
Brent had an idea that we should set aside a day per month where we could build things in the cloud and blog about our experiences. I was tasked with Amazon RDS for SQL Server: create an instance, configure backups and test point-in-time restores.
After grabbing some coffee, I logged into the AWS console. We use AWS EC2 instances for our lab environment, so we already had much of the environment created, such as networking and security. With those out of the way, I figured my task would be easy and quick. I would soon learn that the motto of the day was HURRY UP AND WAIT.
Creating a New RDS Instance
In the RDS Dashboard, I clicked the option to launch a new database instance and selected SQL Server Standard Edition.

As one of our goals was to see what our clients go through, I selected the production option.

Next I was presented with a bunch of fields and dropdowns.

I selected my options in the dropdowns and filled out the fields.
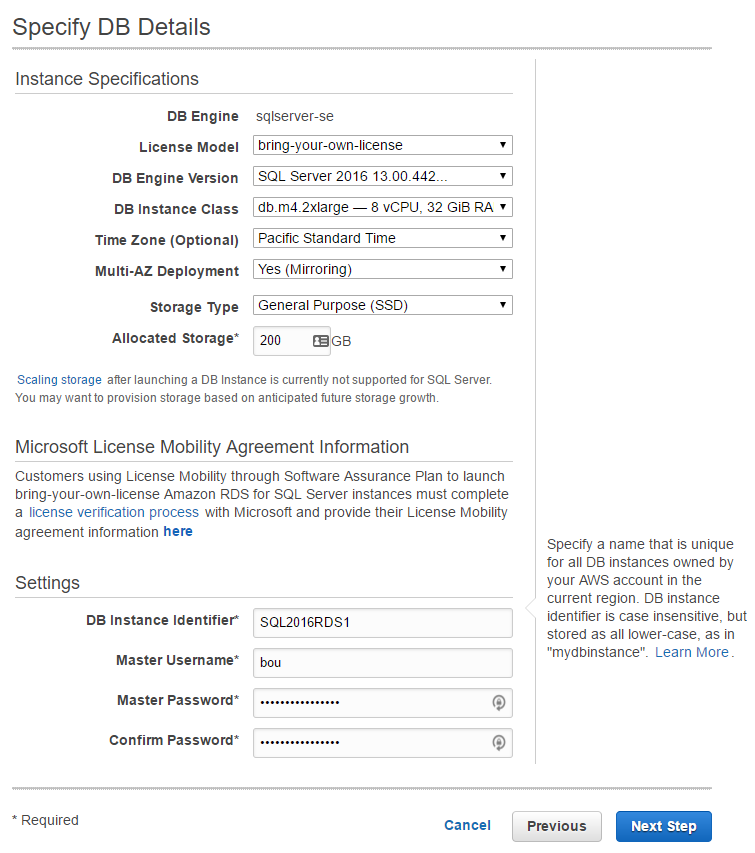
I was presented with the advanced setting configuration page.
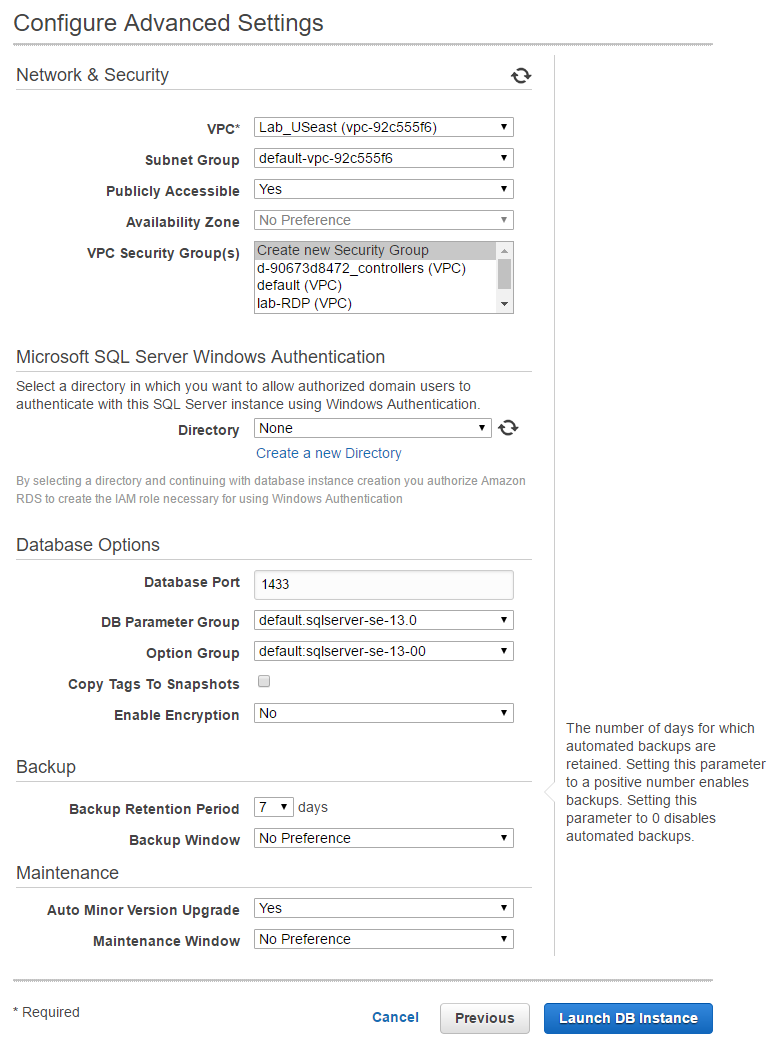
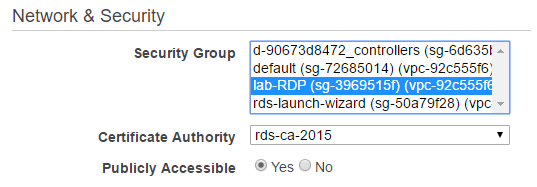
The only changes I made were to the VPC security group and the Windows Authentication directory.
It was now time to launch the instance.



