
One of my least favorite things about Availability Groups

Well, really, this goes for Mirroring and Log Shipping, too. Don’t think you’re special just because you don’t have a half dozen patches and bug fixes per CU. Hah. Showed you!
Where was I? Oh yeah. I really didn’t like the backup and restore part.
You find yourself in an awkward position
When you’re dealing with large databases, you can either take an out of band COPY_ONLY backup, or wait for a weekly/daily full. But, if you’re dealing with a lot of large databases, chances are that daily fulls are out of the question. By the time a full finishes, you’re looking at a Whole Mess O’ Log Restores, or trying to work a differential into the mix. You may also find yourself having to pause backups during this time, so your restores aren’t worthless when you go to initialize things.
You sorta-kinda got some relief from this with Availability Groups, but not much. You could either take your backups as part of the Wizarding process (like Log Shipping), figure it out yourself (like Mirroring), or defer it. That is, until SQL Server 2016.
Enter Direct Seeding
This isn’t in the GUI (yet?), so don’t open it up and expect magic mushrooms and smiley-face pills to pour out at you on a rainbow. If you want to use Direct Seeding, you’ll have to script things. But it’s pretty easy! If I can do it, anyone can.
I’m not going to go through setting up a Domain Controller or Clustering or installing SQL here. I assume you’re already lonely enough to know how to do all that.
The script itself is simple, though. I’m going to create my Availability Group for my three lovingly named test databases, and add a listener. The important part to notice is SEEDING_MODE = AUTOMATIC. This will create an Availability Group called SQLAG01, with one synchronous, and one asynchronous Replica.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
CREATE AVAILABILITY GROUP [SQLAG01] FOR DATABASE [Crap1], [Crap2], [Crap3] REPLICA ON N'SQLVM01\AGNODE1' WITH (ENDPOINT_URL = N'TCP://SQLVM01.darling.com:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY), SEEDING_MODE = AUTOMATIC), N'SQLVM02\AGNODE2' WITH (ENDPOINT_URL = N'TCP://SQLVM02.darling.com:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY), SEEDING_MODE = AUTOMATIC), N'SQLVM03\AGNODE3' WITH (ENDPOINT_URL = N'TCP://SQLVM03.darling.com:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY), SEEDING_MODE = AUTOMATIC); GO ALTER AVAILABILITY GROUP [SQLAG01] ADD LISTENER N'SQLAGLISTEN01' ( WITH IP ((N'123.123.123.13', N'255.255.255.0')), PORT=6000); GO |
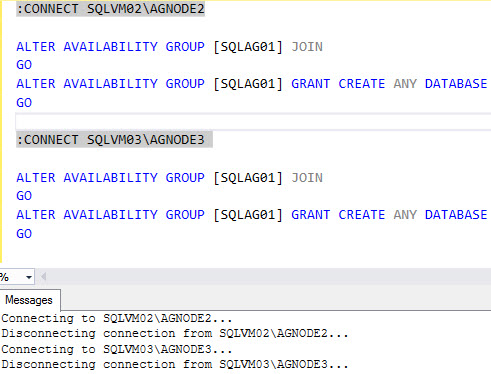
The next thing we’ll have to do is join our Replicas to the AG with the GRANT CREATE ANY DATABASE permission. I prefer to do this in SQLCMD mode so I don’t have to change connections manually.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
:CONNECT SQLVM02\AGNODE2 ALTER AVAILABILITY GROUP [SQLAG01] JOIN GO ALTER AVAILABILITY GROUP [SQLAG01] GRANT CREATE ANY DATABASE GO :CONNECT SQLVM03\AGNODE3 ALTER AVAILABILITY GROUP [SQLAG01] JOIN GO ALTER AVAILABILITY GROUP [SQLAG01] GRANT CREATE ANY DATABASE GO |
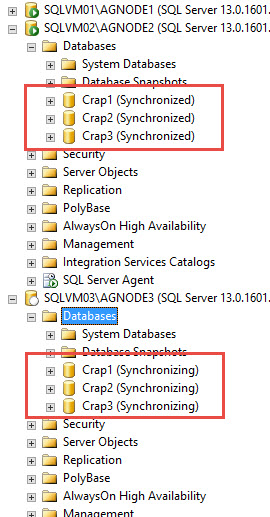
Shocked, SHOCKED
And uh, that was it. I had my AG, and all the databases showed up on my two Replicas. Apart from how cool it is, it’s sort of anti-climactic that it’s so simple. People who set their first AG up using this will take for granted how simple this is.
