
What happened in Part 1?
Join Elimination, naturally. Until the end. My copy of the Stack Overflow database doesn’t have a single foreign key in it, anywhere.
If we go down the rabbit hole a couple steps, we end up at a very quotable place, with Rob Farley.
2. Duplicated rows
Not necessarily duplicated completely, but certainly a row in our original table may appear multiple times in our result set, if it matches with multiple rows in the new table. Notice that this doesn’t occur if the join-fields (those used in the ON clause) in the new table are known to be unique (as is the case with a Foreign-Key lookup).
When we select a distinct list from one column, or create a unique index on one column, the optimizer knows that that one column is unique and won’t produce multiples of a value. I’m assured by mathematicians that even if you left join two distinct lists, it won’t produce duplicates.
With more than one column involved in a DISTINCT/GROUP BY, there may be duplicates of a single value, which would change our results. There’s a little more information about this over here as well.
How does that apply to us?
The results are going to be every DisplayName in the Users table, but the way our left joins are written to DISTINCT/GROUP BY the list of Ids that each produces, we know that each would only occur once.
That isn’t true in the last join, where we messed with columns. That join may produce multiples of some Ids with the multi-column distinct, which means the join can’t safely be eliminated. You could end up needing to show some DisplayNames more than once, in other words.
Similarly
If I re-create all my joins by dumping them into temp tables, we get a similar effect. A difference I want to point out is that I’m not joining other temp tables to each other, like in the first query. That’s why the “big” plan only has two joins. The multi-column-duplicate DISTINCT changed things up the whole tree of joins. Funny, right? Hysterical.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
SELECT p.OwnerUserId, COUNT_BIG(*) AS Records INTO #pp FROM dbo.Posts AS p LEFT JOIN dbo.PostTypes AS pt ON p.Id = pt.Id AND pt.Id = 2 WHERE p.Score >= 10 GROUP BY p.OwnerUserId HAVING COUNT_BIG(*) >= 10; CREATE UNIQUE CLUSTERED INDEX cx_pp ON #pp (OwnerUserId) SELECT p2.OwnerUserId, COUNT_BIG(*) AS Records INTO #pl FROM dbo.Posts AS p2 JOIN dbo.PostLinks AS pl2 ON p2.Id = pl2.PostId AND pl2.LinkTypeId = 1 WHERE pl2.CreationDate >= '2016-01-01' GROUP BY p2.OwnerUserId HAVING COUNT_BIG(*) >= 2; CREATE UNIQUE CLUSTERED INDEX cx_pl ON #pl (OwnerUserId) SELECT DISTINCT p3.OwnerUserId INTO #pv FROM dbo.Votes AS v JOIN dbo.VoteTypes AS vt ON v.VoteTypeId = vt.Id AND vt.Id = 2 JOIN dbo.Posts AS p3 ON p3.Id = v.PostId; CREATE UNIQUE CLUSTERED INDEX cx_pv ON #pv (OwnerUserId) SELECT DISTINCT c.UserId, c.PostId INTO #cc FROM dbo.Comments AS c JOIN dbo.Users AS u2 ON c.UserId = u2.Id JOIN dbo.Posts AS p4 ON c.PostId = p4.Id WHERE c.CreationDate >= '2016-01-01' AND c.Score >= 1; CREATE UNIQUE CLUSTERED INDEX cx_cc ON #cc (UserId, PostId) /*Two On One*/ SELECT DISTINCT c.UserId INTO #cc2 FROM dbo.Comments AS c JOIN dbo.Users AS u2 ON c.UserId = u2.Id JOIN dbo.Posts AS p4 ON c.PostId = p4.Id WHERE c.CreationDate >= '2016-01-01' AND c.Score >= 1; CREATE UNIQUE CLUSTERED INDEX cx_cc2 ON #cc2 (UserId) /*One On Two*/ |
