
People often don’t give this thought
Which is a shame, because I see people sticking fairly large amount of data into temp tables. On the rare occurrence that I do see them indexed, it’s a nonclustered index on a column or two. The optimzer promptly ignores this index while you select 10 columns and join 10,000 rows to another temp table with another ignored nonclustered index on it.
Now, not every temp table needs a clustered index. I don’t even have a rule of thumb here, because it depends on so many things, like
- Are you joining it to other tables?
- What does the execution plan look like?
- Is this even part of the stored procedure that needs tuning?
Pretend That We’re Dem
Assuming that all three things lead us to index temp tables, let’s create some and see how they react to different indexing strategies.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SELECT TOP 100000 * INTO #TempUsers FROM dbo.Users AS u; SELECT TOP 100000 p.* INTO #TempPosts FROM dbo.Posts AS p JOIN #TempUsers AS tu ON p.OwnerUserId = tu.Id; SELECT TOP 100000 c.* INTO #TempComments FROM dbo.Comments AS c JOIN #TempUsers AS tu ON c.UserId = tu.Id JOIN #TempPosts AS tp ON c.PostId = tp.Id; SELECT * FROM #TempUsers AS tu JOIN #TempPosts AS tp ON tu.Id = tp.OwnerUserId JOIN #TempComments AS tc ON tc.UserId = tu.Id AND tc.PostId = tp.Id; |
We have three temp tables with 100k rows in them. I joined them a bit to make sure we get good correlation in the data.
If we get the plan for select statement, this is our query plan. A bunch of table scans and hash joins. SQL is lazy. I don’t blame it one bit.

After frequent user complaints and careful plan analysis, we decide to add some indexes. Let’s start with nonclustered indexes.
|
1 2 3 4 5 |
/*Nonclustered*/ CREATE NONCLUSTERED INDEX ix_tempusers ON #TempUsers (Id); CREATE NONCLUSTERED INDEX ix_tempposts ON #TempPosts (Id, OwnerUserId); CREATE NONCLUSTERED INDEX ix_tempposts2 ON #TempPosts (OwnerUserId, Id); CREATE NONCLUSTERED INDEX ix_tempcomments ON #TempComments (UserId, PostId); |
I’ve gone ahead and added two indexes to #TempPosts so the optimizer has a choice if joining in another order is more efficient.
How’d we do?

Not quite there. Two table scans and an index seek followed by a key lookup that SQL estimates will execute 62k times.
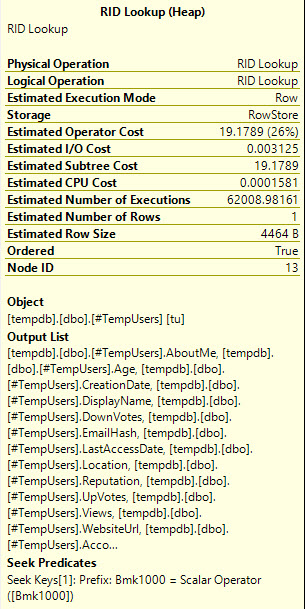
Do over
Let’s try that again with clustered indexes. We can only give #TempPosts one, so I picked at random. In real life, you might want to do your job!
|
1 2 3 4 |
/*Clustered*/ CREATE CLUSTERED INDEX cx_tempposts ON #TempPosts (Id, OwnerUserId); CREATE CLUSTERED INDEX cx_tempusers ON #TempUsers (Id); CREATE CLUSTERED INDEX cx_tempcomments ON #TempComments (UserId, PostId); |

Our indexes get used and everyone is happy. Well, sort of. TempDB isn’t happy, but then it never is. It’s like your liver, or Oscar the Grouch.
Used and abused
When starting to index temp tables, I usually start with a clustered index, and potentially add nonclustered indexes later if performance isn’t where I want it to be.
