
Michael J. Swart posted an interesting question: he had a large table with 7.5 billion rows and 5 indexes. When he deleted 10 million rows, he noticed that the indexes were getting larger, not smaller.
Here’s one way that deletes can cause a table to grow:
- The rows were originally written when the database didn’t have Read Committed Snapshot (RCSI), Snapshot Isolation (SI), or Availability Groups (AGs) enabled
- RCSI or SI was enabled, or the database was added into an Availability Group
- During the deletions, a 14-byte timestamp was added to each deleted row to support RCSI/SI/AG reads
To demonstrate the growth, I took the Stack Overflow database (which doesn’t have RCSI enabled) and created a bunch of indexes on the Posts table. I checked index sizes with sp_BlitzIndex @Mode = 2 (copy/pasted into a spreadsheet, and cleaned up a little to maximize info density):
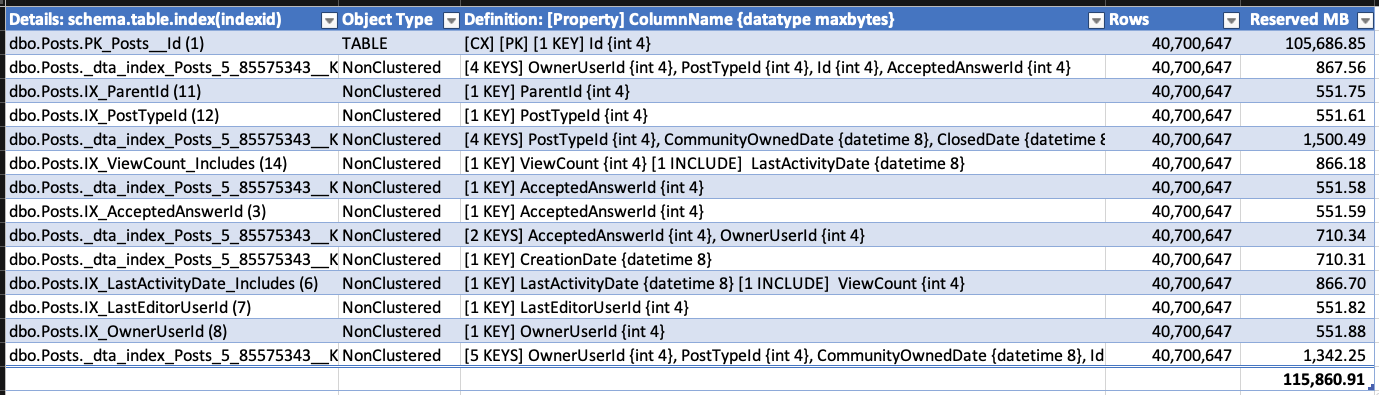
I then deleted about half of the rows:
|
1 2 3 |
BEGIN TRAN; DELETE dbo.Posts WHERE Id % 2 = 0; GO |
Amusingly, while the deletes were happening, the data file was growing to accommodate the timestamps, too! The SSMS Disk Usage Report shows the growth events – here’s just the top to illustrate:
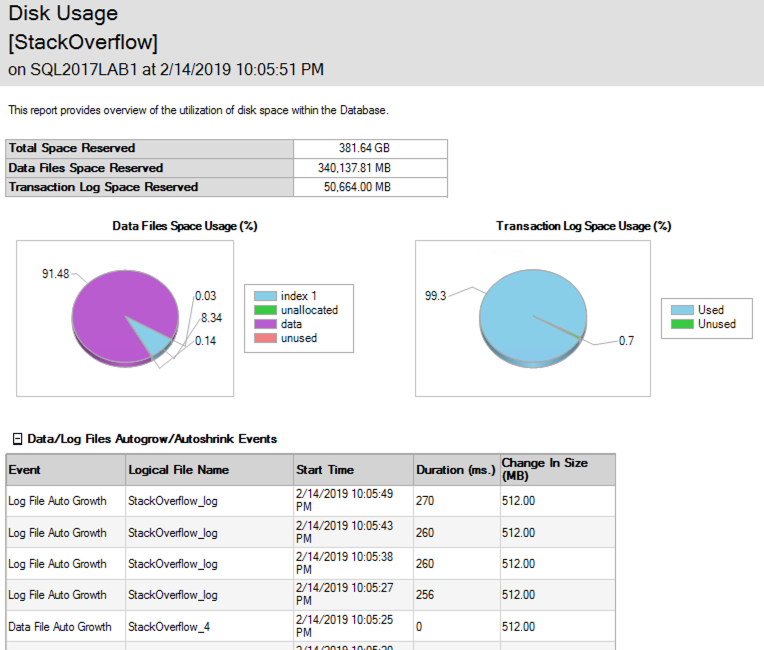
(Gotta love a demo where deletes make the database grow.) While the delete was running, I ran sp_BlitzIndex again. Note that the clustered index has less rows, but its size has already grown by about 1.5GB. The nonclustered indexes on AcceptedAnswerId have grown dramatically – they’re indexes on a small value that’s mostly null, so their index sizes have nearly doubled!
