at-sqlsaturday-oslo/
OK, cool. Like I mentioned, I can’t do free personal one-on-one query tuning advice. Thanks for understanding, and hope you enjoy all the free material I’ve put out there over the years. Cheers!
I enjoy your material cause it is the best stuff about T-SQL and I can catch differencies between Oracle and Microsoft really fast. And I did Oracle on senior level. Now I have to do some things in MS SQL.
I sent my comments because you may find a value too (not because I am looking for advice) and teach others about (you have DBA perspective, I have dev/tester view on it):
1. How not to write SQL queries (this was cross join like query).
2. Understanding SQL queries before tunning cause later you have to test it.
Cheers,
I have recollections of Brent pointing out to me that I didn’t need to persist a computed column in order to index off of it. I guess the same thing applies to statistics.
I wonder if there’d be any benefit to being able create computed statistics (i.e., the computation is attached to the statistics rather than a named column). I don’t think there’d be any *technical* benefit, but maybe there’d be a pragmatic one (e.g., working with code and/or vendors which disallow table modifications, ORM headaches, etc.).