
You read a lot of advice that says you shouldn’t shrink databases, but…why?
To demonstrate, I’m going to:
- Create a database
- Create a ~1GB table with 5M rows in it
- Put a clustered index on it, and check its fragmentation
- Look at my database’s empty space
- Shrink the database to get rid of the empty space
- And then see what happens next.
Here’s steps 1-3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE DATABASE WorldOfHurt; GO USE WorldOfHurt; GO ALTER DATABASE [WorldOfHurt] SET RECOVERY SIMPLE WITH NO_WAIT GO /* Create a ~1GB table with 5 million rows */ SELECT TOP 5000000 o.object_id, m.* INTO dbo.Messages FROM sys.messages m CROSS JOIN sys.all_objects o; GO CREATE UNIQUE CLUSTERED INDEX IX ON dbo.Messages(object_id, message_id, language_id); GO SELECT * FROM sys.dm_db_index_physical_stats (DB_ID(N'WorldOfHurt'), OBJECT_ID(N'dbo.Messages'), NULL, NULL , 'DETAILED'); GO |
And here’s the output – I’ve taken the liberty of rearranging the output columns a little to make the screenshot easier to read on the web:

We have 0.01% fragmentation, and 99.7% of each 8KB page is packed in solid with data. That’s great! When we scan this table, the pages will be in order, and chock full of tasty data, making for a quick scan.
Now, how much empty space do we have?
Let’s use this DBA.StackExchange.com query to check database empty space:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE [database name] GO SELECT [TYPE] = A.TYPE_DESC ,[FILE_Name] = A.name ,[FILEGROUP_NAME] = fg.name ,[File_Location] = A.PHYSICAL_NAME ,[FILESIZE_MB] = CONVERT(DECIMAL(10,2),A.SIZE/128.0) ,[USEDSPACE_MB] = CONVERT(DECIMAL(10,2),A.SIZE/128.0 - ((SIZE/128.0) - CAST(FILEPROPERTY(A.NAME, 'SPACEUSED') AS INT)/128.0)) ,[FREESPACE_MB] = CONVERT(DECIMAL(10,2),A.SIZE/128.0 - CAST(FILEPROPERTY(A.NAME, 'SPACEUSED') AS INT)/128.0) ,[FREESPACE_%] = CONVERT(DECIMAL(10,2),((A.SIZE/128.0 - CAST(FILEPROPERTY(A.NAME, 'SPACEUSED') AS INT)/128.0)/(A.SIZE/128.0))*100) ,[AutoGrow] = 'By ' + CASE is_percent_growth WHEN 0 THEN CAST(growth/128 AS VARCHAR(10)) + ' MB -' WHEN 1 THEN CAST(growth AS VARCHAR(10)) + '% -' ELSE '' END + CASE max_size WHEN 0 THEN 'DISABLED' WHEN -1 THEN ' Unrestricted' ELSE ' Restricted to ' + CAST(max_size/(128*1024) AS VARCHAR(10)) + ' GB' END + CASE is_percent_growth WHEN 1 THEN ' [autogrowth by percent, BAD setting!]' ELSE '' END FROM sys.database_files A LEFT JOIN sys.filegroups fg ON A.data_space_id = fg.data_space_id order by A.TYPE desc, A.NAME; |
The results:

Well, that’s not good! Our 2,504MB data file has 1,277MB of free space in it, so it’s 51% empty! So let’s say we want to reclaim that space by shrinking the data file back down:
Let’s use DBCC SHRINKDATABASE to reclaim the empty space.
Run this command:
|
1 |
DBCC SHRINKDATABASE(WorldOfHurt, 1); |
And it’ll reorganize the pages in the WorldOfHurt to leave just 1% free space. (You could even go with 0% if you want.) Then rerun the above free-space query again to see how the shrink worked:

Woohoo! The data file is now down to 1,239MB, and only has 0.98% free space left. The log file is down to 24MB, too. All wine and roses, right?
But now check fragmentation.
Using the same query from earlier:
|
1 2 |
SELECT * FROM sys.dm_db_index_physical_stats (DB_ID(N'WorldOfHurt'), OBJECT_ID(N'dbo.Messages'), NULL, NULL , 'DETAILED'); |
And the results:

Suddenly, we have a new problem: our table is 98% fragmented. To do its work, SHRINKDATABASE goes to the end of the file, picks up pages there, and moves them to the first open available spaces in our data file. Remember how our object used to be perfectly in order? Well, now it’s in reverse order because SQL Server took the stuff at the end and put it at the beginning.
