
Before SQL Server 2016, you might have used a function like Jeff Moden’s DelimitedSplit8k function or Adam Machanic’s CLR version. (Aaron Bertrand has a huge post comparing performance of different string splitting methods, too.)
But there’s a new, faster game in town! SQL Server 2016 introduces a brand new STRING_SPLIT function:
|
1 |
SELECT * FROM STRING_SPLIT('This is a space-delimited string that I would like to split.', ' '); |
Here’s how the results look:

In that example, the ‘ ‘ part at the end is me passing in a space – my list is delimited with spaces. You can do a comma-delimited list, too:
|
1 |
SELECT * FROM STRING_SPLIT('apples,bananas,carrots,Dead Kennedys',','); |
Here’s how it looks:
And is it faster? Heck yeah, it’s faster, as Aaron Bertrand proved.
You can also join to it with CROSS APPLY
Most people who need to split strings don’t just need to split one. They’ll need to do it a whole bunch of times. To call the function over a table column, you need to use CROSS APPLY.
|
1 2 3 4 |
SELECT p.[Id], [p].[Body], [ss].[value] FROM [dbo].[Posts] AS [p] CROSS APPLY STRING_SPLIT([p].[Body], ' ') AS [ss] WHERE [p].[Id] = 4 |
Like most internal functions, you can’t readily get the code. That’s why I’m not going to do a benchmark test against other options here. It might be unfair if MS leveraged some fancy-pants super-secret-squirrel-sauce.
Getting row numbers using ROW_NUMBER
One thing I’ll point out though, is that if you’re used to using DelimitedSplit8K, you might miss the fact that it also returns a row number. This is particularly useful if you’re always interested in the Nth element of a returned string. In order to get that, you need to call it like so.
|
1 2 3 4 5 6 7 8 9 |
SELECT p.[Id], [p].[Body], [x].[value], x.[RN] FROM [dbo].[Posts] AS [p] CROSS APPLY ( SELECT ss.[value], ROW_NUMBER() OVER (PARTITION BY [p].[Id] ORDER BY [p].[Id]) AS RN FROM STRING_SPLIT([p].[Body], ' ') AS [ss] ) AS x WHERE [p].[Id] = 4 AND x.[RN] = 2 |
Since this function is of the inline table valued variety, you’re free to put all sorts of different predicates on the results it returns, which come back in a column called value. You can use ranges and not equal to constructs just as easily. For brevity I’m just throwing out a couple examples for equality and IN.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT p.[Id], [p].[Body], [ss].[value] FROM [dbo].[Posts] AS [p] CROSS APPLY STRING_SPLIT([p].[Body], ' ') AS [ss] WHERE [p].[Id] = 4 AND [ss].[value] = 'change' SELECT p.[Id], [p].[Body], [ss].[value] FROM [dbo].[Posts] AS [p] CROSS APPLY STRING_SPLIT([p].[Body], ' ') AS [ss] WHERE [p].[Id] = 4 AND [ss].[value] IN ('change', 'trans', 'convert') |
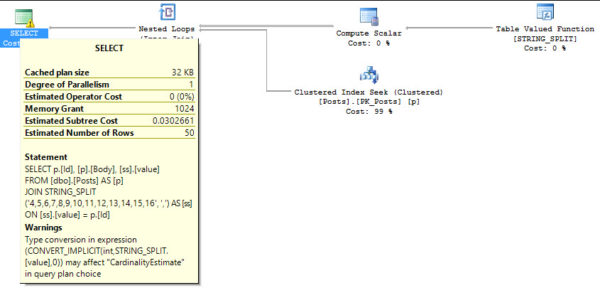
Where a lot of people will likely find this useful is for passing lists of values into a stored procedure or other piece of code. You can also perform normal JOINs to it.
|
1 2 3 4 5 6 7 8 9 |
SELECT p.[Id], [p].[Body], [ss].[value] FROM [dbo].[Posts] AS [p] JOIN STRING_SPLIT('4,5,6,7,8,9,10,11,12,13,14,15,16', ',') AS [ss] ON [ss].[value] = p.[Id] SELECT p.[Id], [p].[Body], [ss].[value] FROM [dbo].[Posts] AS [p] RIGHT JOIN STRING_SPLIT('4,5,6,7,8,9,10,11,12,13,14,15,16', ',') AS [ss] ON [ss].[value] = p.[Id] |
A couple words of warning here, though. Even though this works, if the string is passed in with spaces, there will be spaces in your results. This doesn’t change the join working for numbers, but it may for text data. The other issue, and the reason the numeric join works fine, is that it returns an NVARCHAR datatype. That means you’ll see implicit conversion warnings in your plan if your joins are performed like in this scenario.