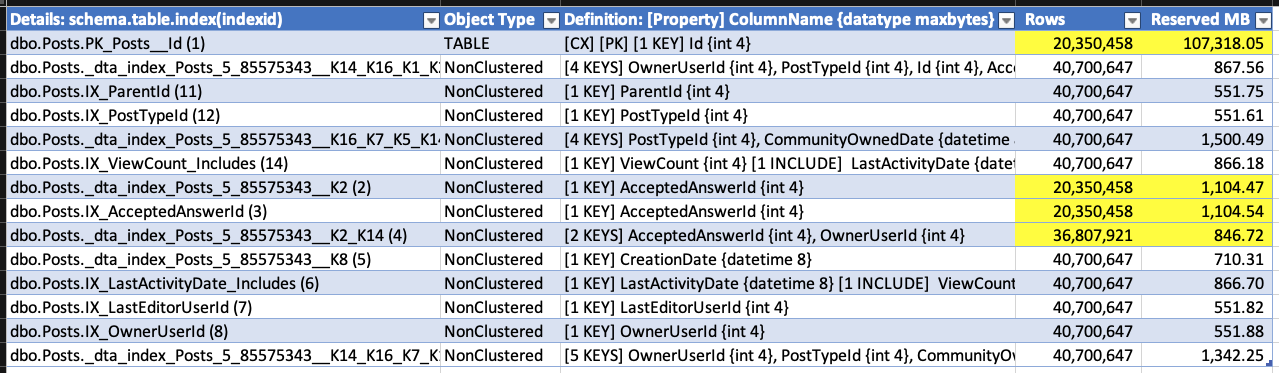
I don’t have to wait for the deletion to finish to prove that out, so I’ll stop the demo there. Point being: when you do big deletions on a table that was implemented before RCSI, SI, or AGs were enabled, the indexes (including the clustered) can actually grow to accommodate the addition of the version store timestamp.
Things you might take away from this:
- RCSI, SI, and AGs have cost overheads you might not initially consider
- After enabling RCSI, SI, or an AG, rebuild your indexes – not that it’s going to make your life better, it’s just that you can control when the page splits, object growth, fragmentation, and logged activity happens instead of waiting around for it to hit when you’re in a rush to do something
- Offline index rebuilds seems to have a related effect too – Swart noted in a comment that when he tested them, they were rebuilt without the 14-byte version stamp, meaning that subsequent updates and deletes incurred the page splits and object growth
- I have really strange hobbies

21 Comments. Leave new
“Offline index rebuilds seems to have a related effect too… they were rebuilt without the 14-byte version stamp”
They were built without the timestamp even though the dB had RCSI/SI/AG enabled? Were the original rebuilds (that caused the growth) done “online”? If so, do you think it is the “online” index rebuild that is causing the addition of the timestamp?
David – for questions about that, please leave the questions on the Stack post so the right folks can see ’em. Thanks!
Thanks again Brent for the ideas and doing a lot of the leg work here.
As a follow up to our story, we continued deleting rows (carefully in batches!) and with some patience, the ghost record cleanup job came along and did its job. The ghost cleanup job is a background process and it’s hard to understand exactly what it works on and when, but when it finally kicked in, we saw the index sizes shrink as expected.
My pleasure, sir!
Michael,
Just to clarify- if to be a bit patient and wait till ghost cleanup job be completed then nothing mystical happened, i.e. after deletion table size will be smaller?
Or another words described table increase during deletion is temporarily phenomenon?