So what do you do to fix this? I’m going to hazard a guess that you have a nightly job set up to reorganize or rebuild indexes when they get heavily fragmented. In this case, with 98% fragmentation, I bet you’re going to want to rebuild that index.
Guess what happens when you rebuild the index?
SQL Server needs enough empty space in the database to build an entirely new copy of the index, so it’s going to:
- Grow the data file out
- Use that space to build the new copy of our index
- Drop the old copy of our index, leaving a bunch of unused space in the file
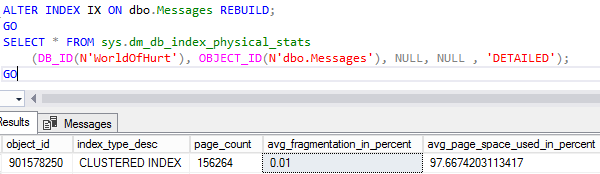
Let’s prove it – rebuild the index and check fragmentation:
|
1 2 3 4 5 |
ALTER INDEX IX ON dbo.Messages REBUILD; GO SELECT * FROM sys.dm_db_index_physical_stats (DB_ID(N'WorldOfHurt'), OBJECT_ID(N'dbo.Messages'), NULL, NULL , 'DETAILED'); GO |
Our index is now perfectly defragmented:
But we’re right back to having a bunch of free space in the database:

Shrinking databases and rebuilding indexes is a vicious cycle.
You have high fragmentation, so you rebuild your indexes.
Which leaves a lot of empty space around, so you shrink your database.
Which causes high fragmentation, so you rebuild your indexes, which grows the databases right back out and leaves empty space again, and the cycle keeps perpetuating itself.
Break the cycle. Stop doing things that cause performance problems rather than fixing ’em. If your databases have some empty space in ’em, that’s fine – SQL Server will probably need that space again for regular operations like index rebuilds.
If you still think you want to shrink a database, check out how to shrink a database in 4 easy steps.
Erik Says: Sure, you can tell your rebuild to sort in tempdb, but considering one of our most popular posts is about shrinking tempdb, you’re not doing much better in that department either.

59 Comments. Leave new
I completely agree that regularly shrinking databases (or to be more specific, data files) is a very bad thing. It is very resource intensive and it creates severe index fragmentation. We’ll leave aside your previous guidance that index fragmentation does matter at all and that all index maintenance is a counter-productive waste of time.
One valid reason to specifically shrink a data file would be if you had deleted a large amount of data that was not coming back any time soon (or ever) and/or you had dropped many unused large indexes, such that you had a quite large amount of free spaces in your data file(s).
If this were the case, and if you were low on disk space on the LUNs where the data file(s) were located (and you could not easily grow the LUNs), then I might want to go ahead and shrink the data file(s) with DBCC SHRINKFILE commands, as a one-time operation.
This would still be resource intensive, and would still cause severe index fragmentation, but I would have less concurrent impact to system than using DBCC SHRINKDATABASE (I would shrink the log file later, in a separate operation).
After the DBCC SHRINKFILE operations were done, I would use ALTER INDEX REORGANIZE to reduce the index fragmentation without growing the data file(s) again. Simply using REORGANIZE rather than REBUILD avoids the vicious circle of shrinking and growing that your demo illustrates.
ALTER INDEX IX ON dbo.Messages REORGANIZE;
Finally, if necessary, I would shrink the log file, and then explicitly grow it in relatively large chunks to my desired size, to keep the VLF count low.
So, I would never use DBCC SHRINKDATABASE. Instead, I would use DBCC SHRINKFILE only in special circumstances, and in a targeted manner, never as part of some automated, nightly process.
OK, great! Sounds like we’re on the same page.
GET IT
PAGE
IT’S A DATABASE JOKE
To what extent do you expect us to believe this?!
I fight this battle a lot – it’s PEBKAC for sure. At best it is a wasted operation and worst sets you back.
ok my last reply omitted the “please excuse my sarcasm and pun continuation”.
EXTENT! Oh, you are good.
Maybe your fill factor is set too high!