You can do yourself a lot of favors by only bringing columns into the temp table that you need. If it’s still a lot, there’s a much higher chance SQL will judge a table scan cheaper than using a narrow nonclustered index along with a lookup.
Remember to test this carefully. You want to make sure that adding the indexes doesn’t introduce more overhead than they alleviate, and that they actually make your query better.
Thanks for reading!

46 Comments. Leave new
Hehe, amazing timing, I just ran a session on the important of indexing temp tables, alongside how the tipping point of narrow non clustered indexes works with our developers. This has promptly been sent on!
Cool! It’s a great topic to educate people on.
A frequent (and interesting!) decision point for me: if I decide to create a clustered index on a temp table, do I create it before I run the query that populates it or after? There’s tradeoffs both ways:
– Create Before INSERT: if the query is complex, estimates are usually off by the time the insert operator is reached. Because the optimizer often puts a sort before the insert (to order by the clustering key to promote sequential IO), incorrect estimates can lead to a tempdb sort spill. On the old CE, where estimates usually are lower for complex queries, this happens a lot.
– Create after INSERT: estimates will be good, and if you’re on Enterprise Edition, the parallel index build can be awesome. But if you’re on Standard Edition, the index build is single-threaded whereas at least with the INSERT query the sort might be parallel.
I usually end up trying both ways to see which is faster and/or seems more robust for the long-term.
Or a third option: create the clustered index, insert, then update stats. @_@
I’m missing how that’s different from my “Create Before INSERT”, at least for perf of the initial insert. But yeah, sometimes updating stats or creating multi-column stats on the temp table afterwards has been really helpful for me.
I have found the clustered index create to be almost always much quicker when the #tmp is populated first, then add the index.
The are a couple of things to keep in mind.
1.all cluster indexes are unique, so adding the extra columns to make the index unique is a free action, if they are 8 bytes or less (the size of the uniqueafier, if I remember correctly), also telling sql server that some joins are 1:n, not potentially n:n cash change the plan.
2. You don’t have to index the way of the present table, It’s your temp and in this case you perfectly know the query pattern it is going to be use for.
3a. The query plan has a leading short on one of the tables, so the cluster index can precalculate that sort,
Or
3b,or note that user ID is common to both joins, and make that the leading column of the index
/*possibly better unique Clustered*/
CREATE unique CLUSTERED INDEX cx_tempposts ON #TempPosts ( OwnerUserId, Id );
CREATE unique CLUSTERED INDEX cx_tempusers ON #TempUsers (Id);
CREATE unique CLUSTERED INDEX cx_tempcomments ON #TempComments (UserId, PostId);
SELECT *
FROM #TempUsers AS tu
JOIN #TempPosts AS tp
ON tu.Id = tp.OwnerUserId
JOIN #TempComments AS tc
ON tc.UserId = tp.OwnerUserId — is the same tu.id due to inner join above
AND tc.PostId = tp.Id;
No, clustered indexes are only unique if you declare them as such, or if they’re created by default with the Primary Key.
Adding more columns isn’t by any means free. You’re ordering all data by extra columns, and clustered index key columns are implicitly present in all nonclustered indexes.
Hope this helps on your learning journey.
Thanks!
Erik, SQL Server must be able to use a clustered index seek to locate a single row. Therefore they are always either implicitly or explicitly unique. (my mistake was on the size of the uniquifier, it’s 4 bytes)
https://technet.microsoft.com/en-us/library/ms177484(v=sql.105).aspx
row locators in nonclustered index rows are…. Or a clustered index key for a row, as described in the following:
If the table is a heap, which means it does not have a clustered index, the row locator is a pointer to the row. The pointer is built from the file identifier (ID), page number, and number of the row on the page. The whole pointer is known as a Row ID (RID).
If the table has a clustered index, or the index is on an indexed view, the row locator is the clustered index key for the row. If the clustered index is not a unique index, SQL Server makes any duplicate keys unique by adding an internally generated value called a uniqueifier. This four-byte value is not visible to users. It is only added when required to make the clustered key unique for use in nonclustered indexes. SQL Server retrieves the data row by searching the clustered index using the clustered index key stored in the leaf row of the nonclustered index.