Good question. I left another comment at the dba.stackexchange question.
https://dba.stackexchange.com/questions/229796/
My instinct is that deleting rows could also make a table bigger if it degrades compression (assuming the use of page compression or the use of a columnstore index).
It’s probably cheaper to store “all the integers from 1 to 1,000,000” than to store a random 90% of “all the integers from 1 to 1,000,000.”
Hmm, that would be an interesting test! You should try that.
There *might* be a corner case, where this could happen, but I doubt it. And it’s too early on a Monday for me to say definitively that it won’t.
(More on Page Compression here; https://am2.co/2016/02/data-compression-how-page-works/)
Page Compression works by combining 3 compression algorithms to compress a page, but it’s basically just de-duping stuff. It writes repeated values once on the page header, then rows that contain that value get a pointer, rather than repeating the value. A page-compressed row contains non-compressible stuff & a pointer to the header (with the full value). If you delete that row, when SQL Server re-writes the page, it might not compress the same, but I don’t believe there is a path where deleting a row causes the page suddenly becomes bigger, requiring a page split to re-write the page.
[…] Brent Ozar shows a case where indexes can grow in size as you delete data: […]
Not totally related but one of my tables had grown to 14GB last week and only had around 2000 rows in it. The issue seems to be caused by repeatedly doing DELETE * instead of TRUNCATE. I found another table doing the same thing last year and the fix was to truncate rather than delete. This is on a SQL 2008 R2 server and the table is a heap with no indexes.
Until a TRUNCATE is executed, SQL still does a huge number of logical reads even when there is no data in the table:
SELECT * FROM [ATable]
(2011 rows affected)
Table ‘ATable’. Scan count 1, logical reads 921517, physical reads 135, read-ahead reads 843206…
DELETE FROM [ATable]
Table ‘ATable’. Scan count 1, logical reads 921517, physical reads 0, read-ahead reads 843206…
(2011 rows affected)
SELECT * FROM [ATable]
(0 rows affected)
Table ‘ATable’. Scan count 1, logical reads 921517, physical reads 0, read-ahead reads 843206…
TRUNCATE TABLE [ATable]
SELECT * FROM [ATable]
(0 rows affected)
Table ‘ATable’. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0…
I don’t know why but the table just seems to grow larger and larger with DELETE *.
Similar issue here:
https://community.spiceworks.com/topic/239033-simple-query-has-way-too-many-logical-reads
You most likely have a heap. https://www.brentozar.com/archive/2016/07/fix-forwarded-records/
It is surprising though (to me anyway) that a 200MB table can grow to 14GB just by constantly deleting all of rows in it then inserting a few thousand back.
Yep, the magic of heaps. If you love it, put a clustered index on it.
I pressed the imaginary like button for that quote!
There’s a rarer issue with the same symptoms (lots of inserts/deletes and large logical reads) It may be a broken ghost cleanup process:
http://michaeljswart.com/2017/08/problem-with-too-many-version_ghost_records/
How do you figure the DELETE caused the table to grow? In each case, there was a full scan and in each case prior to the TRUNCATE, there was an identical number of logical reads… which means the table neither grew nor shrunk.
Also, pages are not deallocated immediately after a delete. The ghost cleanup has to be given time to do its job. You might be able to force something earlier by doing a CHECKPOINT.
Apologies… that last comment of mine was directed to Richard. That’s not totally apparent by the resulting placement of my post.
To be honest it is an assumption but it looks like something in the populate, delete, populate, delete, populate process is causing the table to grow.
This spreadsheet tracks the database size and used space over time and you can see that it is slowly growing:
https://www.dropbox.com/s/ts5thrzuijiype6/DBGrowth.xlsx?dl=0
The drop in size on the 3rd May 2018 was when I first noticed the problem on another table and truncated it. The database has then slowly grown again until I did another truncate on the 9th March 2019.
It also dropped in size when I did a shrink on the whole database on the 23rd March 2019.
Ah… understood. The DELETEs probably didn’t cause the database to grow, in this case. If the pages weren’t deallocated auto-magically from the file, then they continued to occupy space in the database file. Populating the table with new rows may cause new pages to be formed instead of reusing the old pages as a result. Shrinking the database file not only causes the deallocation of old empty but still allocated pages but will also remove them from the database file.
As with all else with SQL Server, “It Depends”.
That makes sense, thanks. It is crazy that the table can get so large though and definitely something to be aware of.