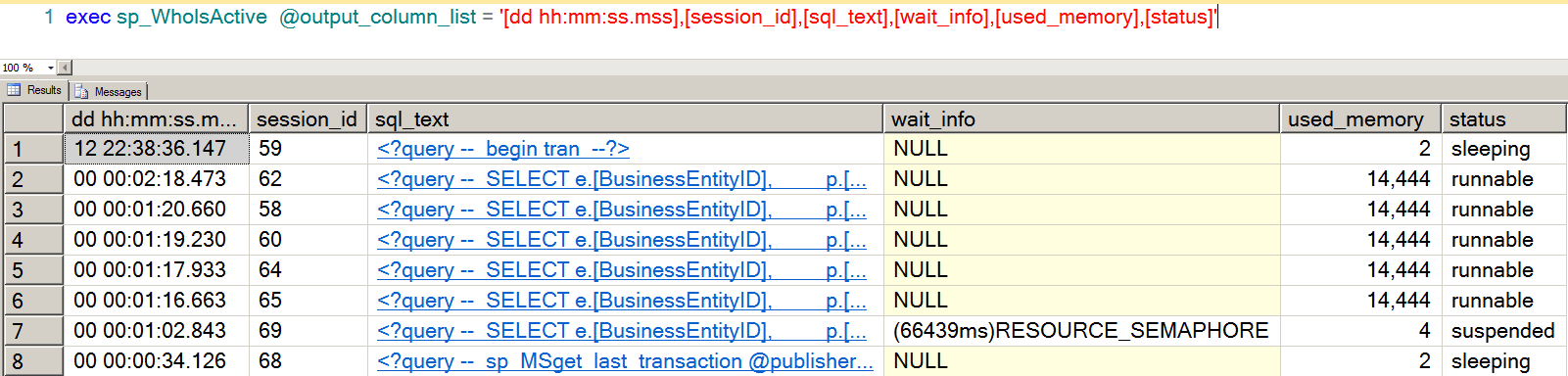
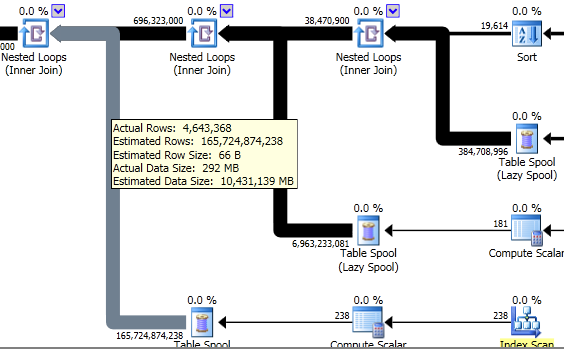
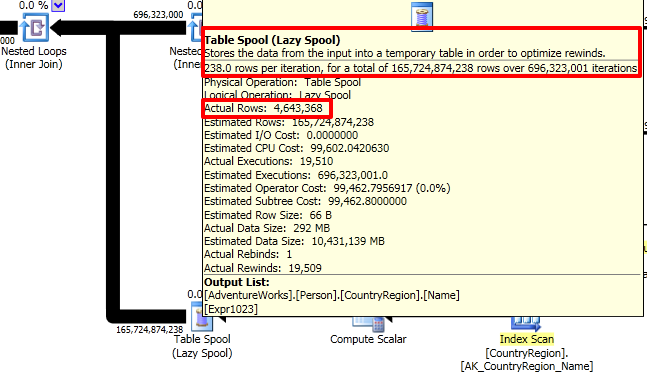
I get to work with everybody. Developers need to push data in and out of the database. End users want to get reports out. Executives want to make better decisions. Vendors need to update code. Anytime something’s happening in the company, I’m one of the first to know.
I get to play with new technologies first. Databases push hardware harder than anything else in the company. When solid state drives started showing up, end users wanted them in the database servers first. When we look at big new servers with lots of memory, odds are they’re for the database.
I don’t have to learn new languages constantly. ANSI SQL has been the same for decades, only incrementally adding new capabilities. I really admire developers who can constantly learn new languages and frameworks, but that ain’t me.