But hey, don’t let that stop you from having a good time. You can use the returned value in CASE statements as well.
|
1 2 3 4 5 6 |
SELECT p.[Id], [p].[Body], [ss].[value], CASE WHEN [ss].[value] LIKE '[^a-zA-Z]%' THEN 1 ELSE 0 END AS [Doesn't Start With A Letter], CASE WHEN [ss].[value] LIKE '[^0-9]%' THEN 1 ELSE 0 END AS [Doesn't Start With A Number] FROM [dbo].[Posts] AS [p] CROSS APPLY STRING_SPLIT([p].[Body], ' ') AS [ss] WHERE [p].[Id] = 4 |
If your needs are bit more exotic, and you need to split on CHARACTERS WHOSE NAME SHALL NOT BE PRINTED, you can pass in N/CHAR values as well.
|
1 2 3 4 |
SELECT p.[Id], [p].[Body], [ss].[value] FROM [dbo].[Posts] AS [p] CROSS APPLY STRING_SPLIT([p].[Body], CHAR(10)) AS [ss] WHERE [p].[Id] = 4 |
And, of course, you can perform regular Inserts, Updates, and Deletes, with reference to STRING_SPLIT’s value column. Quick example with SELECT…INTO!
|
1 2 3 4 5 |
SELECT p.[Id], [p].[Body], [ss].[value] INTO #temp FROM [dbo].[Posts] AS [p] CROSS APPLY STRING_SPLIT([p].[Body], ' ') AS [ss] WHERE [p].[Id] = 4 |
Using a prior SQL Server version?
Start with Jeff Moden’s function, but when you create it, name it as STRING_SPLIT. That way, when you move your code to SQL Server 2016 & newer, it’ll automatically work as-is, and it’ll even be faster.

52 Comments. Leave new
I’m super curious to see what impact if any this has on tempdb (worktables or otherwise)
This could be used to pass a set of ids to a procedure. Many existing solutions (like shredding xml or table-valued parameters) use tempdb and we’re very sensitive about that.
Hey! Sure, a quick test on my system doesn’t show any tempdb use, but something more robust is probably in order. The below query returns just a hair under 50k rows.
USE [StackOverflow]
SET NOCOUNT ON
SET STATISTICS TIME, IO ON
--SET SHOWPLAN_TEXT OFF --ON
SELECT [p].[Id], [ss].[value]
FROM [dbo].[Posts] AS [p]
CROSS APPLY STRING_SPLIT([p].[Body], ' ') AS [ss]
WHERE [p].[Id] < 1000 /* SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. Table 'Posts'. Scan count 1, logical reads 15, physical reads 0, read-ahead reads 0, lob logical reads 195344, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 171 ms, elapsed time = 281 ms. */ |--Nested Loops(Inner Join, OUTER REFERENCES:([p].[Body])) |--Clustered Index Seek(OBJECT:([StackOverflow].[dbo].[Posts].[PK_Posts] AS [p]), SEEK:([p].[Id] < (1000)) ORDERED FORWARD) |--Table-valued function
Just said “holy cow” outloud in the office; upon explaining myself the other hard core SQL devs understood. The project team however think I am rather odd (or odder than they first thought me to be).
I’m with you!
Just yesterday I was wincing whilst pulling a string to pieces thinking “why am I doing this in what can only be described as the hard way?”
You just made my day. Or you did until I realized it will be another 5-10 years before I can use SQL 2016 features in my software. The life of an ISV. :(.
Just think of all the drinking you can get done until then!
“Holy cow” here, too. Just had an implementation in a product that used Jeff Moden’s method. When we move to 2016, I think we can safely do it this way.
The forgot about very import antyw?amaniowe thing. Splitting string is one character. For this reason useless. Since SQL 2005 we have CLR function with no duch limitations and it is almost 1 line of C# code.
That sounds cool! You should blog about it. Sounds like it would solve a lot of problems for a lot of people.
MS SQL 2016 STRING_SPLIT vs CLR equivalent
https://lnkd.in/ex_dZaK
Nice! Thanks!
The link above has gone to 404 heaven. Do you have a replacement link?
When working with variable length delimiters, I have used REPLACE( source_string, delimiter, CHAR(7)) and then parsed with @delimiter = CHAR(7). This makes the main parsing routine simple by using a single character delimiter instead of variable but does not limit delimiter length. But as far as the CLR routine is concerned, is scales nicely when CLR is allowed.
My problem is when using this for csv lines, I have to write extra code to handle ” qualified text fields.
We also use Jeff’s DelimitedSplit8K stored proc. I was trying to see from documentation if this built in function allows more than 8k string passed in. I think it might.
We are just in the process of migrating to SQL 2014 so will not be using this function in Production anytime soon.