Yep. I’ve read that page before, too. Head over here for another blog post I wrote a while back about how defining an index as unique can help performance.
Good article, Erik. Thanks! If anyone is interested, you can create spatial indices on temp tables BUT you have to create a PK constraint/clustered first. So, this means the single clustered index you can use is burnt. But, if you’re doing spatial queries, it is worth it just be able to build a spatial index that is well-suited to your data. The sequence I found to work the best is:
(1) Create #table
(2) Insert rows into #table
(3) Create PK clustered index on #table
(4) Create spatial index on #table
(5) Update stats on #table
(6) Enjoy #table (!)
Cheers.
why step 5 (Update stats)? If you fill the table before creating the indexes, the statistics should be always up to date.
Thomas, temp tables in stored procedures can be quirky.
that blog link is broken, can you provide alternate link?
seems, that article is [here](https://www.sql.kiwi/2012/08/temporary-tables-in-stored-procedures.html)
Thanks Erik,
Though you did in passing mention TempDB – the poor forgotten but much relied upon Database….I would suggest to the readers that a review of the size of TempDB, it’s physical location, # of data files, applicable trace Flags (1117,1118) and Drive latency – even drive type (if you have that luxury) be carried out and tested. I have seen well crafted Temp Tables fall foul of not taking these into consideration.
Mal D
Lightbulb! I’m pretty sure this solves my sproc performance problem! I’ll try it tomorrow! Thank you!
One thing that bugs the absolute hell out of me about temp table indexing is that if you can’t create an index within the table creation statement for some reason then you have to name it as part of a separate index creation statement, and if you have to name it then you’re not gonna have a fun time if the same sproc is running concurrently with another instance of itself. Index names within TempDB are strangely immune to the uniquification that temp table names enjoy. I luckily work with ETL mainly where two instances of the same sproc running at once would be A Big Bad anyway, I’ve never had to (named)-index a temp table as part of heavy OLTP that would be likely to run into this issue, but I imagine that if I did I’d be forced to create the indices via dynamic SQL incorporating a GUID or such into the name.
I may be misremembering this but I’m fairly sure I’m not; this may also not be true for the latest greatest SQL Served release or update. Feel free to call BS.
Ooh, typo. SQL got Served!
Yeah, you’re thinking about constraints, not indexes.
Run this in two different query editor windows. The indexes are fine, but the alter table to add a PK fails in the second window.
The third chunk where the constraint is created inline doesn’t fail.
CREATE TABLE #t (c INT NOT NULL)CREATE CLUSTERED INDEX cx_t ON #t (c)
CREATE NONCLUSTERED INDEX ix_t ON #t (c)
DROP TABLE #t
CREATE TABLE #t (c INT NOT NULL)
ALTER TABLE #t ADD CONSTRAINT pk_t PRIMARY KEY CLUSTERED (c)
DROP TABLE #t
CREATE TABLE #t (c INT PRIMARY KEY CLUSTERED)
Aha! Excellent. I guess I’m in the habit of making a unique clustered index a PK if there’s no obvious reason not so I’ve just become caught in that trap. I noticed inline was fine, found myself unable to do so once, tried with a named constraint and assumed it would apply to named indexes too. I’m guessing the constraint ends up without a uniquified name and the corresponding clustered index gets the same treatment as if it were created inline. I’ll play around with that next week, thanks!
THANK YOU FOR MAKING THIS MAKE SENSE FINALLY.
I still can’t remember all of the allowed syntaxes for creating an index (and which ones allow you not to specify an index name) but now I know when I don’t need to care!
That’s okay. Remembering syntax is inefficient. Remember concepts, write down syntax. You’ll have a lot more room for concepts.
you can put a # before the index name too.
