
Most companies come to us saying, “The SQL Server isn’t fast enough. Help us make it go faster.”
They’re kinda surprised when one of the first things we fill out together is a variation of our High Availability and Disaster Recovery Planning Worksheet:
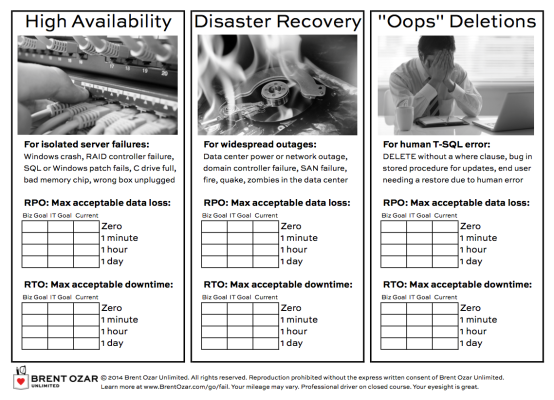
They say things like, “Wait, I’m having a performance problem, not an availability problem.”
But as we start to look at the SQL Server, we often find a few disturbing truths:
- The admins have stopped doing transaction log backups and DBCC CHECKDB because the server can’t handle the performance hit
- Management thinks the database can’t lose any data because communication wasn’t clear between admins and managers
- The server isn’t even remotely fast enough to start handling data protection, let alone the end user query requirements
I know you think I’m making this up. I know you find this hard to believe, dear reader, but not everyone is a diligent DBA like you. Not everyone has their RPO and RTO goals in writing, tests their restores, and patches their SQL Server to prevent known corruption bugs. I hope you’re sitting down when you read this, but there are some database administrators out there who, when given the choice between index rebuilds and transaction log backups, will choose the former on a mission-critical 24/7 system.
I’m sure that would never be you, dear reader, but these database administrators are out there, and they’re exactly the kinds of shops who end up calling us for help.
Then the fun part is that once we establish what the business really wants in terms of data safety, it often dictates a new server – say, moving from a single standalone VM with no HA/DR up to a full-blown failover cluster. And in the process of sketching out that new cluster, we can solve the performance problems at the same time without any changes to their application. (Throwing hardware isn’t the right answer all the time – but when you need to add automatic failover protection, it’s the only answer.)
That’s why we start our SQL Critical Care® by talking about what the business needs and what the system is really delivering, and get everyone on the same page as to what needs to happen next.

7 Comments. Leave new
I think your consulting concept is awesome. It’s all coming together now.
Tobi – thanks sir!
Zombies in the data center?! Good thing we install high-power cross-bows at every fire extinguisher station. You can never be too safe with events like that. Fires, quakes, tornadoes with flying houses (and sometimes cows) in it…piece of cake! But Zombies, now what we consider a true disaster.
If we have zombies in the Data Center, is anyone really going to care that the servers are down? The CDC will have the whole city on lock down anyway.
David – but the CDC has databases too. True story – I’ve met one. Coolest business card I’ve ever seen.
Have you seen todays’ youth and their addiction to their “Connection?” They could be getting eaten by a zombie and still complain about slow response speeds due to database performance is affecting their social media browsing. I mean, it’s IMPORTANT to get a selfie with the zombie before they bleed out!!!
(On a side note, I literally have a “Support Zombies” magnet on the trunk of my car.)
Always a pleasure to read you Brent !
SO instructive while being brief , thanks for the 1rst Kit Responder.