It does! The longest post I can find is 54,790 characters. STRING_SPLIT handled it.
SELECT [p].[Id], [ss].[value]
FROM [dbo].[Posts] AS [p]
CROSS APPLY STRING_SPLIT([p].[Body], ‘ ‘) AS [ss]
WHERE [p].[Id] = 12183063
Table ‘Posts’. Scan count 0, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 168092, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 125 ms, elapsed time = 372 ms.
Why isn’t the implicit conversion a potential performance killer when getting INTs output as NVARCHARs, if they are being used to JOIN to a table using an INT as a key? Wouldn’t that force a scan instead of a seek?
I think you read that backwards. It is a problem.
That joke about DBA’s compiling a .dll was KILLER!
Shiny!
I think XML is an easy way to split strings. Any reason not to use XML?
Special XML characters is the reason. Do You have a solution for this ?
Good point. Just delete them! 😉 Kidding…I’ll have to think about that.
The following code solves the problem with special xml characters, but the time is twice bigger than the CLR solution I mentioned https://lnkd.in/ex_dZaK and 4 times bigger than STRING_SPLIT.
declare @v nvarchar(max)
declare @xml xml = convert(xml,’‘ + replace(convert(nvarchar(max),(select @v for xml path(”))), ‘ ‘,’‘) + ‘‘);
select x.value(‘.’,’nvarchar(max)’)
from @xml.nodes(‘/a’) as S(x)
Yes. Unless you’re splitting XML that has already been formed, then converting something like a CSV to XML and then splitting the XML is painfully slow. Please see the charts, graphs, and code in the following article.
http://www.sqlservercentral.com/articles/Tally+Table/72993/
If you build your own test data, remember that the “Devil’s in the data” on this one and that if you build typical “grooved” data for this one, it will make it look like the XML method edges out the other methods. But, once exposed to real data, which is typically not “grooved” (especially NOT just duplicate rows), then you find that XML loses to things like the DelimitedSplit8K function by miles. In recent testing I’ve done for an upcoming article, the XML method took 8 minutes on just 100K rows of 110 elements each. The DelimitedSplit8K function only took 25 seconds. Of course, as of 2012, you can use a DelimitedSplit8K that rivals even SQLCLR methods because it uses “preceding rows” so that it doesn’t have to use CHARINDEX for every next delimiter.
I am dissapointed. Now we will have even more tables with nvarchar(max) columns oh god why.
Nice article and great explanations, Erik. Rumor has it that they’re working on adding the ordinal position column to the function sometime in the near future. Not sure why they left that out to begin with but sure am glad they’re considering fixing that.
That sure would make things interesting! Did you see STRING_AGG made it to vNext? That’s pretty wild, too. Thanks for stopping by!
Here, You can find STRING_AGG comparison to one of the XML string concatenation methods.
http://www.lyp.pl/blog/sql-vnext-string_agg-vs-xml-string-concatenation/
But think of all the time you’ll save typing 🙂
I rather think about all the CEO’s that don’t call me with the performance problems.
These days there are so many functionalities with XML inside, so that is every day life.
Yeah, I hear you. Hopefully it gets refined a little before it hits prime time.
@Grzegorz ?yp,
You answered my next set of questions with your link. Thanks for posting it. I don’t understand why MS doesn’t (apparently) give a hoot enough to build the correct functionality (order of the concatenation) or to even test for performance against commonly known methods. Heh… look at what they did with the “new” FORMAT function (which is an SQLCLR that calls the .net FORMAT function… makes you seriously wonder about .net, eh?)). It takes 44 times longer than CONVERT does even on a simple YYYYMMDD (ISO Date) format.
Heh… like Erik said though… “think of all the time you’ll save typing “.
I did. Like you say, pretty wild. They’re also (after a decade of being a CONNECT item), reconsidering having a “Tally” (table) generation function. Now, if we could get them to make PIVOT work as well as it does in ACCESS, fix the performance problems with FORMAT, make REINDEX and REORGANIZE and SHRINK more “Peter Norton” like, etc, etc. 😉
Is the fainting couch reinforced yet? … get ready for…………… TRIM!!
Not LTRIM or RTRIM but TRIM – something I have waited for the last 25+ years (yes we are talking 4.0 days)
In your example:
SELECT p.[Id], [p].[Body], [x].[value], x.[RN]
FROM [dbo].[Posts] AS [p]
CROSS APPLY (
SELECT ss.[value],
ROW_NUMBER() OVER (PARTITION BY [p].[Id] ORDER BY [p].[Id]) AS RN
FROM STRING_SPLIT([p].[Body], ‘ ‘) AS [ss]
) AS x
WHERE [p].[Id] = 4
AND x.[RN] = 2
will the order of the returned strings be guaranteed the order of the strings inside the row? I doubt, because the only thing that is told about the order, is the Id of the row…
Ha – just what I was wondering? The docs say “the order is *not* guaranteed to match the order of the substrings in the input string”. Pretty useless, in other words.
