
Last week’s SQL Server 2019 Cumulative Update 9 snuck in some undocumented things.
We got two new DMVs for Always On Availability Groups, sys.dm_hadr_cached_replica_states and sys.dm_hadr_cached_database_replica_states. They have a subset of data from other AG DMVs:
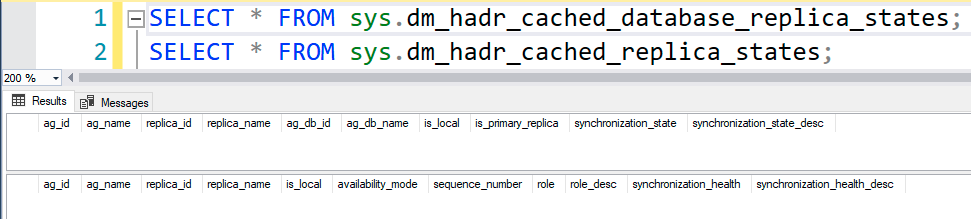
I sure wish I could point you to the documentation or KB article on those.
But we have no idea what changed in CU9 here, or why, or what to do about it.
I’m gonna be honest with you, dear reader: I’m starting to tell clients to choose SQL Server 2017 over SQL Server 2019. 2019 just doesn’t seem like it’s baked, and 2019’s Cumulative Updates have just become too large of a risk: the release notes aren’t honest about you’re deploying. That’s not fair to organizations that depend on SQL Server for mission critical deployments: they need to know what changed so they can be on the lookout for new unusual behaviors.
If your own developers were changing production without telling you how or why, you’d call them into the office, close the door, and have a conversation.
In lighter news, there are also a few new messages in sys.messages:
- 898: Buffer Pool scan took %I64d seconds: database ID %d, command ‘%ls’, operation ‘%ls’, scanned buffers %I64d, total iterated buffers %I64d, wait time %I64d ms. See ‘https://go.microsoft.com/fwlink/?linkid=2132602‘ for more information.
- 7877: Backup on secondary replica is not supported in the connection to contained availability group. Reconnect to SQL Instance and retry the operation.
- 8659: Cannot continue columnstore index build because it requires %I64d KB misc memory per thread, while the total memory grant for query is %I64d KB, total Columnstore bulk insert memory is limited to %I64d KB in query, and the maximum memory grant is limited to %I64d KB per query in workload group id=%ld and resource pool id=%ld. Retry after modifying columnstore index to contain fewer columns, or after increasing the maximum memory grant limit with Resource Governor.
- 35528: unable to read page due to invalid FCB
- 46933: PolyBase configuration is invalid or corrupt. Re-run PolyBase setup.

26 Comments. Leave new
The drop-off in patch note quality was pretty sudden, too.
I’d be willing to bet money that if you looked around on LinkedIn long enough, you’ll find the key person at Microsoft who was passionate about documentation and made sure this stuff got done…. and they probably moved on from the SQL Server team.
That’s always how it is with software teams. A lot of them can’t survive having one good person leave.
Hey, come on. Microsoft are so dedicated to their documentation, and so dedicated to open source, that their documentation is open source!
Oh. Oh, I see.
One question (maybe silly?):
When a new version of SQL server is released (let’s say 2019)… is it like the previous version (2017) but very improved and enhanced (and with new features)? or is it build from scratch? or 50/50?
Thanks
To clarify: I am talking about VERSIONS (2019, 2017, 2014 etc); no CU, Services Pack or whatever similar.
Thanks
Big data killed 2019
Adding features we dont need while ignoring the bug backlog
not cool
but batchmode on rowstore was nice
“Adding features we dont need while ignoring the bug backlog”
You said a mouthful there. That goes for SSMS, as well. A lot of stuff doesn’t work nearly as well as it did before it became a separate product.
For the record, 2017 (RTM) was a performance train wreck.
Jeff,
first, no RBAR 🙂
Um yes thats my thoughts here, for the Nth version fix, SSMS keeps forgetting my SQL Auth passwords, VStudio cant create new SSRS Reports, you have to clone an existing one, etc etc
Backporting bug fixes seems like a full-time thing at MS, at least I dont see the fixes in this 2019 CU in a CU for 2106, One assumes those 2019 bugs dont exist in 2016?
Very confusing
I note that message id 8659 already exists in 2017, with this text.
Cannot create the clustered index “%.*ls” on view “%.*ls” because for clustered indexes on aggregate views without GROUP BY, the only
distribution option supported is DISTRIBUTION=NONE.
Will the delay in CU’s for 2019 mean that Microsoft should extend support? They sort of promise a new CU every month for the first year if I remember correctly and 2019 was released during PASS Summit 2019 in November 2019 and we have just hit CU9 in February 2021.
Now they pulled a Windows update for WIndows 10 and Server 2016.
It is very hard to stay safe.
Together with the SQL2019 CU9 came SQL2016 CU16.
10 days later, (yesterday) , they added SQL2017 CU22 ( they reused the CU number !! )
We may indeed need to perform more detailed testing before launching it in production 🙁
This all is not sustaining product confidence and reliability for SQLServer !
Oh wow, that’s weird – they updated the download page with a new build number, but the KB article still points to the old build number. I bet they just goofed on the download page.
I follow https://twitter.com/SqlServerBuilds and they show CU23 as being prepared. They are usually pretty quick when new CU’s come out as is Glenn Berry.
There’s also a lot of DEK messages in the error log after applying CU9.
Are you using Encryption specifically or are these just appearing when you haven’t enabled encryption?
No idea (it’s a test database server on my laptop, and it may be possible that I tested encryption on it awhile ago), but the point was that there are suddenly messages in the error log which aren’t documented.
Brent, any insight on the DEK messages and why they were added to CU9?
No.
I just installed CU9 and can see the DEK messages at startup. The instance has been up for an hour with no newer messages. Do these only show at startup?
I am seeing them after running DBCC CHECKDB as well.
Just for your information, we got at least two cluster (with AGs) where crashs (one with nasty memory access violation, the other with non yielding scheduler) seems to be related with the CU9 as per Microsoft support finding.
we’ve stopped the deployment of this CU and have rollback to CU8GDR for now.
Now CU10 is out and comes with a warning about Scalar UDF Inlining that is still present and was introduced in CU9.
Looks like another x steps forward and y steps backwards.
It’s funny (or not). Ever since 2019 was announced with having things like auto-magic inlining and other things to “help” performance, I’ve been scared to death. I’ve actually put of upgrading anything to 2019 because of it.
The biggest problem is that I have to change my mantra from not deploying Rev 0 or 1 of anything to waiting until it’s “safe”. Of course, none of us have a clue as to when that will be anymore. 🙁 I wish MS would go back to the idea that the drum beat of continuous deployment needs to be dropped from the orchestra and start releasing things that actually work the first time every time. Uh… that happened once, didn’t it???
Just wondering if your opinion about 2019 has changed since the posting.
Joe – what do you think happened since February’s CU9 that would have changed my opinion?
I have to admit that I’m still concerned about 2019. Just like the changes they made to TempDB in 2016, I hate non-optional “improvements” because the frequently aren’t improvements or they have “a caveat in some cases” that you need to temporarily get around.
A good example of this is that the changes to the Cardinality Estimator absolutely killed a lot of our “big stuff”. Had we not been able to turn it off and go bag to using the old one, we’d have been in seriously deep kimchi for a month of Sundays.