I recently went to Shanghai & Hong Kong, and stopped to take your questions from https://pollgab.com/room/brento while sitting next to the Hong Kong harbor.
Here’s what we covered:
- 00:00 Start
- 01:18 Jason G – RN & Accidental DBA: Would you elaborate on DB Owner implications? sp_Blitz help recommends using the SA account, but the articles referenced by Andreas Wolter advocate for using low privileged accounts which are DB specific. Which would you recommend and why?
- 02:44 MyTeaGotCold: Can you name any good relational databases that aren’t built around SQL? It’s strange that a system so old is still the best.
- 03:58 John: Hello Brent. Is SQL Server 2022 ready for production/prime time and more more huge bugs/issues? Asking due to last blog post was in 2023 on that particular topic. Thanks.
- 04:57 Chicago Joe: Is there a trend to move database access to API only? I am asking because we are moving to next version of ERP and our CIO has told database developers that only access to new database will be through a Web API. Database is still on prem on next version, too.
- 06:23 J. Fisher: Hey Brent, Are you able to comment/explain SQL Server “Native” Geography/Geometry datatypes, other CLR stuff, and how they can use and exhaust “App Domain” memory… leading to “Unloading due to memory pressure”… Can’t “afford” to keep adding memory.
- 08:19 Steve E: Hi Brent, Is there a way to assess overall reads per table across a workload in an attempt to see which tables we might want to focus our index tuning efforts to? Eg if the Posts table has 90% of the overall workload reads, we would probably want to start our index tuning there.
- 09:29 neil: dev thinks “azure” will solve all their problems. (they dont understand we’re already sql on azure vm). they’re committing all the same mistakes that created disasters on-prem. what surprises are they in for ?
- 11:12 Dream catcher: What time do you like to go-to bed and wake up? Do you nap after lunch?
- 11:43 ChompingBits: What do you think is nominally the difference between ADF and SSMS? ADF has query plans and access to many of the admin tools and reports in SSMS. How long do you think Microsoft will continue to offer both tools.
- 12:45 gringomalbec: Hi Brent, we realize you recommend not using Linked Servers to connect to other MS SQL Servers. But my friend asks if you find ok using Linked Servers to download data from sources other than MS SQL Server that cannot be connected directly in SSMS using Database Engine ?




 If your company is hiring, leave a comment. The rules:
If your company is hiring, leave a comment. The rules: I’d like to teach you How to Think Like the SQL Server Engine for free.
I’d like to teach you How to Think Like the SQL Server Engine for free.

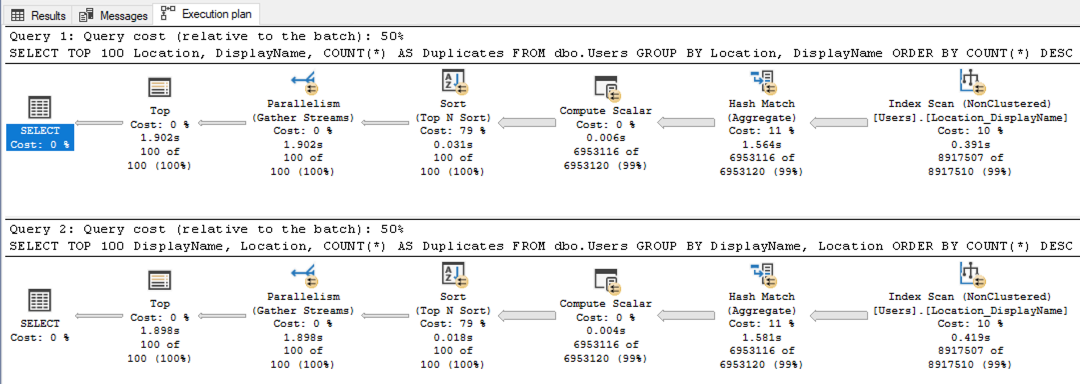


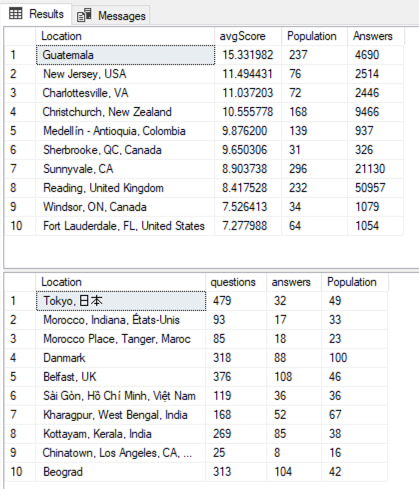
 As an example, I’m showing a picture of one answer’s results here. The person shouldn’t be ashamed by any means – this was a hard question, for sure – but it serves to illustrate an answer that doesn’t pass the sniff test. The top result set are the helpful locations, and the bottom result set are the locations that need help. A single location shouldn’t be in both – and yet the same locations show up in both list. This is just a list of the biggest locations, basically.
As an example, I’m showing a picture of one answer’s results here. The person shouldn’t be ashamed by any means – this was a hard question, for sure – but it serves to illustrate an answer that doesn’t pass the sniff test. The top result set are the helpful locations, and the bottom result set are the locations that need help. A single location shouldn’t be in both – and yet the same locations show up in both list. This is just a list of the biggest locations, basically.