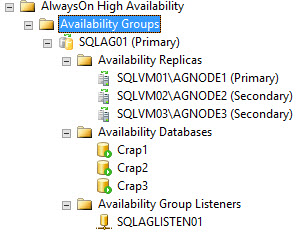
What’s really nice here is that when you add new databases, all you have to do is add them to the Availability Group, and they’ll start seeding over to the other Replica(s). I need to do some more playing with this feature. I have questions that I’ll get into in another post in the future.
|
1 2 3 4 5 6 |
CREATE DATABASE [Crap4] GO ALTER AVAILABILITY GROUP SQLAG01 ADD DATABASE [Crap4]; GO |
These are empty test databases, so everything is immediate. If you want to find out how long it will take to Direct Seed really big databases, tune in to DBA Days Part 2. If anyone makes a SQL/Sequel joke in the comments, I will publicly shame you.
Thanks for reading!
Update! The Man With The PowerShell Plan himself, Mike Fal, also wrote about this feature for T-SQL Tuesday. Check it out.
Brent says: wanna see this capability get added to SSMS for easier replica setup? Upvote this Connect item.

40 Comments. Leave new
All right! Thanks for participating Erik!
As a dev, a lot of this AG stuff is new to me. And with 2016 features, a lot of this stuff is new to everyone.
No problem! Thanks for hosting! I’ve been drooling over this feature.
I assume that when you do this, SQL does a compressed backup. but is it any different than a regular compressed backup you do through a backup command? is it more compressed or somehow optimized to get AO going faster?
last weekend i set up an AO on two dozen databases and it took 3 hours compared to a 24 hour full backup to set up one db for mirroring on SQL 2005
Alen – I have a blog post coming up where I try to answer those questions. It’s a little more complicated (as usual).
Did your setup use 2016 with this feature?
it was 2012, but we have a 450GB database on SQL 2005 that takes about a day to back up and set up mirroring for in case mirroring fails.
we’re testing 2012 and it literally took 3 hours to set up that database and two dozen others for Always On
Testing 2012! Wild. From a practical standpoint, I wouldn’t push out a new AG deployment on anything older than 2014. So many fixes and improvements. 2012 is still v1 of the feature.
Are you testing on the same hardware? Probably not… so there’s that 🙂
Do you know if this works if TDE encryption is on for one or more db’s in the AG?
I haven’t quite gotten that far yet, so I’m not sure. It will probably line up with prior behavior — adding TDE to an existing AG database is simple, while adding an encrypted database to an AG required a bunch of extra work.
I figured as much, but was hoping there might be a surprise to alleviate this pain point for us.
You mean you don’t trust AlwaysEncrypted? 😉
If I needed to have a copy (replica) of a few production databases at an offsite DR/COOP site, would a direct seed like this be a good option?
If you don’t need them to be readable, there are less complicated features you could also use, like Mirroring or Log Shipping.
If you do need them to be readable, you’re stuck with AGs, or Replication.
Well, log shipping can have readable secondaries…
Bit off topic, but have you seen Brent on today’s Dilbert strip?
http://dilbert.com/strip/2016-06-15
HAHAHA
Been waiting for this feature. The pain of setting up multiple replicas for a 10TB instance…
I’ll also want to know how well direct seeding works with large DBs.
And, according to Mike Fal’s post, you cannot add replicas later?! What’s up with that.
Alex – when you say “setting up multiple replicas for a 10TB instance” – do you really wanna push, say, 3x10TB of data through the primary’s network card during production hours?
Basically yes, as our infrastructure can handle it. But I agree that I’d like some control over the timing and the rate. And have it compressed.
Also, since we’re in 2016, I’d like to combine it with Distributed AG, so it’s only sent once to a remote site.