The following statements run fine in multiple sessions at the same time:
CREATE TABLE #tmp (id int)
CREATE CLUSTERED INDEX #tmp_idx ON #tmp (id)
Good thought… creating index on temporay table is nice thought. but we have to be very sure that it is being used properly.. temp tables are created at tempdb which is global for all databases in the server. so if our temp table is not proper or not handled propy ie uncommmited transactions , all databases on the server will be badly affected.
That’s what the post is all about!
Thanks!
Hi Erik,
Does this apply to CTEs and table variables also? Although using temp tables is much faster but I faced a problem once with using it in a stored procedure. It ran perfectly from SSMS but when using it as a data source in crystal report, I got an error “unknown error from server”. When I changed the temp table to CTE it ran perfectly. So, it would be good if we can use indexes with CTEs in order to solve slowness.
For the table variable question, I’d send you over here.
With CTEs, they don’t materialize, so you can’t index them. There’s a Connect item to fix that, but it just had its 10th birthday, so I wouldn’t count on it happening. Even if it does, there’s no guarantee you’d be able to add indexes to them.
Not materializing CTEs only bites you if you reference them multiple times. For these, I’d concentrate on indexing the base tables properly. If you can’t, you may need an indexed view of the CTE syntax, as long as it follows all the rules.
Another point regarding the discussion, if the index should be created before or after filling the #temp, when used inside a stored procedure:
SQL Server reuses #temp-tables in stored procedures, except there are other DML-Statements (CREATE INDEX, ALTER COLUMN, DROP TABLE) after the initial CREATE TABLE #temp (when the procedure ends it “disables” the #temptable in the tempdb and enables it again at the next procedure call).
This could be a big performance boost for procedures that are called very often (since a CREATE TABLE is slow) but has the drawback of some sort parameter sniffing (since the #temp table’s statistics are created at the first run).
So when you have a very often called stored procedure, which uses a #temp table with a comparable amount of rows at each run, it could be the fastest way, when you create the index inside the CREATE TABLE statement.
You should check out this article from Paul White, if you haven’t already seen it. There’s a little more to it than that.
Did you account for the overhead of creating the indices itself. Given these are temp tables I presume it’s something you would create and then throw away every time? As such the overhead of creating and indexing them should be counted as part of the cost of processing.
That is literally the last line of the blog post.
Thanks!
In 20 years of consulting on SQL Server I can probably count on one hand the number of times an index on a temp table has helped a client process. I cannot possibly count the number of times I have REMOVED indexes from temp tables and had the entire process be faster/more efficient. Creating an index is a SERIOUS amount of non-work, especially a clustered one. You need to have a REALLY good reason to do it to make up for that work.
Those must be some interesting indexes they’re creating.
Not really. A common one is to put an identity on the table and a primary key on that (clustered by default of course). Or perhaps they use a little bit of grey matter and decide to index some field that will be used for a join or a predicate. But in doing so you have to read the table entirely and then build the index – all taking time and resources. Then (almost) ALWAYS there is just ONE use of that temp table for a join and then it’s usefulness is done. That huge read-sort-write process (especially for clustered indexes) to create the index just wastes effort for no overall gain.
The two types of wins I have seen are:
1) A clustered index that allows the optimizer to use a merge join on a very large table. But guess what – the optimizer can and often does insert it’s own sort of the temp table to facilitate that same merge join.
2) LOTS of iterative hits on the same object by some changing field value. But MANY times I have seen that be a RBAR (Row By Agonizing Row) process that was actually able to be rolled up into a fully SET based operation and become orders of magnitude more efficient because of that.
Sorry, but I stand by my statement that indexes on temp tables are way more frequently a waste than a benefit. 😀
Weird, I’ve had many experiences exactly the opposite of that.
Especially when temp tables are being used to break up many table joins into a few smaller temp table joins. The intermediate tables are still some millions of rows (just the nature of the data), so appropriate clustered indexes definitely help things along.
