
Don’t make me spill
Table variables get a lot of bad press, and they deserve it. They are to query performance what the TSA is to air travel. No one’s sure what they’re doing, but they’ve been taking forever to do it.
One particular thing that irks me about them (table variables, now) is that they’ll spill their spaghetti all over your disks, and not warn you. Now, this gripe isn’t misplaced. SQL Server will warn you when Sort and Hash operations spill to disk. And they should! Because spilling to disk usually means you had to slow down to do it. Disks are slow. Memory is fast. Squatting in the Smith Machine is cheating.
Wouldn’t it be nice?
Why am I picking on table variables? Because people so frequently use them for the wrong reasons. They’re in memory! They made my query faster! No one harbors delusions about temp tables, except that one guy who told me they’re a security risk. Sure, we should get a warning if temp tables spill to disk, too. But I don’t think that would surprise most people as much.
So let’s see what hits the sneeze guard!
You’ve been here before
You know I’m going to use Stack Overflow. Here’s the gist: I’m going to set max memory to 1 GB, and stick the Votes table, which is about 2.4 GB, into a table variable. While that goes on, I’m going to run sp_BlitzFirst for 60 seconds in Expert Mode to see which files get read from and written to. I’m also going to get STATISTICS IO information, and the query plan.
|
1 2 3 4 5 6 7 8 9 10 |
SET STATISTICS IO ON DECLARE @Votes TABLE (Id INT NOT NULL, PostId INT NOT NULL, UserId INT NULL, BountyAmount INT NULL, VoteTypeId INT NOT NULL, CreationDate DATETIME NOT NULL) INSERT @Votes ( Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate ) SELECT v.Id, v.PostId, v.UserId, v.BountyAmount, v.VoteTypeId, v.CreationDate FROM dbo.Votes AS v SELECT COUNT(*) FROM @Votes AS v |
First, let’s look at stats IO output. The first section shows us hitting the Votes table to insert data. The second section shows us getting the COUNT from our table variable. Wouldn’t you know, we hit a temp object! Isn’t that funny? I’m laughing.
|
1 2 3 4 5 |
Table 'Votes'. Scan count 1, logical reads 309027, physical reads 0, read-ahead reads 308527, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (67258370 row(s) affected) Table '#ACD2BA14'. Scan count 1, logical reads 308525, physical reads 36, read-ahead reads 308077, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The query plan doesn’t give us any warnings. No little yellow exclamation points. No red X. It’s all just kind of bland. Even Paste The Plan doesn’t make this any prettier.

Well, unless you really go looking at the plan…
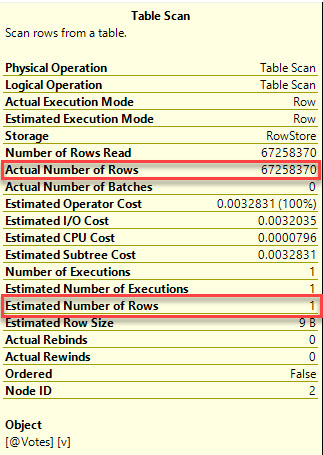
Okay, that sucks
Let’s look at sp_BlitzFirst. Only Young And Good Looking® people contribute code to it, so it must be awesome.

Boy oh boy. Boy howdy. Look at all those physical writes. We spilled everything to disk. That’s right at the 2.4 GB mark, which is the same size as the Votes table. We should probably know about that, right?
Is a temp table any better?
In short: kinda. There are some reasons! None of them are in stats IO. They’re nearly identical.
