
This sentence gets repeated a lot. You know the one: “Functions prevent the use of indexes.” Well, knowing you, it’s probably just your indexes. I’ve seen your indexes.
Functions can use indexes, but even so, that doesn’t mean that they’re going to perform as well as queries without functions.
Which Indexes?
In the SUPERUSER database (yeah, I know, I’m cheating on Stack Overflow), all the tables have a PK/CX on an Id column, which is an Identity.
If I have a function in my WHERE clause, will SQL undo the clustered index and use the remaining heap?
|
1 2 3 4 5 6 7 8 |
SELECT COUNT(*) AS [fields&records] FROM dbo.Users AS u WHERE ISNULL(u.Age, 17) < 18; SELECT COUNT(*) AS [fields&records] FROM dbo.Users AS u WHERE u.Age IS NULL OR u.Age < 18; |
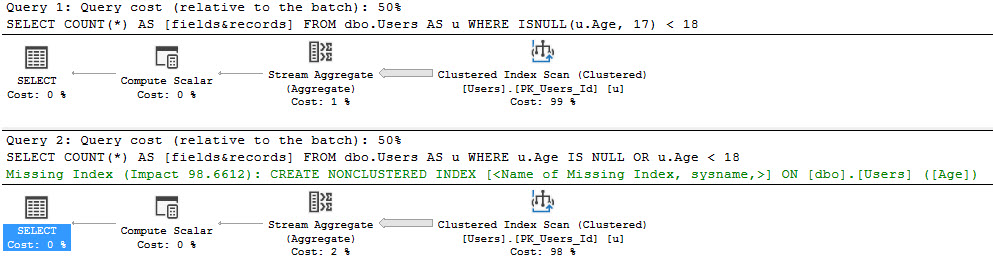
Okay, so functions will let us use the clustered index.
What about nonclustered indexes? Will they stop us from using those?
|
1 |
CREATE INDEX ix_yourmom ON dbo.Users (Age); |
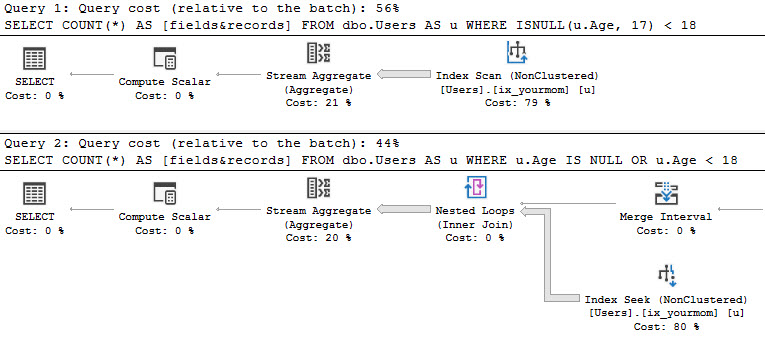
Now, that first query may not use the index as efficiently, but it still gets used.

In this case is doesn’t make a ton of difference, even. But you do have a seek vs a scan, which can make a bigger difference on bigger data sets.
“Prevents the use of”
So when would it look like a function prevented the use of an index? Well, maybe we can write a query that makes it look that way.
What if we change our query a little bit to look at a range of Ids — remember that Id is the PK/CX, so it’s implicitly present in all of the nonclustered indexes.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT COUNT(*) AS [fields&records] FROM dbo.Users AS u WHERE ISNULL(u.Age, 17) < 18 AND u.Id > 0 AND u.Id < 50000; SELECT COUNT(*) AS [fields&records] FROM dbo.Users AS u WHERE (u.Age IS NULL OR u.Age < 18) AND u.Id > 0 AND u.Id < 50000; |
Does that change anything?

Our query plan changed.
- In the first one, we’re scanning the clustered index.
- In the second one, we still use the nonclustered index
They pulled the ol’ natty switcheroo on us!
The clustered index seek plan went right to the range of Ids we wanted, then applied a residual predicate on ISNULL/Age.

The nonclustered index seek plan grabs the rows for all the Ages we care about, and then applies a residual predicate on Ids.

