Before I became a consultant, I was on the other side of the conference room table – we would bring in consultants, and I’d be amazed at all the cool lines they whipped out. Now that I’m the one giving advice, I like sharing some of my favorite consulting lines that you can use in your own day-to-day work.
The Conversation
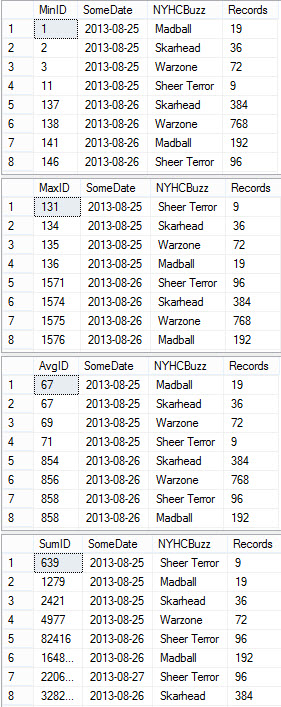
Let’s set the stage: I’m walking a client through the sp_Blitz® results on their production server. They called me in because they were having problems recovering from outages. We’ve found a few nasty surprises.
Me: “Alright, so everyone understands why Dr. Honeydew’s backup script was skipping all the user databases on Tuesdays and Fridays, and what we need to do to fix it, right?”
Beaker: “Yes, I’ll get Ola Hallengren’s maintenance scripts installed tonight.”
Me: “OK, great. Now, while we’re looking at the Agent jobs, what’s this Hourly FREEPROCCACHE one here?”
Beaker: “Oh no. Oh no. Ohhhh, no. I thought I’d gotten rid of that.”
Me: “So it sounds like you already understand why that’s a bad thing?”
Beaker: “Yes! I am so sorry – that was another one of Dr. Honeydew’s experiments, and I thought I’d removed it from every server.”
Me: “Alright, you write that task down now, because I’m not going to include it in your written findings.”
What That Line Does
This line establishes that you’re on their side – you’re not trying to document every tiny little detail of what someone is doing wrong. Nobody needs all of their dirty laundry aired out in public, or in a written document that’s often escalated up the chain or added into someone’s permanent personnel file.

When you’re delivering written findings, you need to focus on just the top relevant issues for their problem. You’re going to find other stuff – but stay focused on what they’re paying you for.
This technique works with code reviews, infrastructure audits, or anything where you’re doing a peer review of someone else’s work.
What Happens Next
Sometimes, they pick up a pen and start writing immediately because they’re ashamed of what you’ve found.
Other times – especially when there’s a group in the room – they need a little encouragement. Everyone just nods and expects you to go on. You have to stop, wait, and look around the room for who’s going to write. Sometimes you even have to ask: “OK, who’s going to write that down and take action on it?”
If you enjoyed that, I’ve got more of my favorite consulting lines.