It took about an hour before the instance was “available” and usable.
From a machine inside our AWS lab environment, I was able to connect to the RDS instance via SSMS.
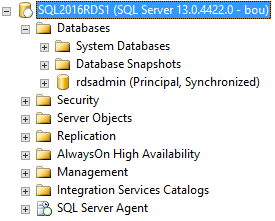
RDS adds an rdsadmin database. You’ll notice that it’s in a “Principal, Synchronized” state. RDS uses Synchronous Database Mirroring if you kept the “Multi-AZ Deployment” option at the default. This option gives you a standby option in another Availability Zone which makes the databases highly available. One thing to note about this that could be significant for your application is that Synchronous Database Mirroring could cause dramatic performance degradation. Except for one system that was low volume, I’ve only used synchronous when the other server was in the same data center. When using the multi-az configuration, the two servers are in different Availability Zones, meaning different data centers not close to each other. Be sure to test if your application is okay with the performance degradation of Synchronous Database Mirroring.
I knew backups weren’t “normal” in RDS, but I wanted to see what kind of errors I’d get if I tried to create Ola’s database maintenance stored procedures. I was not disappointed.
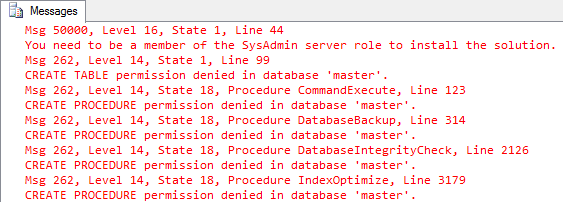
You don’t get sysadmin in RDS. You get processadmin and setupadmin.

Creating a Database and Putting Data In It
I created a database and copied some data into it from an EC2 instance that we have in the lab. I was kind of surprised that moving data from EC2 into RDS was so easy. I was expecting errors using the Import/Export wizard.