Hello Guys, nice answer, I had to shrink a 3 tb database and fragmentation was over 90 % in some indexes, basically the idea to avoid to grow the data file(s) again, the approach is to use Ola Hallengren procedure with these values for low, medium and high fragmentation : ‘INDEX_REORGANIZE’
Hi Glenn Berry,
Microsoft rerecords to rebuild indexes it the fragmentation is > 30% and reorganize those < 30% fragmented. Do you recommend to use reorganize instead rebuild in all cases?
Exactly. Never say never. My data drive was out of space because an application logging web api call responses was ringing and loaded 725M records of crap into a table. Truncating that table created 66% free space in my database. I want that space back! so, I’ll shrink the mdf even if it means rebuilding indexes afterward.
I am a fervent reader of your posts (as well as an avid viewer of your Office Hours, a regular user of sp_Blitz* and an accidental DBA who graduated with your free 6-months training program), so I guess it is time to thank you for all your contributions.
This post is a perfect example of your skills at demonstrating how SQL Server “thinks”. I can’t wait to reproduce these steps on my test environment.
A very Happy 2018 to the team!
Jean-Luc – you’re welcome, and glad you enjoy the work! We have a great time sharing this stuff. Enjoy, and happy 2018!
Hey 2018 Bret. Just heads up, 2020 is gonna suck. Buy some extra TP ? now.
*Brent
It is amazing to me, how many times I have been asked in interviews “How would you shrink a database” and my answer is ” I don’t know because I would never do it.” continue to explain why i would not shrink data files or databases. Then I hear crickets…
I got hired for saying I have shrink-rebuild indexes tasks as part of my maintenance plan. What I didn’t say is I have them disabled with a link to this article in the description.
Why did they build it that way?
At some point, someone at Microsoft said “let’s make it go to the end of the file, picks up pages there, and moves them to the first open available spaces in our data file.” And someone else thought it was a good idea.
Is (or was) there a case where DBCC SHRINKDATABASE is the right thing to do?
James – back in the day when disk space truly was expensive, shrinking was much more important. These days, I see people wildly focused on shrinking a 10GB database down to 8GB, and at the same time wildly focused on fragmentation – two issues that just won’t matter for performance on databases of that size – and then doing the cycle shown in the post.
If you have a 1TB database, and you truncate 500GB worth of tables that were supposed to be deleted daily, and you’ll never need that 500GB of free space, then sure, start shrinking that data file. (But like Glenn writes in his comment – only shrink the specific objects that require it.)
Given you stance on fragmentation in indexes doesn’t matter (I think that’s been your point recently on your blog), then the argument to not shrink files because of fragmentation is moot isn’t it? If the only downside of shrinking files is fragmentation, and fragmentation doesn’t matter, then I might as well shrink files right?
Is this something that you frequently see people doing?
Have a great new year
Greg – yep, I frequently see people doing it, and here’s the problem: you’re inflating your log backup sizes, data sent to the mirrors/AG replicas, slowing down file growths, and slowing down end user transactions while all this rebuild/shrink/rebuild/shrink cycle goes on.
This post was spurred by a client situation where yet again, they were doing this exact thing – all because they’d read a blog saying it was important to rebuild their indexes to fix fragmentation. Meanwhile, they were blowing their maintenance windows every night, doing this mindless shuffling into the morning hours, slowing down performance for their end users. The fix? Just…stop doing that. Presto, short maintenance windows and happier users instantly.
If you transfer your indexes into a new file, completely emptying out the original file, rebuild the indexes on the new file to pack things in nice and tight, shrink the original file and transfer the indexes back, then remove that now unused new file, you can accomplish both shrinking and reorganizing your data at the same time. It’s a huge pain and can take a while, but if you have a persistent size problem and limited space (we do on our testing space) it can help. Ultimately, better hardware is warranted, but we had a case where a database had a bunch of stuff removed from it, leaving a huge file that was significantly empty, and of course shrinking made things slower since it messed up the indexing.
This is what I wondered: The whole problem appears to be around the part where you defrag the index, and leave behind the blank space after the new, sorted index is in place. Why can’t we just use a different FILEGROUP for the indexes and this whole debate becomes moot?
So you’re going to add a new filegroup every time you defragment indexes? That’s … interesting.
What about if you reindex first, then shrink the files after? xD
[…] What’s So Bad About Shrinking Databases with DBCC SHRINKDATABASE? […]
Thanks for this post. I think I might add the URL to my email signature.
