
We’ve been working with the clustered index of the Users table, which is on the Identity column – starts at 1 and goes up to a bajillion:

And in a recent episode, we added a wider nonclustered index on LastAccessDate, Id, DisplayName, and Age:
|
1 2 3 |
CREATE INDEX IX_LastAccessDate_Id_DisplayName_Age ON dbo.Users(LastAccessDate, Id, DisplayName, Age); GO |
Whose leaf pages look like this:
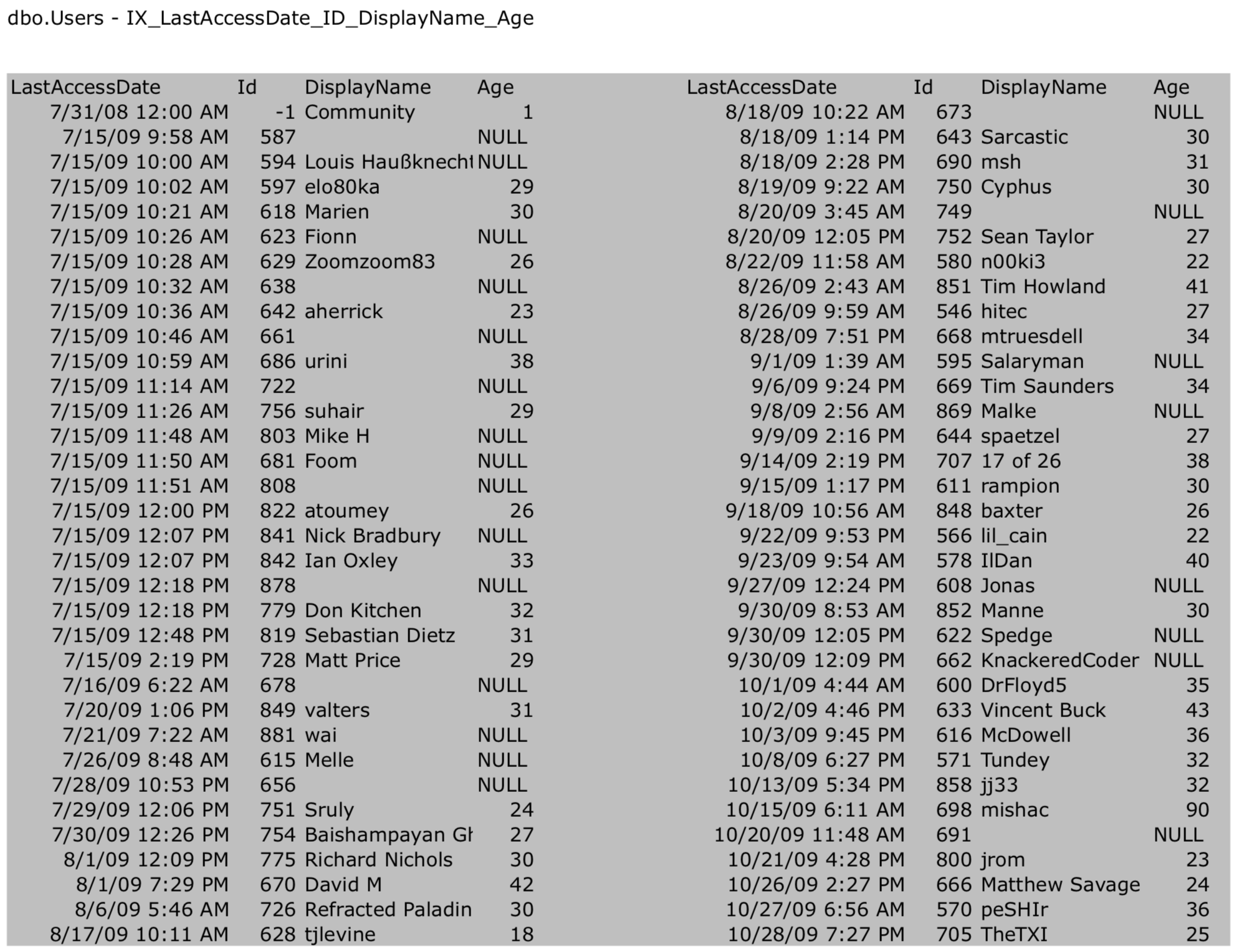
So what’s going to happen when we run this query:
|
1 2 3 |
SELECT Id FROM dbo.Users WHERE DisplayName = N'Brent Ozar'; |
DisplayName is in the nonclustered index,
but we can’t use it for seeks.
If you look at the gray pages of the index, they’re organized by LastAccessDate, then Id, then DisplayName. We can’t use the gray pages to seek directly to Brent.
In this case, most people think SQL Server is going to scan (not seek) the entire clustered index (white pages.) If we don’t have an index that directly supports our query, we think SQL Server’s going to resort to scanning the table. Good news, though: it’s way smarter than that.
SQL Server says, “If I have to scan the entire table to find some rows, what’s the narrowest/smallest copy of the table that I could scan in order to achieve my objectives?” After all, it can use the gray index – it’s just going to scan it, the same way it would scan the clustered index. Which index is smaller/larger? Let’s use sp_BlitzIndex to find out:
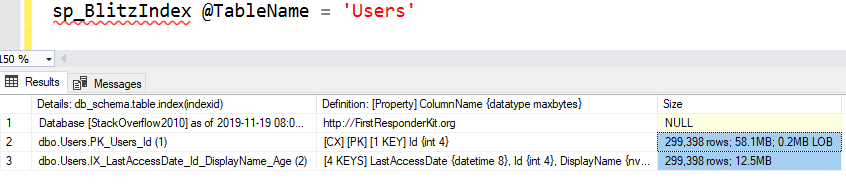
- The CX/PK is the clustered index, and it’s 58.1MB.
- The nonclustered index (gray pages) is 12.5MB.
Both of them have the same number of rows (299,398) – so all of the rows in the table are included in both objects. Both of them have everyone’s DisplayName. So if you’re looking for people by DisplayName, you would much rather scan 12.5MB of pages than 58.1MB of pages – and SQL Server feels the same way. It uses the gray pages:

Number Of Rows Read = 299,398 because SQL Server had to scan the entire index in order to find the Brent Ozars. Only one of us showed up. (Thank goodness.)
Estimated Number of Rows Read = 299,398 because SQL Server knew it was gonna read the whole table to find me. If we’d have said SELECT TOP 1, then SQL Server would have been able to quit as soon as it found a matching row, so it might have been able to read less rows.
Predicate = @1 is a little tricky. Note that it says Predicate, not Seek Predicate. The word “Predicate” by itself means SQL Server is looking for this data, but it couldn’t seek directly to the rows we were looking for – because DisplayName wasn’t first in the index.
To get a seek predicate,
we need an index that starts with DisplayName.
Let’s create one, and rerun our query:

Now that’s better: SQL Server is able to seek directly to DisplayName.
Number of Rows Read = 1, and so does Actual Number of Rows. That means you’ve got a really good index for your query’s goals: SQL Server is able to read exactly as many rows as it needs, no more.
We now have a Seek Predicate, not just a plain ol’ Predicate. I really wish that instead of just saying “Predicate”, SQL Server would call them Scan Predicates, because when you see the word “Predicate” by itself, you’re likely reading more rows than you actually need – and it’s a sign that you could improve performance by doing index tuning.
When you’re designing indexes, the first column matters a lot.
You’ll hear folks say that the first column should be really selective, or really unique. That’s kinda sorta true, but not really – we go into more details on that in my Fundamentals of Index Tuning class.
What IS important is that the first column needs to be something you’re filtering on. If my queries aren’t filtering by LastAccessDate – like the example in this post – then an index that starts with LastAccessDate isn’t going to be very helpful, even though LastAccessDate is extremely selective (unique).
However, even if you’re seeking on the first column doesn’t mean that you’re done with index design. A single query can get a mix of seek predicates and scan predicates, too – more on that in the next episode.

2 Comments. Leave new
Excellent as always. This makes me think of another “leading column” question that I’ve never sat down and thought about properly. What are the advantages/disadvantages of putting a non-selective column (like Gender) first or last in a composite index? I have some ideas but I’d much rather read an entertaining explanation from yourself.
Nick – great question, and I cover that in the Fundamentals of Index Tuning class.