
This is not about table partitioning
If you want to learn about that, there’s a whole great list of links here, and the Best Blogger Alive has a tremendous post on why table partitioning won’t make your queries any faster over here.
With that out of the way, let’s talk about partitioned views, and then create one from a real live table in the StackOverflow database.
What is a partitioned view?
It’s a view that combines the full results of a number of physical tables that are logically separated by a boundary. You can think of the boundary the same way you’d think of a partitioning key. That’s right about where the similarities between table partitioning and partitioned views end.
For example, you have Table1, Table2, and Table3. All three tables are vertically compatible. Your view would look something like this.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE VIEW dbo.Doodad AS SELECT columns... FROM Table1 UNION ALL SELECT columns... FROM Table2 UNION ALL SELECT columns... FROM Table3 SELECT * FROM dbo.Doodad |
Hooray. Now you have to type less.
Partitioned views don’t need a scheme or a function, there’s no fancy syntax to swap data in or out, and there’s far less complexity in figuring out RIGHT vs LEFT boundaries, and leaving empty partitions, etc. and so forth. You’re welcome.
A lot gets made out of partition level statistics and maintenance being available to table partitioning. That stuff is pretty much automatic for partitioned views, because you have no choice. It’s separate tables all the way down.
How else are they different?
Each table in a partitioned view is its own little (or large) data island. Unlike partitioning, where the partitions all come together to form a logical unit. For example, if you run ALTER TABLE on a partitioned table, you alter the entire table. If you add an index to a partitioned table, it’s on the entire table. In some cases, you can target a specific partition, but not all. For instance, if you wanted to apply different compression types on different partitions for some reason, you can do that.
With partitioned views, you add some flexibility in not needing to align all your indexes to the partitioning key, or alter all your partitions at once, but you also add some administrative overhead in making sure that you iterate over all of the tables taking part in your partitioned view. The underlying tables can also all have their own identity columns, if you’re into that sort of thing. If you’re not, you should use a Sequence here, assuming you’re on 2012 or later.
Are partitioned views better?
Yes and no! The nice thing about partitioned views is that they’re available in Standard Edition. You can create tables on different files and filegroups (just like with partitioning), and if you need to change the data your view covers, it’s a matter of altering the view that glues all your results together.
Tables can have different columns (as long as you account for them in your view definition), which isn’t true for partitioning, and you can compress or index different indexes on different partitions differently depending on the workload that hits them. Think about reporting queries that want to touch your historical data. Again, not ‘aligning’ all your nonclustered indexes to the partitioned view boundary doesn’t necessarily hurt you here.
They do share a similar problem to regular partitioning, in that they don’t necessarily make your queries better unless your predicates include the partitioning key. Sad face. It is fairly easy to get partition elimination with the correct check constraints, as long as you include a partition eliminating element in your query predicates. If your workload doesn’t reliably filter on something like that, neither form of partitioning is going to help your queries go faster.
One problem I’ve found particularly challenging with partitioned views is getting the min/max/average per partition the way you would with normal partitioning. There are a couple good articles about that here and here, but they don’t really help with partitioned views. If anyone out there knows any tricks, leave a comment ;^}
Modifications can be tricky, too. Bulk loads will have to be directed to the tables, not the view itself. Deletes and updates may hit all the underlying tables if you’re not careful with your query predicates.
Ending on a high note, the view name can obfuscate sensitive table names from them there hackers.
From the comments!
Geoff Patterson has a Connect Item about pushing Bitmap Filters through Concatenation Operators, which would be really powerful for Partitioned Views.
If this kind of thing would suit your needs, give it an upvote over here.
Enough already, what’s it look like?
Download the script below. It assumes that you have a copy of the StackOverflow database with the Votes table, and that you’re not a StackOverflow employee running this on the production box. Things might get weird for you.
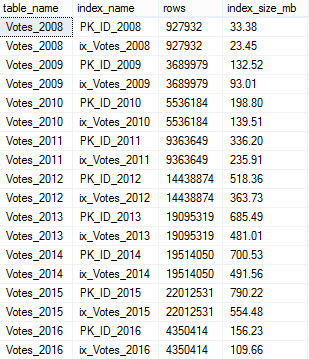
Assuming everything runs correctly, in about a minute you should have a series of tables called Votes_20XX. How many you end up with depends on which copy of the database you have. Mine has data through 2016, so i have Votes_2008 – Votes_2016.
Each table has a PK/CX on the Id column, a constraint for the year of dates in the table on the CreationDate column, and a nonclustered index to help out some of our tester queries. You can just hit f5, and the RETURN will stop before running any of the example queries.
You should see something like this when it’s done. Yay validation.
How does query work?
It’s pretty easy to see what I was talking about before. If you’re not looking at CreationDate in the WHERE clause, you end up touching a lot of tables. When you use it, though, SQL is really smart about which tables it hits.

Ranges work pretty well too.

Even when they’re broken up!

