
Oh, THAT SARGability
I realize that not everyone has a Full Metal Pocket Protector, and that we can’t all spend our days plunging the depths of query and index tuning to eek out every CPU cycle and I/O operation from our servers. I mean, I don’t even do that. Most of the time I’m just happy to get the right result back!
I kid, I kid.
For those of you out there that have never heard the word before, go watch this. You’ll thank me later. Much later.
What does that have to do with me?
It has to do with you, because you’re still formatting your WHERE clause poorly. You’re still putting expressions around columns and comparing that output to a value, or another expression.
Huh?
Think about times when you’ve done something like First_Name + ‘ ‘ + Last_Name = ‘Meat Tuperello’, or even worse, when you’ve totally broken a date into YEAR(), MONTH(), and DAY() and compared them all to values.
Yes, you. Yes, that’s bad.
More Common
Sometimes people forget that DATEADD exists. They go right to DATEDIFF, because it sounds like it makes more sense.
What’s the difference between these two dates? Can I go home now? I’m so hungry. No one takes the Esperantan money you pay me with, Mr. Ozar.
But this can get you into a lot of trouble, especially if you’re either dealing with a lot of data, or if the WHERE clause is part of a more complicated series of JOINs. Not only does it not make efficient use of any indexes, but it can really screw up cardinality estimation for other operations. What does this peril look like?
|
1 2 3 |
SELECT COUNT(*) FROM dbo.SalesOrders AS so WHERE DATEDIFF(DAY, CONVERT(DATE, so.OrderDate), GETUTCDATE()) = 55 |
Looks good to me
Of course it does. That’s why you’re reading this blog. You have questionable taste. There are some problems with this, though.

We didn’t do too bad with cardinality estimation here. The Magic Math guessed about right for our 10,000 row table. But breakthroughs in Advanced Query Plan Technology (hint: GET OFF SQL SERVER 2008R2) allow us to see that we read all 10,000 of those rows in the index, rather than just getting the 5003 rows that we actually need. Shame on us. How do we do better?
No Sets In The Champagne Room
We’re going to flip things around a little bit! We’re going to take the function off of the column and put it on our predicate. If you watched the video I linked to up top, you’d know why this is good. it allows the optimizer to fold the expression into the query, and push it right on down to the index access. Hooray for us. Someday we’re gonna change the world.
|
1 2 3 |
SELECT COUNT(*) FROM dbo.SalesOrders AS so WHERE CONVERT(DATE, so.OrderDate) = DATEADD(DAY, -55, CONVERT(DATE, GETUTCDATE())) |
Now we get a cheaper index seek, we don’t read the extra 4997 rows, and the cardinality estimate is spot on. Again, it wasn’t too bad in the original one, but we got off easy here.

Face 2 Face
If you’re wondering what the plans look like side by side, here you go.
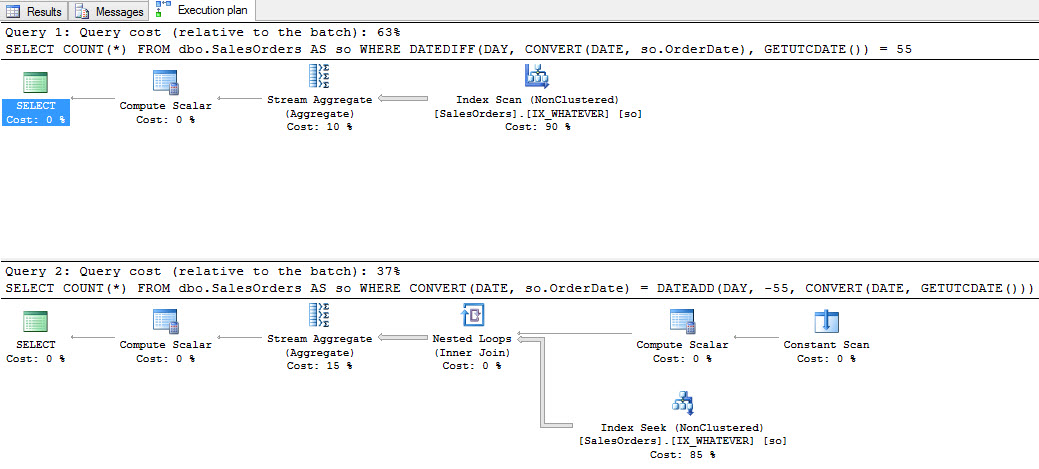
Both plans are helped by our thoughtfully named index on the OrderDate column, though the one with cheaper estimated cost is the bottom one. Yes, I know this can sometimes lie, but we’re not hiding any functions in here that would throw things off horribly. If you’re concerned about the Nested Loops join, don’t worry too much. There is a tipping point where the Constant Scan operator is removed in favor of just index access. I didn’t inflate this table to find exact row counts for that, but I’ve seen it at work elsewhere. And, yeah, the second query will still be cheaper even if it also scans.
Thanks for reading!
Brent says: this is a great example of how people think SQL Server will rewrite their query in a way that makes it go faster. Yes, SQL Server could rewrite the first query to make it like the second – but it just doesn’t go that extra mile for you. (And it shouldn’t, you wacko – write the query right in the first place.)