If you can’t avoid shrinking then DBCC SHRINKFILE with the TRUNCATEONLY option might be a good route. You want to keep all your files near the same size, too. Rebuilding the Indexes will help spread the wealth, too. Don’t forget about HEAPS. Clean that fragmentation up by either building cluster indexes or ALTER TABLE..REBUILD.
Reference: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-shrinkfile-transact-sql?view=sql-server-2017
“Releases all free space at the end of the file to the operating system but does not perform any page movement inside the file. The data file is shrunk only to the last allocated extent. target_size is ignored if specified with TRUNCATEONLY.”
So how does this apply to SQL Azure? We are pushing close to our paid for limit (250GB), but when we look at the space used by the data we’re only at 40GB…. This suggests that we should shrink otherwise we will need to pay more. Our SQL Server space is creeping up slowly, and then intermittently drops (I assume Azure is running some maintenance job) but that’s not happened for a while so we’re looking at forcing the issue.
Graham – for questions, your best bet is to head over to a Q&A site like https://Dba.stackexchange.com.
You claim something and when asked you link a forum where someone else is supposed to answer? Seriously?
I think the answer is simple: if money is the main problem screw the user experience – don’t care about possible slowdowns and just shrink the database.
Interesting – the company’s only concern is money, not performance? Might explain some of the staffing decisions they’ve made as well.
Or maybe not. It’s probably nothing. Have a good week!
I have a situation where we took a 1.1TB table with no clustered index, wrote it over to a new identical table, but has a PK, getting rid of unnecessary data that had been bloating the table, and was no longer being added. When it was all done, the new table is 1GB. I have deleted the old table. I now have 3.8TB available in a 4.1TB database. We have been doing a lot of cleanup of data, and don’t expect this to grow like that again any time soon. The used space is 288GB. I’ve only deleted the old files on a test copy of the DB. What is my best option to clear up this space if not using shrinkdb? I’m even fine with leaving 100% extra space to deal with the index rebuilds if that’s what is necessary, it will still be saving us 3.5TB of space. At this point, we’re more concerned with the time, as the shrinkdb hasn’t been finishing after days of running.
Aimee – the better option would have been creating a new filegroup during the move, but too late for that now – you’ll have to resort to shrinking. Next time you’re dealing with multi-terabyte objects, though, you can plan a little better for that ahead of time.
I hope I don’t have to do this again any time soon, but the pain of shrinking this database will probably have me looking for alternatives next time. Thanks for confirming my thoughts after reading this and some other articles on shrinkfile.
So imagine there is a database file 2Tb in size, 90% free space and want to set up a replica in a remote datacenter.
Does it make sense to do the shrinking BEFORE setting up a replication to reduce initial replication time from few hours to tens of minutes?
Johan – the answer would depend on:
Hope that helps!
Pre-allocating 2TB of empty file space on a disk for a DB that is “Someday going to grow” is not the best method. “Johan” has a point: Large files take time to process. Backup systems, VM Storage migrations, et cetera, from a systems perspective, all work best when files are small.
I sincerely hope that DBA’s out there are aware of the use of storage from a systems perspective, and always try to keep their db’s as small as possible.
Hey Brent,
Would dropping and recreating the index bypass the need for the data file to grow (as it does for rebuild index)? And if so, what is the downside to using drop-create index instead of rebuild index?
Aoabishop – if you have Standard Edition, creating an index takes the table offline. Even if you have Enterprise Edition, you can create the index (mostly) online, but while it’s happening, queries are doing table scans because there’s no old version of the index to use.
We need a way to be able to delete old SQL data and reduce the size of the overall storage. This is called reality and is needed over and over again. Here’s a scenario….you need to delete old SQL data that’s been unused for 10 years. Has Microsoft not figured out a way to do this with SQL?
Could care less about whatever mechanism is used, but please tell DBA’s that storage is finite. Since people are afraid to do cleanups we’re stuck with gobs of old data that have to be backed up endlessly.
Cleaning up data is good and reducing storage space is good as well.
Mike – allow me to rephrase: “developers need to keep up with deletes regularly rather than only doing it once every 10 years. Have developers not figured out a way to do this with T-SQL?”
When you phrase it that way, your request is kinda on shaky ground. 😉
Agree with Brent that it is the developer’s job as the DBAs would not always know the business logic required to purge or archive data. This is a missed requirement on so many applications. As a DBA I can let you know storage space is finite. I doubt any DBA would argue that point. Finite seems to occur between 10 PM – 4 AM.