Alex – you don’t get any control over timing or rate.
I’m not sure if I’d like this approach and correct me if I’m wrong, but for bigger databases, that will be a killing overhead for the primary replica to send them across, apart from your network.
Restoring the latest backup can take long or longer, but you don’t really care, once it’s done, (and diffs and logs and so on) your replicas are in almost perfect sync with the primary, so joining them will be very light process.
I give you that for convenience, yes, it’s more convenient to leave SQL Server to do all the work.
Cheers.
Raul – bingo.
As with anything in SQL Server, the phrase “it depends” applies. For small databases, this could be perfect for deploying. For other, larger databases, a little more care is needed. You need to know your databases, your environment, and what your needs are.
This is about understanding your options. Also, as I discuss on my own blog, this feature is new and a little raw. My thought is that MS will be further developing/improving this, but it’s usable now. It’s just like other aspects of AGs: Using it takes a little more care.
Does the FILE Sturcture on both servers should be same ?
We are setting up on PR and DR, so DR instance name is like DRxxx and prod is like PRxxx
GUI for Direct seeding is available now , looks awesome !
https://docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
Just to clarify – that link is to download SSMS, and it doesn’t have pictures of the GUI, heh.
Incorrect value in the is_compression_enabled column in sys.dm_hadr_physical_seeding_stats while using compression
The DMV sys.dm_hadr_physical_seeding_stats shows the status of current ongoing seeding activities. The is_compression_enabled column in this DMV reflects whether the seeding is being done with compression (using trace flag 9567) or without compression. However, there is a known issue on this. While seeding with compression, this column shows a value of 0 (meaning no compression), which is incorrect. This known issue is expected to be addressed in the product soon.
Yep — I’ve seen that article.
HI Brent, Yes that link doesn’t have a Picture ,this is what i meant… after downloading this latest version of SSMS i tried direct seeding with two 600 GB + db’s and it looked awesome while configuring the DB for direct seeding and successfully Synced the db’s on to a replica.
I can’t think of any SQL jokes like you guys, I feel so left outer
…Bring it on
Don’t CROSS me ;D
Adding a new database to an existing AG with automatic seeding enabled doesn’t seem to automatically seed the new database to the secondary AG replica(s).
Does that really work?
Try taking a full backup first.
I’ve been trying to find some information on where this permission is stored:
ALTER AVAILABILITY GROUP [SQLAG01] GRANT CREATE ANY DATABASE
You’d imagine it’s sys.server_permissions but I’ve tested thoroughly and it’s not there (if you grant/revoke that table doesn’t change). It’s not a membership in a server role permission either. It also doesn’t appear to be exposed by any of the AG DMVs.
If you happen to find it stored anywhere please let me know.
Does it work with DB in 2012 compatibility? I tried, does not seems to.
Peng – it should, but post the *exact* error message you get, and that may help.
It worked when I run only one “alter availability group..add database”.
The first time I had 2 add without “go” in between. The second DB happened to be in 2012 mode. It was added to primary, no error on neither replicas. Waited for 2 hours, still no show on secondary. Small DB, 2 GB each mostly empty. Servers are in test mode, no users. Both replicas are VMs in different data centers. Nothing in event logs.
Thanks.
[…] environments, when I add a new database to an AG, I’ll back it up to NUL, then use direct seeding to initialize the database into the AG. It’ll get a real backup tomorrow, and that’s […]
Did crap4 work for you? Because when I tried adding a new DB to the AG, it added, but, it did not seed on the secondary and hence db couldn’t join to the AG on the secondary. So, that didn’t work for me.
Cool stuff, I was tasked 3 weeks back with setting up auto seeding across 4 replicas. The catch was the app will create databases on the fly. I got a nice script working that will seed them 1 at a time regardless if it creates many. Seems to work 100% one at a time pushing across the group. Last week someone said lets introduce TDE “Yikes” right…I got that piece working on top of it also. Had to write a little encryption timer\checker to determine when encryption is done to perform the backup prior to snapping into the AG group. All in a .ps1 file that I use a job to launch in 4min intervals so far. More fun I have been having is automating Azure AG Failovers with PowerShell.