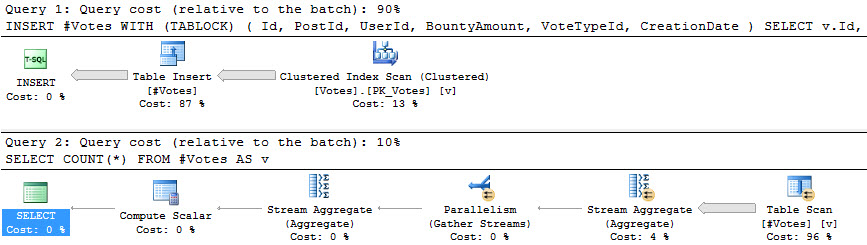
For the insert, the scan could go parallel, but doesn’t. Remember that modifying table variables forces query serialization, so that’s never an option to us.
In SQL Server 2016, some INSERT operations can be fully parallelized, which is really cool. If it works. Much like minimal logging, it’s a bit of a crapshoot.
The COUNT(*) query gets an accurate estimate and does go parallel. Hooray. Put those pricey cores to use. Unless you recompile the query, you’re not going to get an accurate estimate out of your table variable. They’re just built that way. It doesn’t even matter if you put an index on them.
Does sp_BlitzFirst tell us anything different?

Yeah! For some mystical magical reason, we only spilled out 1.8 GB, rather than the full 2.4 GB.
Party on, Us.
I still hate table variables
I mean, I guess they’re okay if the # key on your keyboard is broken? But you should probably just buy a new keyboard and stop using Twitter.
Anyway, I think the point was that we should have some information at the plan level about spills to disk for table variables and (possibly) temp tables. It wouldn’t help tools like sp_BlitzCache, because spill information isn’t in cached plans, but it might help if you’re doing live query tuning.
Thanks for reading!
Brent says – OMG THESE ARE SPILLS TOO. I never thought of it that way.

28 Comments. Leave new
I used to use table variables for development so I don’t have to futz with dropping and creating them like you do with temp tables. I still do, but I used to too. Now that we’re on 2016, I stick that newfangled DROP IF EXISTS above my temp tables and let ‘er rip.
Warmly recompiled regards,
-Brandon M.
33/M/Capricorn
I bet you drop your deadlifts, too. Sheesh.
wooof! shots fired!
You’re never supposed to drop your deadlifts, if you do then that’s considered a ZERO!!!
I have a general rule < 10000 rows + testing or one off = a ok for table var.
It makes it so much easier when I made some stupid syntax error half way down and didn't get to where I would drop the # (yes, I know, I know IF…exists drop). An setting to drop temp tables the same way table variables would be boss for me sometimes. Something like "set tempdrop on" or something.
Yeah, I only jump out of windows that are less than 10 floors up. So far that’s been working.
Hey Erik, you paint with too broad of a brush! Sometimes you have a little lookup table built on-the-fly or a key list with about 20 rows. Under those circumstances a table variable is very convenient and won’t kill performance. Also, if you want to pass a short list of keys between procs then a table variable makes some sense. Just always remember that the optimizer thinks your table variable contains one row and think accordingly.
Using a table variable with a handful of rows is more like jumping off a chair than out of a window 10 floors up. OK, a really low chair. If you can’t handle the short jumps then you can borrow my father’s walker. So far that’s been working. 😉
Here’s another significantly tortured analogy… OK, it had an extraordinary rendition yesterday… criticizing a table variable’s performance when you stuff a lot of data into it is like criticizing your bicycle because it doesn’t go fast when you put a few hundred pounds of bricks in your pockets. It just wasn’t made for that. Neither are you. Something is gonna spill.
Yes, when performance isn’t a consideration, table variables are just fine.
yea, when I’m testing the logic of something or running through sub 1000 records, it doesn’t matter. Is running it in 1.5 seconds instead of 2 seconds better? yea, I suppose, does it matter in my little test or one off? no, not really.
Do realize that even with 1 row of data in a table variable performance is not consistent or guaranteed, there are many instances that I’ve read and personally come across that will show that table variables are exactly what the name says it is…variable. If you want consistency you always go with temp tables
Great example. Thank you!
Thanks!
This is great information, but if you have adequate memory do you still get the spillage? In the example you set max mem to 1GB, and then performed the table variable example on a 2.4GB table. How much spillage would you see if your max mem was 4 GB instead? Also, how much of a factor would spillage be if you have “fast” disks?
