
I’ve been using the Stack Overflow public database for my performance tuning demos for a few years now, and I just keep finding more reasons to love it.
It’s got a few simple tables with a lot of data. The main ones are Users, Posts (questions & answers), Comments, Votes, and Badges, ranging from 1GB to 90GB (as of 2017/06). The database is small enough that you can work with it on a modern laptop, yet large enough that even simple queries can turn into performance problems. (I hate seeing AdventureWorks demos of “bad queries” that run in less than a second. That simply isn’t what you do for a living, so it’s useless for training.)
The data means something to data professionals and developers. After all, you’ve been using StackOverflow.com for years. It’s kinda fun to query for your own data while we’re doing demos.
The data has real-world data distribution for lots of data types. Take the Users table, for example. There’s datetimes, integers, short strings (DisplayName and Location), and long strings (AboutMe), all with real-world representative data. There’s even gotchas with Unicode, nulls, and data you can’t trust (like Age has some surprises.)
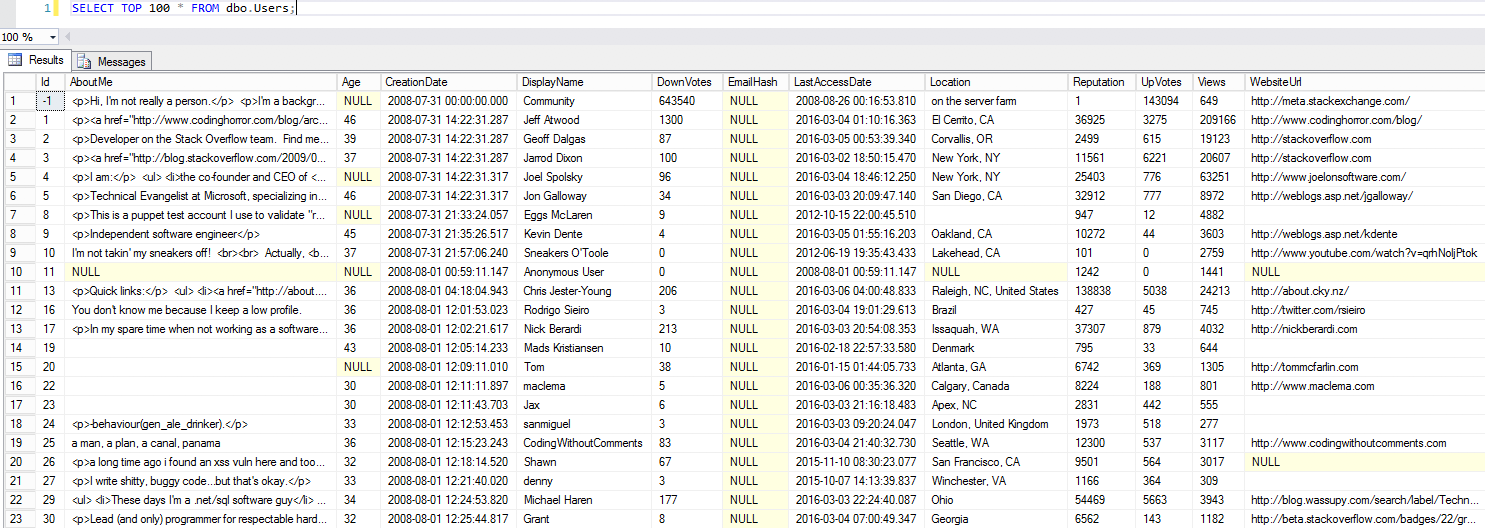
This is so much better than expanding small databases artificially, like scripts that try to expand AdventureWorks to a much larger size. This is real data with real data distributions – with plenty of opportunities for parameter sniffing examples.
The tables have easy-to-understand relationships. Every table has an identity Id key, and other tables can point to it. For example, in the Comments table:
- PostId links to Posts.Id, which is either a question or an answer
- UserId links to Users.Id, the person who posted the comment
The relationships even give you some fun for complexity: in the Posts table, the ParentId field links back to Posts.Id. See, both questions and answers are stored in the Posts table, so for answers, their ParentId links back to the question’s Posts.Id.
There’s a web front end. When I want to explain how the Users and Badges tables are related to each other, I can simply open my badges page on Stack, talk about how a user can earn badges, and earn them multiple times. I can walk the students through writing the exact query in SQL Server that will produce the results shown on the web page.
There’s a repository of sample queries. At Data.StackExchange.com, people have written thousands of queries against a recently restored copy of Stack Overflow’s databases. They’re real queries written by real people, which means they have real-world performance anti-patterns that are fun to unearth and tune.
It’s licensed under Creative Commons Attribution-ShareAlike. This means you’re allowed to share, copy, redistribute, remix, transform, and build upon the material for any purpose, even commercially as long as you give appropriate credit and share your work under the same license.
This means we can use it in our community training events – like our upcoming 24 Hours of PASS session, Last Season’s Performance Tuning Techniques. Register for it, go get the Stack Overflow database, and you’ll be able to follow along during our demos. We’ll be posting the scripts as a blog post here right at the start of the session. Let’s have some fun!

8 Comments. Leave new
I would add your “modern laptop” better have more storage than 256 GB. Ask me, I know. 😉
Why on earth would you have a column for Age and not “Date of Birth”?!
Because Date of Birth is personally identifiable information.
Aah, so they’ve sanitised the data a bit before releasing it? Fair enough.
And there was me thinking they had a scheduled job which increments the value of that column once a year!
Aside: the trademark guidance at https://stackexchange.com/legal/trademark-guidance says “The website domain name is always written stackoverflow.com (no CamelCase, single word capitalization rules apply)”
Alex – great, thanks!
Is there something like a “typical OLTP workload” for stackoverflow database? Or is there a way how to capture it? For example, having a web front-end available and capturing the SQL commands on the database.
Radim – not freely available to download, no. I’ve built one for my Performance Tuning By Example course if you’d like to join that, though.