Probably a good thing that people putting identity columns on temp tables got some professional help, either way.
I am curious what it was about those clustered indexes on millions of rows temp tables that “helped things along”. I also wonder if you benchmarked the entire process, including the work/time it took to create those clustered indexes. I know you are a sharp guy so you probably did and you thus have proof that it made the entire process faster.
But (almost) every single time I have refactored those and found that the developer actually DID do testing, they did it in SSMS in a script and all they benchmarked was the performance of the query after the clustered index was put on the temp table. They completely ignored the time it took to build that index or the amount of time it added to the table population if the CI was placed on the table at creation.
I note that I am a big fan of breaking up monster queries into one or more intermediate temp table sets to help out the optimizer!
A few examples off the top of my head (I’m mobile at the moment): uniqueness, getting rid of an inopportune sort prior to a merge join, eliminating giant memory grants for hash joins. Stuff like that. And yeah, this would improve the stored procedure metrics as a whole, not just the part(s) after the temp tables were populated.
I think you’re right to call that out as a consideration. Especially for high volume procedures, that’s a very real cost to consider, and where all these nuances really move front and center. However a lot of the procedures I work on are processes to pre-calculate or aggregate or generally do “ETL-ish” type stuff. In many of these cases, the primary consideration is not locking those live tables that I need to interact with. So if I have to spend time up front to build a temporary index which will mean I can get on and off other tables faster (even only marginally so), that can be important.
OK.. I am confused… Are you saying that non clustered indexes are not any good in Temp Tables ? Your opening paragraph states that “On the rare occurrence that I do see them indexed, it’s a nonclustered index on a column or two. The optimzer promptly ignores this index ……” and then your final paragraph states “When starting to index temp tables, I usually start with a clustered index, and potentially add nonclustered indexes later if performance isn’t where I want it to be.”. So which is it ? Non clustered indexes help or not ?
Well, it’s not a one or the other choice. It’s nonclustered in addition to clustered, but that’s a true rarity. I’d just never say never.
Lol…now I am more confused. I am an accidental dba and the going trend where I work is to put nonclustered indexes on every temp table (sometimes 3 or 4 on each table). I always thought that the NC indexes were always ignored because the execution plan was created when the stored procs were run and because the indexes were being created in the SP it would never be able to use the indexes. I also understand that the clustered index would work because it is created when the table was created. Is there ANY time that a NC index is used in the SP scenario?
Thx Will
That’s probably not a great trend!
Index usage occurs when they’ll make things more efficient, not because of when they’re created (unless they’re created after queries run, but I’m sure that’s not what you mean here).
Go ahead and experiment with creating a clustered index where you’re creating nonclustered indexes now. You’ll probably see things change; whether or not they change for the better is something you’ll have to figure out.
Thanks!
– indexes on temp tables makes usually (!) only sense, if you use the #temp more than once, since an index creation needs a table scan (and if you use the #temp only once then it would be faster, when you make scan in the SELECT and skip the writes for the index creation)
– when you have @@Version >= SQL 2014 you can create NC indexes in the CREATE TABLE statment. If you do this, you have not to scan the #temp (for index creation), but your INSERTs will be slower and you could run into parameter sniffing problems (when the number of rows in the #temp or their statistics differs from run to run), because SQL Server reuses the #temp table
– when you create the indexes in a separate statment (after the INSERT INTO #temp) then it will do a table scan (for each index), but will create new statistics for this index which will cause a recompile of the statments, that uses #temp (-> no parameter sniffing, but the recompile could be slows on complex queries)
-> as always it depends, what you exactly do in you procedures, sometimes it could be better to create no index, sometimes to create the index in the CREATE TABLE statment and sometimes to create it after the INSERT
my 2 cents, be cautious if you are naming your indexes on temp tables. If SP will be executed parallelly then name on index will throw an error.
Utsav – that was true a long, long, LONG time ago, but not in any currently supported version.