Right, it’s less of a problem with adequate memory, but it can still occur. On the other hand, is this really what I want to be using memory for?
If you want to know how much of a difference it can make, check out this link: https://gist.github.com/hellerbarde/2843375
Thanks for presenting this in an easily grokable fashion Erik. I’ve got a question – Why is there an even 3-way split to tempdb instead of a 4-way split in the temp table version?
I’m not sure entirely! Some of it is possibly attributable to this.
But after several cache dumps and retries, it ended up the same every time.
Hi,
nice blogpost and I absolutely agree to leave table variables alone. However I got “enlighted” just a few days ago and there’s a lot of conversion work still to be done ;-). I just liked to state one case where table variables are nice and handy…you can define a custom type bind it to a table variable and use this variable as an input of a function or prodedure. Of course this could be performance hell, too. I just use this technique for some dynamic sql generation procedures which operate on metadata and are not really performance sensitive (I don’t really care if I get my generated SQL in 1 second or in 5 seconds).
I like that a table var lives across transactions for accumulating stuff during a long script. But that is a limited use case.
What is really like to see is a query option you can use to override the estimated number of rows.
Well, you can use OPTION(RECOMPILE) to get accurate row counts, but that’s not really a great… option. Damn.
Exactly. What I’d prefer is an OPTION(ROWCOUNT=expression). Then the optimizer uses my number instead of (nonexistent or wrong) statistics
The TSA confiscated my table variables the last time I flew. Apparently they’re now banned from airplanes, as well as @.
Global temp tables ARE a security risk
Hey Erik, I use table variables because when each query is tiny and the query plan is pretty stable, then I get more throughput with them.
Check out these two procedures:
--7000 batches per second
create procedure s_dosomething1 as
create table #whatevs
(
i int primary key
)
insert #whatevs (i) values (1), (2), (3);
select sum(i) from #whatevs;
go
-- 45000 batches per second
create procedure s_dosomething2 as
declare @whatevs table
(
i int primary key
)
insert @whatevs (i) values (1), (2), (3);
select sum(i) from @whatevs;
go
This kind of use (high-frequency queries that are short but sweet) is most common in our shop.
Well, those will never spill, will they? 😉
Hi, Erik! Look into https://msdn.microsoft.com/en-us/library/bb522526(v=sql.105).aspx. “You can use a user-defined table type to declare table-valued parameters for stored procedures or functions”. What do you suggest to use instead of the table variables in this case?
I know it sounds like the opposite of everything I’ve been saying, but I love TVPs. Not because they’re better than regular Table Variables, but because they’re a much better tool for the job. What I see people do frequently instead is pass in a CSV list and use some god awful string splitter they found on the internet based on a while loop to parse them. If you find you’re passing in many thousands or more rows via your TVPs, it’s pretty easy to test dumping them into a temp table after they hit your stored proc.
“None of them are in stats IO” – no comprendo. Isn’t a horrible estimate a reason for high logical I/O, which we see in stats IO?
“I guess they’re okay if the # key on your keyboard is broken?” – I’m stealing that phrase 🙂 My apologies, I like it so much.
Heh, no, not necessarily. That’s a measure of how many pages were read during query execution. It could be different in the case of bad estimation if the optimizer chose a different index because of the bad estimate. Logical reads are pages already in memory.
What I was talking about though, is that STATS IO doesn’t show you writes to pages, or spills to disk.
As a quick for-instance, this query doesn’t generate any STATS IO output, even though it presumably has to allocate and write data to at least one page.
USE tempdb
SET STATISTICS IO ON
SELECT *
INTO #crap
FROM (
VALUES
(1, 2),
(1, 2),
(1, 2),
(1, 2),
(1, 2),
(1, 2),
(1, 2),
(1, 2),
(1, 2),
(1, 2)
) x (a, b)