Here’s what happens.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @DisplayName NVARCHAR(40) SELECT @DisplayName = u.DisplayName FROM dbo.Users AS u LEFT JOIN #pp ON #pp.OwnerUserId = u.Id LEFT JOIN #pl ON #pl.OwnerUserId = u.Id LEFT JOIN #pv ON #pv.OwnerUserId = u.Id LEFT JOIN #cc /*Two Column*/ ON #cc.UserId = u.Id; GO DECLARE @DisplayName NVARCHAR(40) SELECT @DisplayName = u.DisplayName FROM dbo.Users AS u LEFT JOIN #pp ON #pp.OwnerUserId = u.Id LEFT JOIN #pl ON #pl.OwnerUserId = u.Id LEFT JOIN #pv ON #pv.OwnerUserId = u.Id LEFT JOIN #cc2 /*One Column*/ ON #cc2.UserId = u.Id; GO |

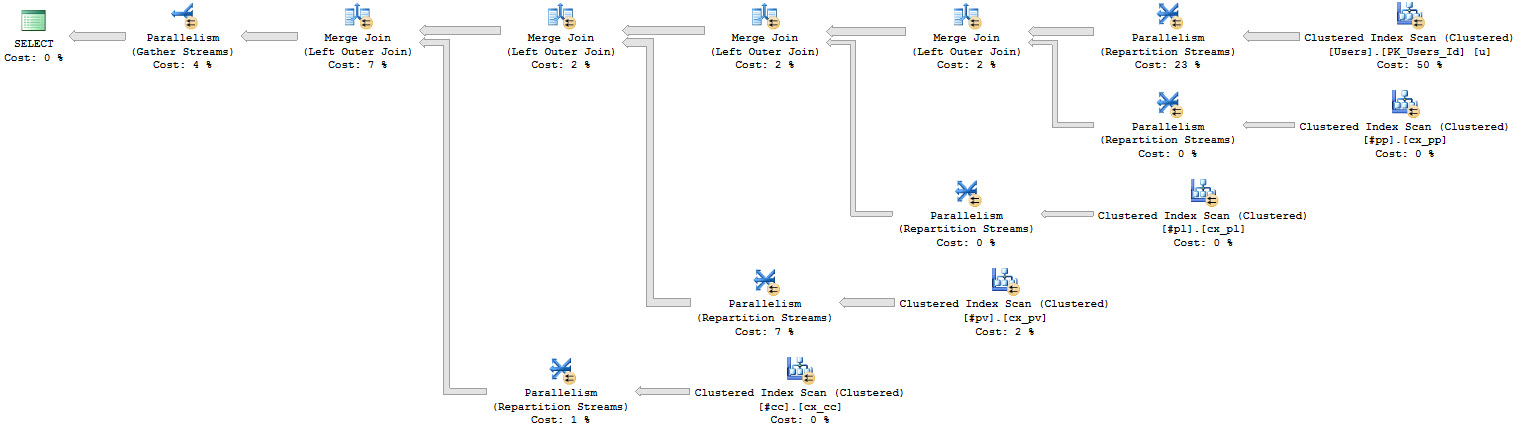
If I go back and add in the joins, the plan changes again. The duplicate producing join has a domino effect on the other joins — now they can’t be safely eliminated.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE @DisplayName NVARCHAR(40) SELECT @DisplayName = u.DisplayName FROM dbo.Users AS u LEFT JOIN #pp ON #pp.OwnerUserId = u.Id LEFT JOIN #pl ON #pl.OwnerUserId = u.Id AND #pl.OwnerUserId = #pp.OwnerUserId LEFT JOIN #pv ON #pv.OwnerUserId = u.Id AND #pv.OwnerUserId = #pl.OwnerUserId LEFT JOIN #cc ON #cc.UserId = u.Id AND #cc.UserId = #pv.OwnerUserId; GO |
Want a simple example?
If you’d like something a bit easier to follow along with, use this example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE TABLE #Example1 (Id INT NOT NULL, DanglingParticiple INT NOT NULL, PRIMARY KEY CLUSTERED (Id)) CREATE TABLE #Example2 (Id INT NOT NULL, DanglingParticiple INT NOT NULL, PRIMARY KEY CLUSTERED (Id)) CREATE TABLE #Example3 (Id INT NOT NULL, DanglingParticiple INT NOT NULL, PRIMARY KEY CLUSTERED (Id, DanglingParticiple)) INSERT #Example1 (Id, DanglingParticiple ) VALUES ( 1, 1 ) INSERT #Example2 (Id, DanglingParticiple ) VALUES ( 1, 1 ) INSERT #Example3 (Id, DanglingParticiple ) VALUES ( 1, 1 ) SELECT e.* FROM #Example1 AS e LEFT JOIN #Example2 AS e2 ON e2.Id = e.Id SELECT e.* FROM #Example1 AS e LEFT JOIN #Example3 AS e3 ON e3.Id = e.Id |
Thanks for reading!

3 Comments. Leave new
Do you even link brah?
I think you may have taken too many scoops of preworkout and dun goofed the link to Part 1, because it goes to a 404. I bet if you were to update the link to https://www.brentozar.com/archive/2017/09/how-much-can-one-column-change-a-query-plan-part-1/ it would, you know, like, work.
I guess you gotta confuse the am I right babe? RIP
TOO SOON
TFW when your knee-slapping good pun on HTML and lifting gets stripped out by the thing.
Srs though, good post, for realsies. I love demoing how seemingly tiny changes can have a much larger impact than expected. Just the other day I was working with one of our guys and pointed out how swapping out a sub-optimal join for the correct one cut logical reads by 97 percent.