
This week, we’re all about foreign keys. So far, we set up the Stack Overflow database to get ready, then tried to set up relationships, and encountered cascading locking issues.
Dawn Of The Data
I don’t know how long the recommendation to index your foreign keys has been a thing, but I generally find it useful to abide by, depending a bit on how they’re used.
Without foreign key indexes, when SQL Server needs to validate data, or cascade actions, well, this could end up being pretty inefficient for large data sets. I’m not saying it’s the end of the world, but it’s an avoidable problem.
There’s also been this recommendation to create single key column indexes on your foreign keys, and to keep them around even if it doesn’t look like they’re being used. I’ve always found that curious. Do you really need that, if you’ve got a multi-column index that leads with the foreign key column?
That’s what I wanted to find out when I started writing this post.
Starting Point
To make things relatively easy, we’re going to use a single key column foreign key between Users and Badges.
Why? Because they’re two of the smaller tables, so it takes less time to add different things.
This is how most decisions get made. Don’t act disappointed.
|
1 2 3 |
ALTER TABLE dbo.Badges ADD CONSTRAINT fk_badges_users_id FOREIGN KEY (UserId) REFERENCES dbo.Users(Id) ON DELETE CASCADE; |
I’m going to start with no nonclustered indexes, and then I’m going to create some with different columns, and column orders. The point here is that we don’t have an index just on the foreign key column, but we do have an index that contains it.
No Indexes
First, let’s test a query that should be eligible for join elimination. Do we need indexed foreign keys for that?
|
1 2 3 4 5 6 7 |
SELECT b.UserId, COUNT(*) AS records FROM dbo.Users AS u JOIN dbo.Badges AS b ON u.Id = b.UserId GROUP BY b.UserId HAVING COUNT(*) > 1000; |
Here’s the query plan:

Well, it’s not that this query couldn’t benefit from some index help, but we totally eliminate the join to Users. That’s a good sign, though. Our foreign key is strong. Strong like lab rat.
We Learned Something
Even with no supporting indexes, we can still get join elimination. And this makes total sense. The constraint is there, and it’s trusted.
Maybe the advice to always index foreign keys is more like “usually” or “it depends”. If we don’t need to index foreign keys for join elimination, what do we need them for? Let’s look at a query that doesn’t get join elimination.
We’re going to break that optimization by selecting a column from the Users table. When we need data from a table, the join can’t be eliminated.
We’re also going to filter on the Date column in the Badges table.
|
1 2 3 4 5 6 7 8 9 |
SELECT b.UserId, u.Reputation, COUNT(*) AS records FROM dbo.Users AS u JOIN dbo.Badges AS b ON u.Id = b.UserId WHERE b.Date >= '20120101' GROUP BY b.UserId, u.Reputation HAVING COUNT(*) > 1000; |
Here’s the query plan:

This query runs in about a second On My Machine®
Is it the greatest plan of all time? No. Could an index help? Yes.
But would I count on an index just on my foreign key column being a huge performance win? No, and SQL Server is with me on this. When I tested that, the optimizer totally ignored a single column index on UserId. We got the same plan as above. Let’s throw a couple wider indexes into the mix, and see which one the optimizer picks.
|
1 2 |
CREATE INDEX ix_apathy ON dbo.Badges(UserId, Date) INCLUDE(Name); CREATE INDEX ix_ennui ON dbo.Badges(Date, UserId) INCLUDE(Name); |
Here’s the query plan:

We use the index on Date, UserId. The wider index is helpful, here.
Summary So Far
- We don’t need to index foreign keys for join elimination
- A single column index on the foreign key was ignored by the optimizer
- We needed to add a wider index that was more helpful to our query
It seems like the wiser choice after these experiments is to index for your queries, not your keys. Queries, after all, tend to be more complicated than keys, and need more indexing support.
Whatabouts
I know, I know. Modifications. Cascading things.
Here’s the thing: For a single row insert, I couldn’t get any permutation to behave much worse than the others.
|
1 2 3 4 |
BEGIN TRAN INSERT dbo.Badges ( Name, UserId, Date ) SELECT 'WICKED AWESOME THING', 22656, GETDATE() ROLLBACK |
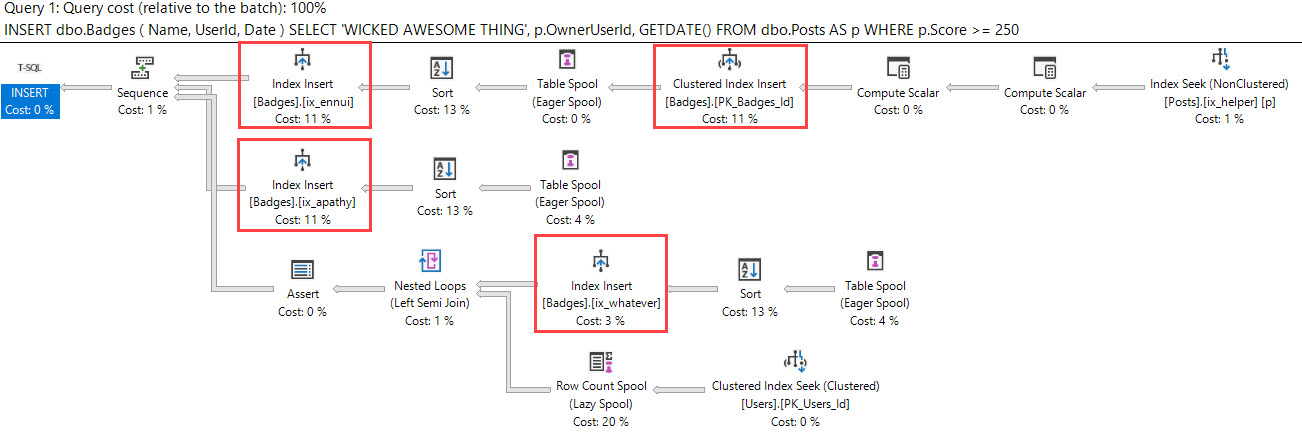
For a larger insert of about 20k rows, well, it was a lot like other modifications. It got a little worse with each index I added — including the single column index on UserId.
One indexes:
|
1 2 3 4 5 6 7 8 |
--CREATE INDEX ix_ennui ON dbo.Badges(Date, UserId) INCLUDE(Name); Table 'Badges'. Scan count 0, logical reads 10040, physical reads 0, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Users'. Scan count 1, logical reads 44477, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Posts'. Scan count 1, logical reads 51, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 500 ms, elapsed time = 521 ms. |
Two indexes:
|
1 2 3 4 5 6 7 8 9 |
--CREATE INDEX ix_apathy ON dbo.Badges(UserId, Date) INCLUDE(Name); --CREATE INDEX ix_ennui ON dbo.Badges(Date, UserId) INCLUDE(Name); Table 'Users'. Scan count 0, logical reads 43099, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Badges'. Scan count 0, logical reads 149526, physical reads 0, read-ahead reads 30, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 2, logical reads 43175, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Posts'. Scan count 1, logical reads 51, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 641 ms, elapsed time = 669 ms. |
Three indexes:
|
1 2 3 4 5 6 7 |
Table 'Users'. Scan count 0, logical reads 43099, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Badges'. Scan count 0, logical reads 192433, physical reads 0, read-ahead reads 21, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 3, logical reads 43372, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Posts'. Scan count 1, logical reads 51, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 625 ms, elapsed time = 646 ms. |
With every extra index, we do a lot more work on Badges, and the Worktable used to spool rows throughout the plan. We don’t do any more on reads on Users or Posts. This is just like other data modifications: The more indexes you have, the more overhead you have.
Chasing Waterfalls
The same thing goes for when modifications cascade. With more indexes, you have more overhead. In this case, with a delete, we now have to remove data from four indexes.

Let’s Get Out Of Here
In general, I don’t find single column indexes very appealing. They’re just not terribly helpful to many queries. I can’t recall seeing too many queries that just selected one column from one table, with some relational operation on just that one column. And when I have, most of the time it was already the PK/CX of the table anyway.
So, do you have to create an index on all your foreign key columns, and just your foreign key columns, and keep them regardless of if they’re used?
It doesn’t look like it to me. I’d much rather have people index for their queries than index just to satisfy a “rule”.
Just as an example, you have a table with a high rate of data modification, and you…
- Have an unused single column index on the FK
- Have wider indexes that do get used
- Have at least one of those indexes contain the foreign key column
It just may make that unused single column index not worth keeping around.
In the next post, we’ll look at some more queries that don’t qualify for join elimination.
Thanks for reading!

