
Size Matters?
One thing I hear a lot is that the optimizer will take the size of an index into account when choosing which one to use.
The tl;dr here is that it may make more of a difference when it comes to index width (think the number of columns in an index) than it does the actual size in MB or GB of the index.
You can usually observe this behavior with COUNT(*) queries.
If you have a table with a clustered index, and then a narrow(er) nonclustered index, it’s generally more efficient to just get a universal count from the nonclustered index because it’s less work to read.
This will likely change if you COUNT(a column not in the nonclustered index), but hey.
A column in the index is worth two key lookups.
Or something.
Queen Size
Let’s skip a lot of the nonsense! For once.
If I create a modest table with 1 million rows and a couple indexes with the key columns flipped, I can get a good starting test.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DROP TABLE IF EXISTS dbo.SizeQueen CREATE TABLE dbo.SizeQueen ( id INT IDENTITY PRIMARY KEY CLUSTERED, order_date DATETIME NOT NULL, inefficiency DATETIME NOT NULL, INDEX ix_use_me NONCLUSTERED (order_date, inefficiency), INDEX ix_do_not_use_me NONCLUSTERED (inefficiency, order_date) ); INSERT dbo.SizeQueen ( order_date, inefficiency ) SELECT TOP 1000000 x.n, x.n + 1 FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY @@DBTS ) AS n FROM sys.messages AS m CROSS JOIN sys.messages AS m2 ) AS x; |
I’m only going to be running two queries. One that does a direct equality, and one that looks for a hundred year range.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SET STATISTICS TIME, IO ON --Equality SELECT COUNT(*) AS records FROM dbo.SizeQueen AS sq WHERE sq.order_date = '1980-11-04' --Year range SELECT COUNT(*) AS records FROM dbo.SizeQueen AS sq WHERE sq.order_date >= '1980-11-04' AND sq.order_date < DATEADD(YEAR, 100, '1980-11-04') |
To spice things up, we’ll fragment the index in a way that may eventually cause problems: we’ll add a bunch of empty space.
We’ll do this with the magic of fill factor.
|
1 2 3 4 5 6 7 8 9 |
ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 90) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 80) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 70) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 60) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 50) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 40) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 30) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 20) ALTER INDEX ix_use_me ON dbo.SizeQueen REBUILD WITH (FILLFACTOR = 10) |
Pay careful attention here: we’re adding 10% free space to every page in the index incrementally.
We’re doing this to the index that has order_date as the first column, which is also the column that both of our queries are predicated on.
That makes this index the more efficient choice. The other nonclustered index on this table has order_date second, which means we’d essentially have to read every page — the pages with the date range we’re looking for aren’t guaranteed to all be together in order.
Technically they are, but the optimizer doesn’t know that.
The way data is loaded, dates in the ‘inefficiency’ column are only one day ahead of dates in the order_date column.
|
1 2 3 4 5 6 7 |
SELECT TOP 10 * FROM dbo.SizeQueen AS sq ORDER BY sq.order_date SELECT TOP 10 * FROM dbo.SizeQueen AS sq ORDER BY sq.inefficiency |
Ocean Motion
So what happens when we lower fill factor and run the equality query?
- The nonclustered index with order_date first always gets picked. Even when I set fill factor to 1, meaning 99% of the page is empty.
- The query never really does any more work, either. Every run takes 3ms, and does between 3-5 logical reads.
The range query is a bit more interesting. By more interesting, I mean that something finally changed.
But I had to drop fill factor down to 2% before the optimizer picked the other index.
Wanna see why?
Tag Team
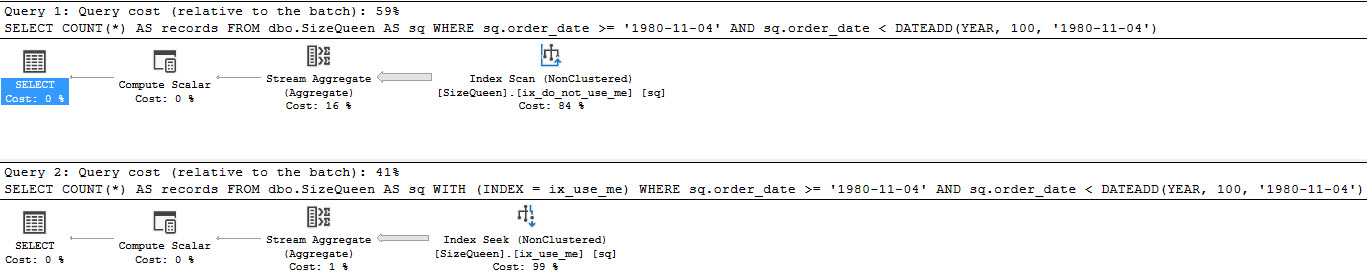
The first one chooses the less efficient index, with order_date second.
The second query is forced to use the other index where order_date is first, but where fill factor is set to 2%.
|
1 2 3 4 5 6 7 8 9 10 11 |
--Query 1 SELECT COUNT(*) AS records FROM dbo.SizeQueen AS sq --This uses the other index on its own WHERE sq.order_date >= '1980-11-04' AND sq.order_date < DATEADD(YEAR, 100, '1980-11-04') --Query 2 SELECT COUNT(*) AS records FROM dbo.SizeQueen AS sq WITH (INDEX = ix_use_me) --Index forced WHERE sq.order_date >= '1980-11-04' AND sq.order_date < DATEADD(YEAR, 100, '1980-11-04') |
With the less efficient index at 100% fill factor, meaning every single page is full of data, here’s what we get from stats time and IO.
|
1 2 3 4 |
Table 'SizeQueen'. Scan count 1, logical reads 4990, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 93 ms, elapsed time = 94 ms. |
About 5000 reads, and about 100ms of CPU time.
The forced index query gives us this:
|
1 2 3 4 |
Table 'SizeQueen'. Scan count 1, logical reads 5259, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 6 ms. |
So, about 270 more logical reads, but no CPU time.
Huh.
No, not that
I don’t care much about the batch cost here, or 100ms of CPU time. That’s trivial in nearly every scenario outside of, like, anime gif rendering, where every nonsecond counts.
I’m looking at those reads.
It took the ‘good’ index being 98% free space for the number of reads to surpass a 100% full index with the key columns switched.
Now, 5000 reads isn’t much. If we do 5000 reads every million rows, and our table gets up to 100 million rows, we’ll do 500,000 reads.
If we have the wrong index.
With the right indexes in place, fragmentation becomes much less of a concern.
Thanks for reading!

3 Comments. Leave new
I think you missed your own point since this query will of cource not use the other index. Why should the optimizer be so silly that it choose the index with the wrong field as the first one?
Both queries will use ix_use_me and then I don´t see the purpose of this exercise?
SELECT COUNT(*) AS records
FROM dbo.SizeQueen AS sq –This uses the other index on its own
WHERE sq.order_date >= ‘1980-11-04’
AND sq.order_date < DATEADD(YEAR, 100, '1980-11-04')
Go ahead and give the code a closer read.
Bjarne Petterson, I think you need to execute the fill factor to 2% at the index ix_use_me, and than execute the query that looks for a hundred year range.
And you will se that de change of the optimizer….
The fellas, just don’t put the script that change the fill factor.
Abraços!