My work often has a beginning and an end. When someone hands me a slow query, I can use my skills to make it go faster, and then hand them the end result. Granted, sometimes they want it to keep going faster, but at least I know when I’m done.
I’m seen as a problem solver. When something’s broken or running slow, I’m usually called in. The bad news is that it’s because they’re blaming the database, but the good news is that I can help get to the real root cause. When I do it right, I’m seen as a helper and a facilitator, not a blame-game guy.
The other IT staff can’t do what I do. It’s not that I’m better than anybody else – I’ve just developed a set of skills that are very specialized, and I take pride in knowing what happens inside the black box.
I have a highly refined BS detector. Because I work with so many different departments, even end users, I’ve gotten used to sniffing out explanations that aren’t quite legit.
I’ve got good job opportunities. There’s still no real college degree for database administrators, and outsourcing isn’t the problem that we expected for a while. Companies still need DBAs, and DBAs still aren’t easy to find. As long as I keep improving my knowledge, I’ve got great career prospects.
I’m in a community of people that love to help. The SQL Server database community is the envy of many disciplines. We love helping each other with free blog posts, webcasts, user groups, SQLSaturdays, mailing lists, forums, you name it.

 Chances are that if there was a disaster and your HA solution kicked in right now, you’d experience the same terrible performance on the other server, too – with the added pain of having downtime to failover.
Chances are that if there was a disaster and your HA solution kicked in right now, you’d experience the same terrible performance on the other server, too – with the added pain of having downtime to failover.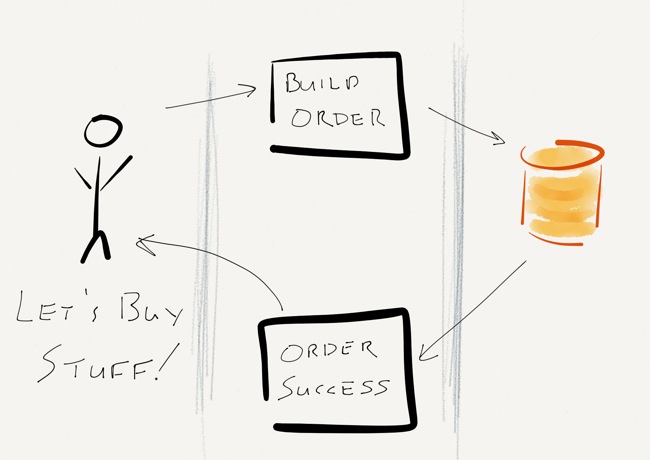


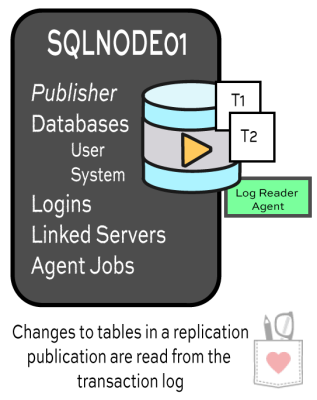

 data to subscribers can be… challenging.
data to subscribers can be… challenging.


 Allen: Board Members set the direction and future vision for the organization. In a more perfect world they might solely be responsible for the strategic direction of the organization much as a typical corporate board of directors is but, because of the unique nature of the organization if a particular director has a passion for how a certain area of PASS should be different they can become quite tactical and put in the actual work to accomplish their goals.
Allen: Board Members set the direction and future vision for the organization. In a more perfect world they might solely be responsible for the strategic direction of the organization much as a typical corporate board of directors is but, because of the unique nature of the organization if a particular director has a passion for how a certain area of PASS should be different they can become quite tactical and put in the actual work to accomplish their goals.