
Microsoft’s Joe Sack & Pedro Lopes held a forward-looking session for performance tuners at the PASS Summit and dropped some awesome bombshells.
Pedro’s Big Deal: there’s a new CXPACKET wait in town: CXCONSUMER. In the past, when queries went parallel, we couldn’t differentiate harmless waits incurred by the consumer thread (coordinator, or teacher from my CXPACKET video) from painful waits incurred by the producers. Starting with SQL Server 2016 SP2 and 2017 CU3, we’ll have a new CXCONSUMER wait type to track the harmless ones. That means CXPACKET will really finally mean something.

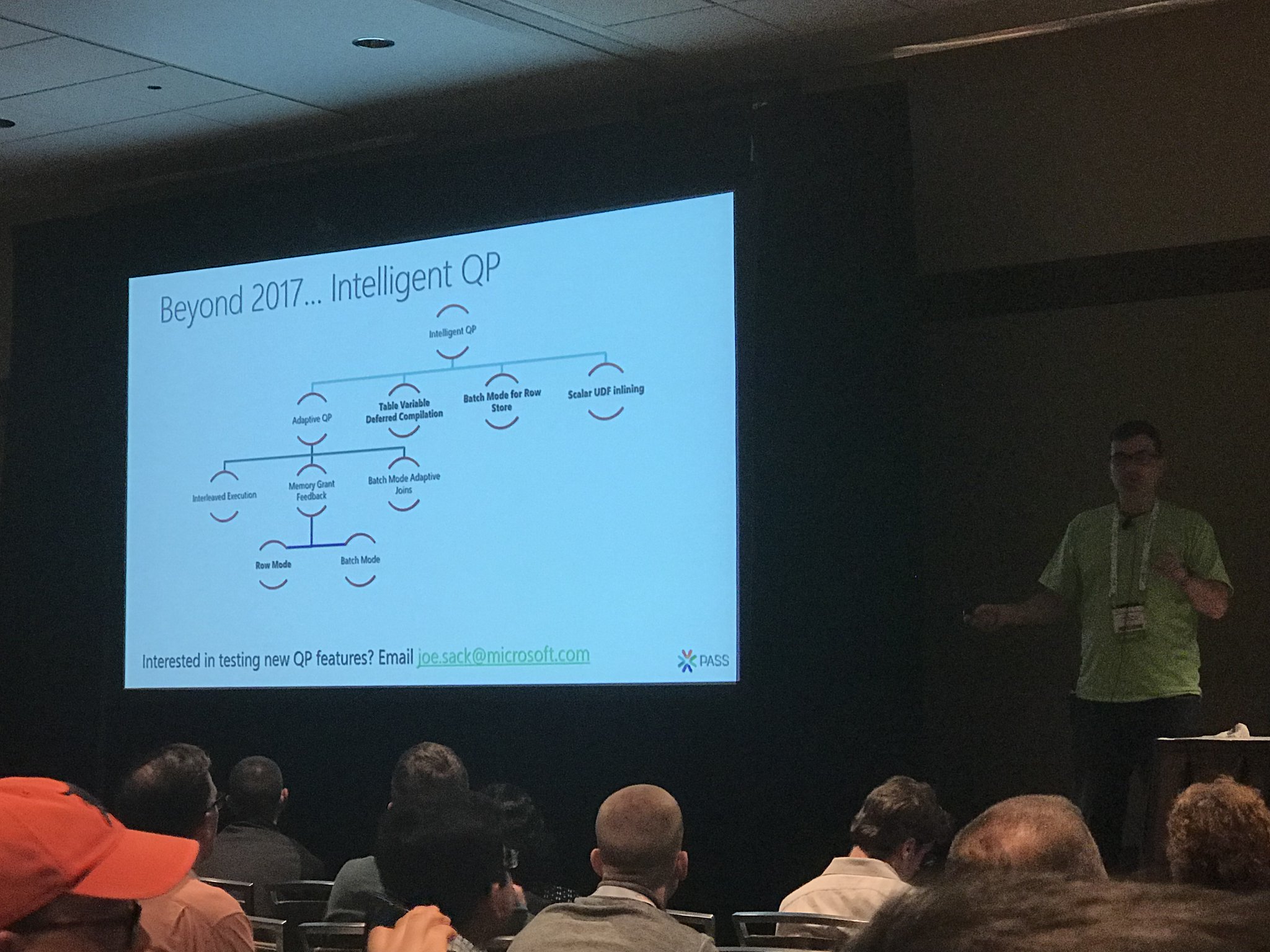
Joe’s Big Deal: the vNext query processor gets even better. Joe, Kevin Farlee, and friends are working on the following improvements:
- Table variable deferred compilation – so instead of getting crappy row estimates, they’ll get updated row estimates much like 2017’s interleaved execution of MSTVFs.
- Batch mode for row store – in 2017, to get batch mode execution, you have to play tricks like joining an empty columnstore table to your query. vNext will consider batch mode even if there’s no columnstore indexes involved.
- Scalar UDF inlining – so they’ll perform like inline table-valued functions, and won’t cause the calling queries to go single-threaded.
These are all fantastic news. If you’re in Seattle and you wanna learn more, Kevin Farlee will be doing a 20-minute demo at 1PM in the Microsoft Theater in the exhibit hall. See you there!

3 Comments. Leave new
>>Scalar UDF inlining
Consultants won’t be happy… customers will…..
All these all welcome changes…
Hey, even consultants love it because now there’s an easier fix: upgrade to future versions. (Before, with scalar functions, the answers all involved ugly rewrites that nobody wanted to do, but they’ll be much more interested in building a new server and running a repro workload to see the difference.)
Noooooooooooooooooooooooooooooo! I’ve spent the last seven years of my life refactoring queries to replace scalar functions with set-based code. Rather than look at empirical evidence (“Hey the query that used to run in minutes now runs in in milliseconds!”) the perpetrators of the scalar function-based queries would simply dismiss it by saying “you ask two different experts, you get two different opinions. I’ll stick with my procedural code thanks.” Now they’ll simply say “Hey, you know what? Looks like Muggins was wrong the whole time!”
I… just… can’t… even…
What next? NOLOCK hints without dirty reads?