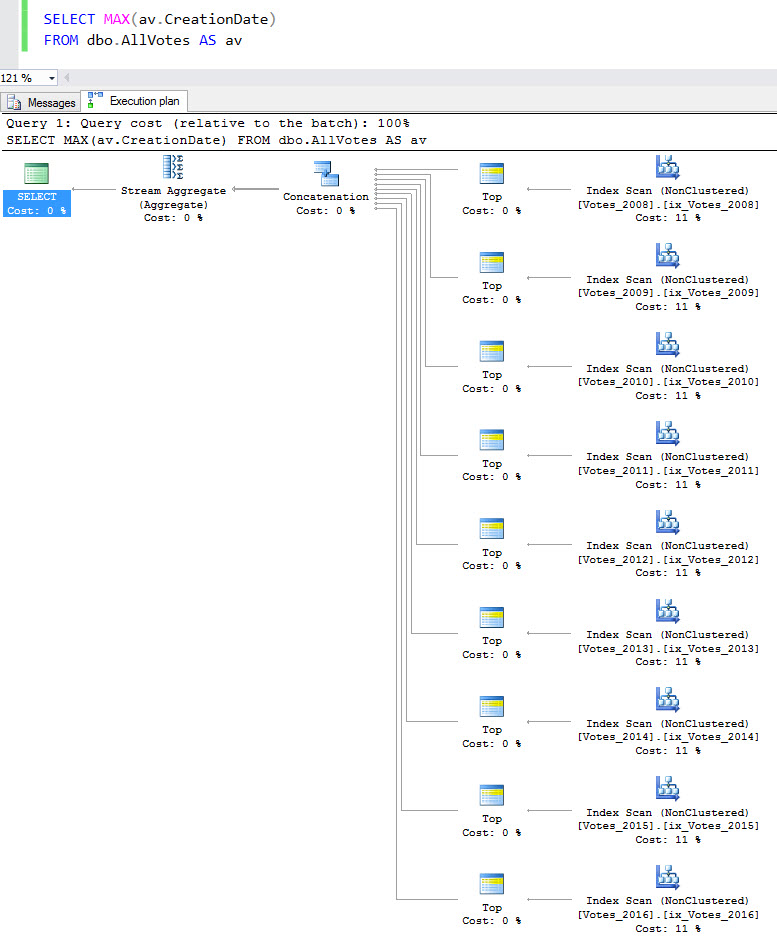
But if you don’t specify a date, you run into trouble.

You’d think this would go better, but it doesn’t. I mean, the MAX date would have to come from the… oh, forget it.
That’s all, y’all
I hope you enjoyed this, and that it helps some of you out. If you’re looking to implement partitioned views, feel free to edit my script to work on your table(s). Just make sure it’s on a dev server where you can test out your workload to make sure everything is compatible.

