
If you’ve got good indexes to support your query, and statistics to help SQL Server guess how many rows will come back, how can SQL Server still come up with terribly incorrect row estimates?
To demonstrate, I’ll use the 2018-06 version of the Stack Overflow database, but any recent version will work as long as you understand the problem with this demo query:
|
1 2 3 4 5 |
SELECT * FROM dbo.Users WHERE CreationDate > '2018-05-01' AND Reputation > 100 ORDER BY DisplayName; |
I’m asking SQL Server to find users created in the last month (because I’m dealing with the database export that finished in June 2018), who have accumulated at least 100 reputation points.
SQL Server knows:
- There have been a lot of users created in the last month
- There are a lot of users who have > 100 reputation points
But he doesn’t know that that’s a Venn diagram of people who don’t overlap:

So when I run the query and get the actual execution plan – even though I’ve created two supporting indexes, which also create supporting statistics:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DropIndexes; GO CREATE INDEX CreationDate_Reputation ON dbo.Users(CreationDate, Reputation); CREATE INDEX Reputation_CreationDate ON dbo.Users(Reputation, CreationDate); GO SELECT * FROM dbo.Users WHERE CreationDate > '2018-05-01' AND Reputation > 100 ORDER BY DisplayName; |
SQL Server’s actual execution plan ignores both indexes and does a table scan:

To understand why, we read the query plan from right to left, starting with the Clustered Index Scan operator. It says “419 of 40041 (1%)” – which means SQL Server found 419 rows of an expected 40,041 rows, just 1% of the data it expected to find.
SQL Server over-estimated the population of users because it didn’t know that very few recently created users have earned over 100 reputation points.
Why you care about estimation problems
(once you’ve learned about ’em)
The overestimation means SQL Server doesn’t think using the indexes will be efficient here. SQL Server thinks there will be too many key lookups, which would result in a higher number of logical reads than scanning the whole table.
He’s wrong, of course, and we can prove that by copying the query into a new version with an index hint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SET STATISTICS IO ON; SELECT * FROM dbo.Users WHERE CreationDate > '2018-05-01' AND Reputation > 100 ORDER BY DisplayName; SELECT * FROM dbo.Users WITH (INDEX = CreationDate_Reputation) WHERE CreationDate > '2018-05-01' AND Reputation > 100 ORDER BY DisplayName; |
The first query does a table scan and 142,203 logical reads.
The second query does an index seek and 1,735 reads – that’s 82x less reads! SQL Server should be choosing this index, but doesn’t, and that’s why you care.
Index hints aren’t the answer, either.
Because here’s the query plan with the index hint:
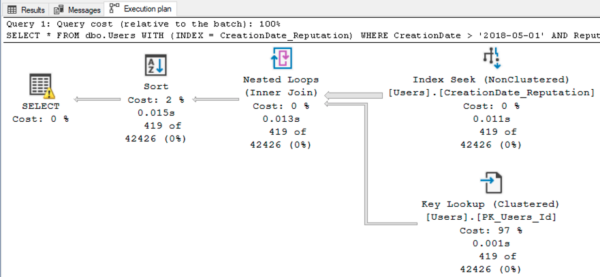
See the yellow bang on the select? Hover your mouse over it:

Because SQL Server overestimated the number of rows it’d find, it also overestimated the memory required (leading to Page Life Expectancy dropping, for those of you who track that kind of thing.) In real-life-sized queries, this kind of operation usually causes SQL Server to allocate multiple CPU cores for parallel operations, too, leading to CXPACKET waits when those cores aren’t actually used.
What’s the real solution? Sadly, it’s not as simple as building your own fancy filtered statistics or indexes because date & reputation values are usually parameters that can be set by the user, and vary. I cover better solutions in my Mastering Query Tuning class.

11 Comments. Leave new
When you created those indexes and had statistics built – why did SQL server still over estimate the number of rows? It sounds like you’re saying because the parameter values always change. But with statistics and indexes in place shouldn’t SQL Server be able to come up with an appropriate execution plan?
When you say “why”, that becomes a tricky question.
If you’re asking, “What happened that caused SQL Server to over-estimate the number of rows,” that’s the Venn diagram picture. SQL Server uses each statistic independently: it knows how large each circle is, but it doesn’t know how the circles overlap.
If you’re asking, “Why hasn’t Microsoft fixed that?”, you would want to ask Microsoft that, not some fella with a blog. 😉 But I would hazard a guess that they don’t fix things people don’t complain about, much less don’t KNOW about. Most folks don’t even know about this level of estimation problem.
I didn’t notice it either until it became grossly obvious yesterday when we found a query in production asking for 11 GB of memory and it only needed 25 MB.
Clearly, the fix is for Microsoft to add a “estimate rows” query hint or a “memory grant” query hint.
No, I’m not being serious.
Maybe I am looking at this wrong but does “update statistics” not help this or am I being too simplistic here?
No, that doesn’t help here either. Definitely download the databases and give ‘er a try – that’s why I use open source databases and scripts, so you can test those kinds of ideas.
Hi Brent!
Thank you for this great post!
What happens if you set the compatibility level = 150 when you use index hint.
I think IQP (memory grant feedback) can help.
Regards!
Hi, Mehdi. Like we talked about yesterday in email, I can’t do work for you for free.
If you want me to do work for you, you need to click Consulting or Training at the top of the site.
Thanks for understanding. (And for the record, no, memory grant feedback does not help with row estimates.)
I also rewrote the query as follows
SELECT Id into #Tbl
FROM dbo.Users
WHERE CreationDate > ‘2018-05-01’
AND Reputation > 100
Select u.* From dbo.Users
Inner join #Tbl
On u.id = #Tbl.id
ORDER BY DisplayName
Thanks again!
Yes sir!
I just wanted to share my test result. Thank you!
No, Mehdi, you’re commenting on something else. I’m talking about where you asked me to do work for you.
Let’s call it quits here, okay? Thanks for understanding.