20 Comments. Leave new
So which functions don’t break SARGability? According to the above, CONVERT works fine?
Any function CAN break SARGability. Even LIKE does when you use ‘%double wildcards%’. It works for DATETIME to DATE because there are special optimizer rules for that. If I converted to a different datatype, like SQL_VARIANT, it wouldn’t work efficiently.
I thought the CONVERT would have affected the SARGability, but apparently not! I’m now thinging of all the time I’ve wasted doing
SELECT COUNT(*)
FROM dbo.SalesOrders AS so
WHERE so.OrderDate >= DATEADD(DAY, -55, CONVERT(DATE, GETUTCDATE()))
AND so.OrderDate < DATEADD(DAY, -54, CONVERT(DATE, GETUTCDATE()))
Well, it looks like you’re doing something different than what Erik demonstrated. His got all orders on a given day 55 days ago, yours gets all orders in a 24 hours block starting at the current time – 55 days. I would have thought CONVERT broke sargability too though!
Dave is correct, Joe. he is comparing the OrderDate to midnight on two days. I have done the same thing many times. I tried this little trick with a large sale table we have. Could not believe my eyes, Who’d a thunk.
Thanks Graeme, you’re both absolutely correct! If they’re both returning the dame data, I wonder if one runs better than the other?
Hi, @Joe–I tried it on a large Sale table, using the SaleDate (DATETIME) as a test. Erik’s method is 0% and the method Joe has used (and I have used) was 100% in comparison. This particular table has 140+ million rows.
Trying the same thing on our DW QA environment. Over 400M rows, I got a 50%/50% split on the two forms in the ExecutionPlan, but the TIME statistic was 400ms vs 1200ms in favor of the form Erik used.
@Erik: where is that list of “Special Optimization Rulez®” kept?
Well, it used to be with Conor, but he’s doing Azure now. You’d have to do some sleuthing to figure out who the new Conor is. Whomever it is would have to have some serious SQL Skills, a big Sack, and wouldn’t be your average Joe. I mean, if I had to speculate.
Definitely not this average Joe 😉
Yea.. SQL2008R2.. Try everything you can so that your not to wrapping a column within a function. Also you might end up making the query easier to read for your mid and jr peeps to read in the future. All of us aint Itzik Ben-Gan ya know. 😉
Why use DATEADD at all? Why not this?
SELECT COUNT(*)
FROM dbo.SalesOrders AS so
WHERE CONVERT(DATE, so.OrderDate) = CONVERT(DATE, GETUTCDATE()-55)
That doesn’t work with DATE and DATETIME(2) datatypes. When I write code, I also try to write it so that it won’t break when things change, or if someone needs to use a similar construct in a different place.
For reference regarding cast to date. http://dba.stackexchange.com/questions/34047/cast-to-date-is-sargable-but-is-it-a-good-idea
Oh, good point! I’ll amend the post today.
Can someone explain to me why simply changing DATEDIFF() with DATEADD() would make such a difference? Both are functions and both still have to calculate a date expression for every row. It’s not like pre-calculating a single date value and removing its calculation from the query. I don’t get it.
You should totally watch the video I linked to in the post! Pay attention to the part about constant folding.
Thanks!
I’m pretty lost on something here. Every single source I’ve found, whether online or in books, says you mustn’t use a function on an Indexed column you are trying to filter on. They all give the same example. Imagine your index is on DateDataColumn. This query is bad and will lead to an Index Scan:
SELECT ParentID
FROM [dbo].[Parent]
WHERE dateadd(d,30,DateDataColumn) > getdate()
However, this query is better and will properly use the index on DateDataColumn (Index SEEK):
SELECT ParentID
FROM [dbo].[Parent]
WHERE DateDataColumn > dateadd(d,-30,getdate())
As long as the function is on the other side of the “>” operator (ie not applied to the indexed “DateDataColumn” column itself), then the Index should be used properly, and it should do an Index Seek. Even the example on this blog post is a comparison between those 2 approaches (function before vs after the ” dateadd(d,-CFG.day, LOM.CurrentTime)
The parent table has millions of records, and there’s a nonclustered index on:
zoneID ASC,
DateDataColumn ASC
Notice how it’s written the “right” way – the function is not wrapped around DateDataColumn, but is rather wrapped around the fields from the 2 tiny tables.
Why would it do an Index Scan instead of a Seek? The function isn’t being applied to the DateDataColumn column, so I don’t see why it would do a scan.
For some reason the format got totally screwed up on my last post, so I’ll try the bottom part again:
I have a query that involves JOINS, and uses values from the joined tables in the Function. But they are tiny tables (10 records each). The only large table is [dbo].[Parent] .
The parent table has millions of records, and there’s a nonclustered index on:
zoneID ASC,
DateDataColumn ASC
Notice how it’s written the “right” way (below)- the function is not wrapped around DateDataColumn, but is rather wrapped around the fields from the 2 tiny tables.
Why would it do an Index Scan instead of a Seek? The function isn’t being applied to the DateDataColumn column, so I don’t see why it would do a scan.
SELECT ParentID
FROM [dbo].[Parent] A
JOIN dbo.ConfigTable CFG
ON a.zoneID = b.zoneID
JOIN dbo.LOM LOM
ON CFG.zoneID = LOM.zoneID
WHERE DateDataColumn > dateadd(d,-CFG.day, LOM.CurrentTime)