Much Confusion
If I were just getting started with SQL, I might think that using functions will prevent the use of indexes.
Is that right? No, but there is some value in being wrong here.
You should avoid using functions — scalar and multi-statement table valued UDFs generally (for now), and system functions meant for formatting in relational ways.
Think functions like LOWER/UPPER, RTRIM/LTRIM, DATEPART (and corresponding YEAR/MONTH/DAY functions), SUBSTRING, CHARINDEX/PATINDEX, LEN/DATALENGTH.
It’s not a good practice — you should be writing queries in ways that look for data the way it’s stored.
If it’s not stored the way you need to query it, then you may need to look at things like computed columns, or #temp tables where you can make transformations.
Thanks for reading!

16 Comments. Leave new
Nice article but I have seen the exact opposite happen many times, typically with more complex queries that handling a null by using an OR actually used a clustered index and using an ISNULL did not. Could be other factors but just wanted to mention that this should be taken with a grain of salt
Joseph — is your position that using functions in where clauses promotes better index usage? I have a giant grain of salt for you, too.
Sorry should have been more clear. My position is that I have not seen the same results that you have in your above example. My experience has been that using any type of function in a where clause the majority of the time does not promote better index usage. Especially in more complex queries and for indexes that contain multiple columns. I used to handle NULLS regularly using an ISNULL in the where clause and saw that it was not using the indexes setup. I changed the approach to use an OR instead and it improved the usage of indexes. Maybe I just read your article too fast but it reads as if you are promoting the use of functions and those following could cause them some pain.
I will end this comment with saying that I do really appreciate all the blog posts you write and they have helped me immensely.
No, I’m saying the same thing. Read the last section carefully.
Thanks!
..you should be writing queries in ways that look for data the way it’s stored. If it’s not stored the way you need to query it…
Beautiful!
Eric,
I cry for clean data.
Darrell — yeah, someday…
I’m newer to SQL, but reviewing some of my co-workers scripts, I see WHERE clauses like:
WHERE [backup_finish_date] < DATEADD(HOUR,-48,GETDATE())
Is this in the same scope as what you're talking about in this post? I'm under the impression it's not because the function is not on the column, but as I mentioned, I'm quite new to SQL.
Kyle — no, that’s fine. The problem would be is they did something like WHERE DATEDIFF(HOUR, backup_finish_date, GETDATE()) >= 48. Wrapping columns in functions is the bad idea.
If Erik doesn’t mind (or if he does), I’m going to expand on his last sentence “Wrapping columns in functions is the bad idea”, because it was something that really just clicked for me a few years ago.
If SQL doesn’t know the answer to the Function(Column) combination, it has to run each row through the function before it can know if it matches the other side of the comparison. This means it’s going to be scanning rows instead of seeking. There are some functions that are sargable, but there aren’t a whole lot.
One other way to demonstrate this is with simple math… The following queries return the same results, but show how it’s not just function, but even simple math on a column will cause the engine to perform a scan of the index or table even if there was an available index it could seek on. The second query can seek the available index.
SELECT Name FROM Domains WHERE (Group-1) = @GroupCount –Scan
SELECT Name FROM Domains WHERE Group = @GroupCount+1 –Seek
Good luck with your SQL experience!
Joe — yeah, spot on. I’ve heard that there’s some difference between “order preserving” functions, and those that would disrupt the natural order of an index, but haven’t seen any evidence of it.
Hands up, i’ve done this in the past.
Everyone has. Microsoft (and other database vendors) have put out scores of presentation-layer functions with little to no warning about what they do when used in parts of the query that are relational.
For a few decades I’ve been telling people that data ought to be represented “one way, one time, one place”, but frankly, I like your “store it the way you use it, use it the way it’s stored” better. Cleaner and easier to remember exclamation
Hahaha, appreciate it, Joe. I just hope it catches on eventually.
Nice post as usual, especially because of the scientific “test your assumptions in *real* code” process.
I’m weirded out by one tiny part: ” will SQL undo the clustered index and use the remaining heap?”
I think this falls into the misconception that “a table *HAS* a clustered index”, instead of the truth of “a table *IS* a clustered index”.
A table can either *BE* a clustered index, or *BE* a heap. (“Heap, or heap not. There is no TRY.”)
I know it’s a tiny change in people’s conceptual model of tables and indexes, but that 1 word has tripped up many a novice DB person (myself included).
P.S. Good course for people looking to get a good conceptual model of Heaps and Clustered Indexes (aka. Tables yo!): https://www.brentozar.com/training/think-like-sql-server-engine/ [\plug]
bit of a necro but wanted to bump and say that’s a great point, as I was reading the initial bit and I wasn’t sure if I was understanding. Def an important concept to understand what a “clustered index” really is.