24 Comments. Leave new
Silly question, maybe, but would adding a ‘Year’ column to each table making up the view, and populating it with the appropriate constant, like ‘2015’, give you any advantage in getting data by partition?
Or does the creation date and associated indexing already give you the same benefit?
It might get you some smell-good if you were looking at an equality on an entire year at a time, though how much more I couldn’t tell you without adding that in. It may make additional predicates on more granular dates worse, though. You’d need probably need to create columns for those. Then indexing gets uglier, too.
I was just thinking of your comment about getting the min/max/average per partition – but yes, getting more granular than that could take you down one of those rabbit holes to hierarchical madness…
In a similar direction, maybe it’s possible to emulate Itzik Ben Gan’s solution by adding a column to the view which will hold a partition number.
I Am interested to read that blog. pl share the link of ” Itzik Ben Gan’s solution by adding a column to the view which will hold a partition number”
Please can anyone provide me link or source to get every detail of HIVE PARTITION from scratch to top level in lucid manner.i would be obliged.
My email id please provide me source link for relevant material:
delhilife143@gmail.com
For random, unrelated questions, head on over to http://dba.stackexchange.com/questions
Nice article, Erik. If you get down in the weeds with partitioned views on larger data sets, one other shortcoming to be aware of is that you may lose the handy in-row bitmap filters that you are used to with star join queries on partitioned tables. I have a fairly long-standing Connect issue on this: https://connect.microsoft.com/SQLServer/feedback/details/974909/
Even so, they’re a very useful option to know about! In terms of min/max, we’re typically creating partitioned views (on top of partitioned tables, to sort of cheat and partition on two dimensions) in an automated fashion. Therefore, we’ll have a metadata table that describes, among other things, the min/max values for the check constraint to be applied to each table. We store the information mostly so that we can automatically generate the check constraints for a given table, but that metadata table can then be used to dynamically construct your own more optimal min/max queries if you like. A lot of work, but it’s one solution.
Ooh! That’s slick! I always considered partitioned views either for people with EE, or for people without a DBA to pick through the gotchas of regular partitioning. Hadn’t thought of it like that, which is pretty neat.
I totally voted for your Connect item. I’m going to add it to the text of the post so hopefully it gets some more attention.
Partitioned views can produce even better plans than partitioned tables do for some queries (need to stress “some”). This is purely due to optimizer limitations since the optimizer could break up a partitioned table access into branches, of course. But that’s the way it is.
For example, if you want (select * from T where OpaquePredicate order by ClusteringKey)! That gets a merge concat with N-1 merges for partitioned views. A partitioned table cannot produce a sorted stream of rows directly because the stream will be sorted by PartitionKey, ClusteringKey.
That’s really cool! I’ll add an example with a query like that. Thanks.
When I click on the script link… it takes me to Kendra’s video… :/
I’m a least 90% sure you’re clicking on the wrong link.
It is REALLY weird… Here on Bozar it links and works perfectly. But from Exchange, in the HTML email, with the obsfucated Mailchimp (or whoever) links, I get really weird (inconsistent, depending on what link I clicked previously in the article) results.
e.g.
If I click the first link (to the Partitioned Tabled Resources), then on the Partitioned_View_Votes, it takes me to the Partitioned Tabled Resources page again.
If I click the SQL Performance Aggregates and Partitioning link, and then the Partitioned_View_Votes link, it again just keeps the SQL Performance page as the result.
For debugging purposes, this is an email opened in Outlook 2016, with Edge set as the go-to Browser.
:/
Just do what we do: blame Brent.
ON IT!!
http://www.cafepress.com/mf/81159584/jayzeedbatee_tshirt?productId=923277644
Hi, I have a problem with partitioned view. Link of problem description: http://stackoverflow.com/questions/41853024/partitioned-view-filter-doesnt-work-correct
Can you help me with it?
Hi Oleksandr, I’m not as familiar with StackOverflow, but on http://dba.stackexchange.com you’d typically want to include a script that allows people to create the problem themselves, view the query plan, test any ideas, and therefore present a more complete solution. dba.stackexchange might also be a good home for your question.
The answer in this case is that table elimination within a partitioned view generally requires you to have a predicate that guarantees that the table can be eliminated from the plan at compile time. This is not the case for your join, in which SQL Server cannot prove that tables are able to be eliminated until run-time. In most cases (a potential exception being a loop join with a startup filter, for example), this means you will not get table elimination and you may suffer a significant performance degradation.
A potential workaround is to first query your dimension table in order to establish the min/max dates you’ll need, and then also add those as a (redundant) predicate to your query (e.g., “vwSalesOutH.Date>=’XXX’ AND vwSalesOutH.Date<='yyy'). This will allow table elimination, sometimes vastly improving performance.
This is an imperfect solution in several ways, however: It might require application code changes, and it might also impact cardinality estimates. We've especially seen this with the new base containment algorithm in the new CE (read https://msdn.microsoft.com/en-us/library/dn673537.aspx, especially the "Join Containment Assumption Changes" section, for a lot more info).
Such is life with partitioned views, in our experience 🙂
Thank you for answer. Using partitioned views is so limited(….but such is life:)
So, how would you add an Index to a View that pulls from a Partitioned table? I have a table script to create a table – showing just the first and last lines.
As you can see, the last part of the script specifies the Partition Scheme and partitioning field).
CREATE TABLE dbo.DrugPrice
(
ID bigint NOT NULL IDENTITY (1, 1),
InsertDateTime datetime NULL
) ON [PS_P_ReportWeekly]([SendDateTime])
GO
And currently have a script to create a View
CREATE VIEW dbo.vw_DrugPrice
WITH SCHEMABINDING
AS
SELECT ID,
InsertDateTime
FROM dbo.DrugPrice
GO
And there is no reference to the Filegroup or Partition Scheme to use.
But we have another View with this to create an Index, and it specifies the [Primary] filegroup.
If adding an Index to this new View of an Partitioned table, do I need to refer to the Partition Scheme, or just the [Primary] filegroup?
CREATE UNIQUE CLUSTERED INDEX [CX_InsertDateTime] ON [dbo].[vw_DrugPrice]
(
[ID] ASC,
[InsertDatetime] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
or ….
CREATE UNIQUE CLUSTERED INDEX [CX_InsertDateTime] ON [dbo].[vw_DrugPrice]
(
[ID] ASC,
[InsertDatetime] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PS_P_ReportWeekly]([SendDateTime])
GO
Or do I just leave off that whole section of code starting with the WITH clause?
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PS_P_ReportWeekly]([SendDateTime])
William – for support questions, hit a Q&A site like https://dba.stackexchange.com.
We are looking at a partitioned view as a replacement for a very large table, following your example of annualized tables. Our reason is to improve the index maintenance cycle. Firstly, the one large table’s rebuild/reorg time exceeds the available weekday maintenance window and instead, it hogs the longer weekend maintenance window; the annualized tables will be smaller so a series of shorter rebuilds/reorgs. Secondly, the data in the older annualized tables will change much less such that they will seldom trigger a rebuild/reorg at all.
To your knowledge is their any practical limit to how many tables are in a partitioned view? For example, if monthly tables were used over a 30 year period (ie 360 tables), would the partitioned view work as well?
John – for questions, head to a Q&A site like https://dba.stackexchange.com.