6 Comments. Leave new
In addition to the case where a single column FK index is not chosen by the optimizer, I’ve also seen cases where it gets used in a seek, but there are many more rows read than returned. In most such cases, there is both a Seek Predicate and a (non-seek) Predicate visible in the properties for the Seek operator, indicating that there are one or more key columns that could be added to the index that would cut down on the number of rows read, and therefore reduce logical reads, and therefore improve performance.
“It just may make that unused single column index not worth keeping around.” Yes, overlapping indexes are often just a drag on write performance without any benefit. However, there are cases where there is a single column index, and an overlapping multi-column index with a lot of include columns (or large ones or both) that is needed for some queries, but that single column index is still used because it is much smaller. In that case, it may be worth keeping both depending on the workload. Something like sp_BlitzIndex or sp_IndexAnalysis (from Jason Strate) can help in making that determination.
loving the deep dive into foreign keys – a hugely useful construct when handled properly (if sql trusts, i don’t *have* to verify) but too often maligned (because “performance”). however, i’m not sure i understand how the examples in the post really address the issue of what you should index, how and why.
for example, the three INSERT query plans…well, aren’t these basically what you’d get if you had those indexes on that table, regardless of the FOREIGN KEY business? there are 3 NC indexes to maintain, after all.
ditto for the DELETE example…yes, it was initiated by a cascade (which we agreed not to do), but the nasty part is the DELETE against dbo.badges, is it not? i.e. it’s not terribly different than if you were to simply run DELETE Badges WHERE UserID = 22656…so it doesn’t tell me much about FOREIGN KEYs.
what i would be curious to see more about – the question i think that really needs answering – is the performance of regular, every day operations against the parent / child tables where you’re not using cascading for deletes.
specifically:
1.) INSERTS to the child table (badges) – how is the perf of checking the parent affected by such things as parent table width where a unique non-clustered index is bound to by the engine? what if that unique NC index on the parent has an INCLUDE or is multi-column but slightly wider?
see: https://weblogs.sqlteam.com/dang/archive/2012/05/27/secrets-of-foreign-key-index-binding.aspx
the extant indexes on the parent table at time of FK creation on the child dictate which parent index the engine will bind the FOREIGN KEY to…SQL Server prefers non-clustered indexes if available, and in the abstract, so would i. would it be worth having an otherwise redunant unique NC index on Users.ID to speed inserts to badges and keep PK_Users from getting locked into the bargain?
2.) DELETES from the parent table. say we have our own process for cleaning up child tables before removing the parent record from dbo.users – i.e. *we’re* reasonably sure there are no orphans lying around, but SQL server still has to check. Moreover, imagine that dbo.users is oft-queried and related to many child tables, and/or that badges is big. what kind of indexes would we want on dbo.badges to help sql server quickly determine that there will be no orphans?
this is why i (might) slap a single column index on badges.userid – not to make SELECTS/JOINS better, but to make DELETEs against dbo.Users not suck. without said index, isn’t every delete against dbo.users going to mean a scan of dbo.badges (and every child), which sucks for both dbo.badges and dbo.users?
Mike — Yeah, I could have written a couple more parts to this to look at other things, but I had to draw boundaries on it somewhere, and I picked the stuff about FKs that made me curious.
If you wanna shoot me an email or Slack DM about your ideas, maybe I can add a piece to this down the road.
Thanks!
@Mark Freeman agreed on both points.
there’s another potential single-column index to be considered here: the index on the parent table to which the foreign key is bound. very often, this is just the PrimaryKey/Clustered index–but not always! (see: https://weblogs.sqlteam.com/dang/archive/2012/05/27/secrets-of-foreign-key-index-binding.aspx)
in sum: the indexes on the parent table as they exist at time of FK creation dictate how sql server will check parent going forward. When the FK is created, sql server binds it to (some) unique on the parent. SQL Server 2008+ prefers a (theoretically skinnier) unique non-clustered index if available, and in the abstract, so would i–especially if the parent table is particularly wide, oft-modified, has lotsa rows, etc. etc. however, i’ve seen this strategy backfire, too, when the engine starts using your (duplicative) NC UNIQUE index + key lookups to serve non-covered queries on the parent when a scan (in the absence of a covering index on the parent) would’ve been better. the cost to maintain a duplicative UNIQUE NC INDEX on top of your typical numeric PK on is almost zero and more than worth it in terms of benefit of faster lookups from one/many children – it would be sweet if you could mark such a thing as for FK lookups only.
[…] medida que lia o artigo 4, cujo título é “How to Index Foreign Keys”, percebia semelhanças com as observações iniciais do artigo de Etienne Lopes. Para não […]