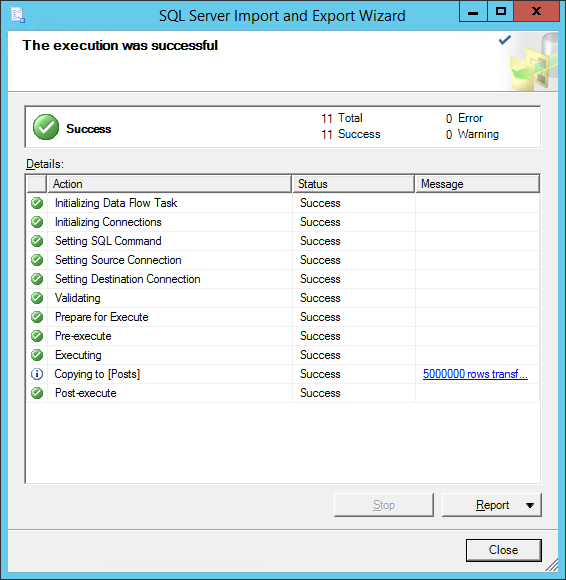
After getting some data into the database, it was time to do a point-in-time restore.
Restoring an RDS Database to a Point in Time
I picked 11am since that was after the instance had been created and before I had imported the data. Note that you must select a new instance name. If your connection strings are referring to the RDS instance, then you’ll need to change them to the new instance name if you ever do a point-in-time restore. Or use a DNS alias.

It took about 45 minutes for the point-in-time restore to complete.
After sql2016rds2 was “available”, I tried connecting to it.

I am very familiar with that error, so I tried a few things before throwing in the towel. Brent noticed that the security group wasn’t correct and said I needed to change that. It wasn’t one of the options when I did the point-in-time restore, so apparently this is an extra step you have to do. I modified the instance to use the correct security group.
(Brent says: in fairness, Amazon’s point-in-time restore documentation does say you have to manually change the database’s security group after the restore, but, uh, none of us read that until the next day. So there you go. We don’t read the manual either, dear reader.)

After it was finished being modified, which took just a few minutes, I tried to connect again and received the same connection error as before.
I then did a comparison between the two instances and saw a discrepancy. sql2016rd2 was missing the Directory information in the “Security and Network” section. I modified the instance again and added our directory.

That change took almost 30 minutes. I was finally able to connect to the instance!
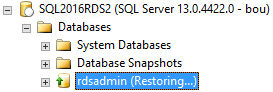
But the rdsadmin database was is in a restoring state, which prevented me from creating a database. Well shoot. I guess I had restored to a point that was too early.
Restoring, Take Two
I deleted sql2016rd2 and tried another restore, naming it sql2016rd2 again and this time selecting 11:45am for the restore time. The lab directory was already filled in, so I wondered what it looked like the first time I tried it. Unfortunately, I didn’t take a screenshot of it the first time around.

After the instance was created, I modified it to use our security group and then connected to the new instance. The two databases were in the proper state and ready for connections!

Summary
It has become quite clear to me that I am a tactile learner. I can’t just listen to someone present a topic, read a blog post or documentation. No matter how many times I’ve read about RDS, it just wasn’t sinking in. I’m no expert as a result of this experience, but at least I’ve touched RDS now, even if it was minimal work. Most of the time was spent waiting for things to become available. I now understand some of Richie’s frustrations with the cloud.
Brent says: In the cloud, your boss probably expects you to be able to do a point-in-time restore fairly quickly. Demos make it look like a simple wizard. Just try this kind of thing ahead of time so you can give realistic time estimates – I was totally surprised at the half hour it took for Amazon to modify a database’s security group, and we had nearly zero status messages along the way. During a business outage, that’d be a heck of a problem.