Large databases have a negative downstream impact, too. Size of backups, space needed to restore to lower environments.
Brent,
As you know there are good reasons (e.g. old & outdated data) to nuke old data and shrink files. It just seems crazy that after all the great SQL improvements over the years, DBA’s can’t safely nuke old data and shrink the files.
MikeG – as you know, people who say “as you know” come off as condescending buttholes. May wanna step away from the keyboard for a while, get some fresh air.
Disappointing comment right here.
Heh funny thing is that I know that its unwise to do the shrink / grow cycle yet situations exist because oftentimes nobody else worries about these issues except for the DBA who has to free space, I don’t want to end up needing to do this, but I guess I too am a “butthole” for being in this position involuntarily.
I tell ya this industry is really the pits sometimes, but absolutely you can insult me too, its your webpage.
Wow. Given your comment and the number of methods suggested, I’d gather that no, Microsoft still hasn’t found an easy way to delete data and shrink data files.
And that is the issue. MS has yet to fix this huge giant problem.
What if you put all your indexes in a separate FILEGROUP? Then all these concerns about the whitespace left over after an index is defragged are nullified.
Have a look at partioning for removing old data perhaps. At the end of the day…. you need space somewhere at some time and frequent shrkinking is like beating your head against a wall.
I have only ever used DBCC Shrinkfiles to appease the Infrastructure Gods (in non production databases) But, I think I might have found a useful (meaning CYA) use for the command. Unless someone has a better idea of course. I need to migrate multiple TB of databases from our existing storage solution to GPT storage. The caveat being, no (perceivable) downtime. I’m fully aware of all the fragmentation issues this will produce, but we are proactive in correcting those. I’m also not sure the impact this would have on our AG databases. I suspect I would need to make all the same filegroup changes prior to executing any shrink commands. Thoughts?
For general Q&A, head to a Q&A site like https://dba.stackexchange.com.
This would be using the DBCC SHRINKFILE EMPTYFILE format, after adding a file on the GPT drive to the file group.
If shrinking is so bad why Microsoft has included the command? Kind of stupid in one way or another.
Because back in the 1990s, when your SQL Server only had 1GB of space, you actually did need to shrink the files, regardless of performance hits.
Given that shrinking databases and rebuilding indexes is a vicious cycle…
– Is there an optimum balance between the two that we humans can achieve by adjusting the parameters we feed to the above commands, AND do better than SQL Server itself does?
– Given that one can imagine a database with no unused space and no fragmentation, is it possible to prove (e.g. find an algorithm) either that this is achievable but not with current SQL Server tools, or is unachievable and SQL Server has it about right?
That’s an interesting thought exercise. If you have the time to work on it, by all means, go for it. The community would find those results interesting, and it’d be a great way for you to get into blogging or presenting.
Just to make sure I’m reading this right…
https://www.brentozar.com/archive/2017/12/whats-bad-shrinking-databases-dbcc-shrinkdatabase/
“We have 0.01% fragmentation, and 99.7% of each 8KB page is packed in solid with data.”
should that say 97.7% – if I’m reading the screenshot where it says – avg_page_space_used ?.
Hi. We have a prod Db that was storing a lot of documents in amongst other relevant data directly in the same table rows. We have since changed our model to storing the documents outside of sql.
After migrating the sql docs to the new storage solution, we have a significant amount of wasted space (approx 90% of the db.
The plan was to delete the columns holding the document data as they will never be used again, dbshrink and fullindex rebuild.
I carried out a dbshrink and full index rebuild, on our test server, and the Db has shrunk significantly. (<10% orig size)
However I am not a sql expert and am unsure if there are negative the repercussions of this.
I am happy with the results, on test but wanted verification of the proposed process on prod.
At this point I am unsure of the best way to proceed.
Your advice would be greatly appreciated. (Note that we also copy down prod data for testing scenarios and having a much smaller Db will be really useful).
TIA
Sure, for personalized advice on production systems, click Consulting at the top of the screen.
Hi
I want to help customer to stay on MS Express with size limit 10Gbs as he is already close to it.
I can delete some content “revision data” so I can get apx. 4GBs of data
When shrink with maximum space like 20% so I can finally get data size 5Gbs (apx.)
When I finally reindex nothing big happens maybe free % changed from 20% to 19%
Is there anything wrong with these steps ?
For personalized help with production systems, feel free to click Consulting at the top of the site.