(Docs at https://docs.microsoft.com/en-us/sql/t-sql/functions/string-split-transact-sql?view=sql-server-2017)
That’s what I found too, was super excited up to that point
Has anyone been able to get confirmation on the order question?
Is it safe to assume STRING_SPLIT returns rows in the same order as the split text in the original string?
G – there are no guarantees around ordering. If you want data ordered in SQL Server, you need an ORDER BY.
I just used this for the first time in anger (I say anger, it’s more like mild grumpiness re: how other people’s databases store data that I’m expected to analyse *sigh*)
I essentially had to turn three columns containing multiple yes / nos into a table that contained the same columns – but one row of data for each matching index position in the array.
This made it super easy – so thank you!
how do i split if a string DOESN’T contain symbols such as . , etc.
For example, i have PERSON= JohnSnow, how to split it into name=john and surname=snow?
Katarina — For Q&A, head over to https://dba.stackexchange.com
We can’t do personal support in blog comments.
Thanks!
Well. Gosh darn it. Some “fancy-pants super-secret-squirrel-sauce” is EXACTLY what I need right now!
Thank you!
How about JSON to split a string?
DROP FUNCTION IF EXISTS dbo.STRING_SPLIT;
GO
— Returns NVARCHAR(MAX)
CREATE OR ALTER FUNCTION dbo.STRING_SPLIT
(
@Data NVARCHAR(MAX),
@Delimiter NVARCHAR(MAX) = N’,’
)
RETURNS TABLE
RETURN SELECT CAST(x.[Key] AS INT) AS Position,
y.Value
FROM (
VALUES (N'[{“p”:”‘ + REPLACE(@Data, @Delimiter, N'”},{“p”:”‘) + N'”}]’)
) AS d(Data)
CROSS APPLY OPENJSON(d.Data, N’$’) AS x
CROSS APPLY OPENJSON(x.Value, N’$’)
WITH (
Value NVARCHAR(MAX) N’$.p’
) AS y
GO
SELECT *
FROM dbo.STRING_SPLIT(N’Ananas,Banan,Citron’, ‘,’);
GO
— Returns NVARCHAR(4000)
CREATE OR ALTER FUNCTION dbo.STRING_SPLIT
(
@Data NVARCHAR(MAX),
@Delimiter NVARCHAR(MAX) = N’,’
)
RETURNS TABLE
RETURN SELECT CAST(x.[Key] AS INT) AS Position,
JSON_VALUE(x.Value, N’$.p’) AS Value
FROM (
VALUES (N'[{“p”:”‘ + REPLACE(@Data, @Delimiter, N'”},{“p”:”‘) + N'”}]’)
) AS d(Data)
CROSS APPLY OPENJSON(d.Data, N’$’) AS x;
GO
SELECT *
FROM dbo.STRING_SPLIT(N’Ananas,Banan,Citron’, ‘,’);
SELECT * FROM fn_split(‘This is a space-delimited string that I would like to split.’, ‘ ‘);
Mahali – fn_split isn’t built into SQL Server. You (or your predecessor) may have written that.
Like Brent said, that’s not built into SQL Server. I’ll also state that if it uses an rCTE (Recursive CTE), XML, a While Loop, or any form of string concatenation, it’s comparatively woefully slow and resource intensive. If it’s using a CLR, make damned sure that it’s returning what you expect for empty mid-string, leading, and trailing elements because I’ve seen a whole lot of people get it totally wrong. Read the article about DelimitedSplit8k and believe the testing there because it DOES NOT use the same limited, ultra-low cardinality that Aaron Bertran and other’s have made the extreme mistake of using.
From the article:
“And is it faster? Heck yeah, it’s faster, as Aaron Bertrand proved.”
Aaron’s testing is wickedly improper. He used what I call “Grooved Data”. That is, data that is mostly the same and has a very low cardinality, which the XML method favors. If you use random data, his XML method takes about 24 times longer. As with all else, the Devil’s in the Data.
Enough people have made the sorry mistake of using the XML method that I guess I’m going to have to write another article about it even though I completely destroyed the XML method in the first article… which Aaron totally missed. I say totally missed because if he had actually read the full article on DelimitedSplit8K, even he might not have made such an egregious error and then actually have the nads to refuse to due a retest/republish.
Does anyone know of a fast method to parse CSV strings that supports double-quote wrapped items with embedded commas? example string: ‘AAA,”Hello, World!”,BBB’ would produce:
AAA
Hello, World!
BBB
For general questions, head to a Q&A site like https://dba.stackexchange.com.