14 Comments. Leave new
Yeah, RDS has plenty of idiosyncrasies. You can use Ola’s scripts in RDS, but you’ll need to create a DBA database and run the scripts there. Of course, only Index Maintenance and DBCC will be of use to you, as RDS handles all the backups as part of its service.
At my last job, we had a system on Azure SQL. I was not the primary DBA on it, but occasionally had to work on it due to on-call reasons. It was weird not having the same permissions and troubleshooting the same as on regular servers. Every time I had to connect to it which wasn’t often, I had to look at the primary DBA’s notes in order to figure things out. “I have to do what?!”
My company decided to move to RDS & me being the only DBA had the responsibility to learn RDS at first and then implement with zero guidance. Only source was AWS documentation of over 1000 pages.
Studied and time for test environment. And remained stuck for 2 days with the same Point in Time Restore error, before I decided to read that section of document again to bail myself out. So, I big time agree with Tara that no matter how many times we read the document, few people like me just don’t get it unless we literally try it hands on.
How big was the database? It looks like the Stack database which has surely gotten bigger since I last played with it. Asking just to get an idea of restore time vs. database size.
So with RDS, the restore is at the instance level. So you have to factor in all of the databases together.
I used a 10GB database for this. I copied a subset of data from another server. I’m not clear if a bigger database would have been slower or not. In my mind, 10GB should not take an hour.
Oh, and I forgot to add, that the instance itself must be factored in. That is, the whole machine. Yes, there is an EC2 instance behind the scenes that RDS runs on top of.
That’s what I figured was the culprit of the long restore: the server size itself, not the database size. You can see in the screenshots that I used a 200GB disk.
My biggest issue with Point in Time restores in RDS is, as Steven points out, that it’s the entire instance. Say you have the maximum number of databases allowed for an RDS instance (which is 30, btw), and you only need to recover one. You have to recover the entire instance, backup the one database you need (backed up to S3 storage in my case), then restore it on the production RDS instance. Very time consuming if that instance is large. That’s probably the biggest issue for me, but there are others…
We tend to use seed databases to start with, configure them as needed, and roll them out into production. If you have two databases that came from the same seed database, you can only restore one of them to an RDS instance because they have the same file_guids (I’m talking native restores here from S3 storage). If you try, you will get a message that says “Database Starter_TEST1 cannot be restored because there is already an existing database with the same file_guids on the instance.” Some of the databases I plan on moving are fairly large, so scripting the db out is out of the question. So, my plan is to create a bacpac file of the databases I need to move, restore that bacpac file as a new database (which creates new file_guids), back it up, move it to S3 storage, then do a native restore into the RDS instance.
You can’t rename databases on a DB instance in a SQL Server Multi-AZ with Mirroring deployment. Doesn’t really affect me.
Amazon RDS doesn’t support some features of SQL Server (SSAS, SSIS, SSRS, Service Broker, and more).
Can’t change cost threshold for parallelism.
Can’t change max degree of parallelism.
I would love to see more AWS RDS posts from you!
Scott – yeah, RDS is the opposite approach to Azure SQL DB. If you *want* to restore several databases to the same transactional point in time, it’s easy with RDS, but more challenging with Azure SQL DB.
For config settings, check out parameter groups:
http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html
Tara, I was messing around with RDS about a year ago for a POC at work and stumbled across something I found useful as a DBA. Back in July of last year Amazon announced support for native SQL backup/restore by using two Amazon provided procs rds_backup_database and rds_restore_database. If you set this up and dropped an on-prem backup into an S3 bucket and then restored that to your RDS instance, you end up with extra permissions on your RDS instance for that database. From there I was able to perform regular T-SQL backups and subsequent restores to and from the default path, D:/backup if I recall correctly, with my new found permissions. I am not sure that this is still the case as they may have plugged the hole by now, but it might be something you want to try out on you next Builder Day and save yourself some HUAW time. Fortunately for me, I manage to take another job since then and that got me away from mucking around in the frustration of AWS, so I don’t know for certain if it still works. 🙂
John – HAHAHA that is awesome. Nice find.
Tried to do this a couple of different ways….I think they plugged it. But maybe I missed a trick.
@Scott – I know this is way after your comment, and not sure if RDS worked the same in 2017, but you can change the MAXDOP and cost threshold. You need to do this in a parameter group though, you can’t do it the traditional way.