
Hooray Windowing Functions
They do stuff that used to be hard to do, or took weird self-joins or correlated sub-queries with triangular joins to accomplish. That’s when there’s a standalone inequality predicate, usually for getting a running total.
With Windowing Functions, a lot of the code complexity and inefficiency is taken out of the picture, but they still work better if you feed them some useful indexes.
What kind of index works best?
In general, what’s been termed a POC Index by Itzik Ben-Gan and documented to some extent here.
POC stands for Partition, Order, Covering. When you look at your code, you want to first index any columns you’re partitioning on, then any columns you’re ordering by, and then cover (with an INCLUDE) any other columns you’re calling in the query.
Note that this is the optimal indexing strategy for Windowing Functions, and not necessarily for the query as a whole. Supporting other operations may lead you to design indexes differently, and that’s fine.
Everyone loves a demo
Here’s a quick example with a little extra something extra for the indexing witches and warlocks out there. I’m using the Stack Exchange database, which you can find out how to make your favorite new test database here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SET NOCOUNT ON SET STATISTICS IO, TIME ON; SELECT p.OwnerUserId, p.CreationDate, SUM(p.ViewCount) OVER ( PARTITION BY p.OwnerUserId ORDER BY p.CreationDate ) AS TotalViews FROM dbo.Posts AS p WHERE p.PostTypeId = 1 AND p.Score > 0 AND p.OwnerUserId = 4653 ORDER BY p.CreationDate OPTION ( RECOMPILE ); /* Table 'Posts'. Scan count 5, logical reads 488907, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1180, logical reads 7095, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 2328 ms, elapsed time = 760 ms. */ |
The query above is running on the Posts table which only has a Clustered Index on the Id column, that does us absolutely no good here. There are tons of access operations and logical reads. Taking a look at the plan doesn’t offer much:

Let’s try a POC index to fix this up. I’m keeping ViewCount in the key because we’re aggregating on it. You can sometimes get away with just using it as an INCLUDE column instead.
|
1 2 |
CREATE NONCLUSTERED INDEX IX_POC_DEMO ON dbo.Posts ( OwnerUserId, CreationDate, ViewCount ); |
We can note with a tone of obvious and ominous foreshadowing that creating this index on the entire table takes about 15 seconds. Insert culturally appropriate scary sound effects here.
Here’s what the plan looks like running the query again:
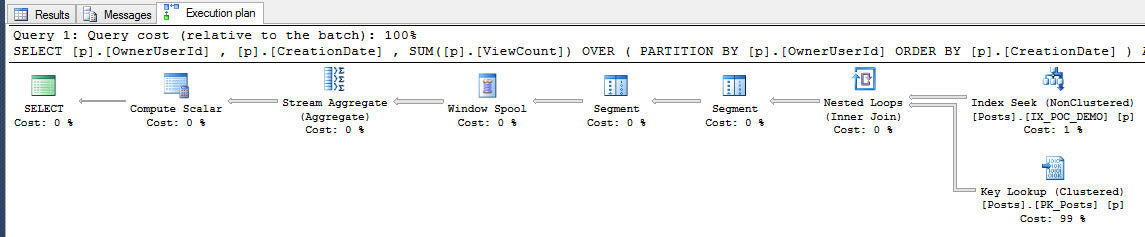
That key lookup is annoying.

We did a good job of reducing a lot of the ickiness from before:
|
1 2 3 4 5 6 7 |
/* Table 'Worktable'. Scan count 1180, logical reads 7095, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Posts'. Scan count 1, logical reads 4973, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 31 ms, elapsed time = 168 ms. */ |
But we’re not happy. Why? Because we’re DBAs. Or developers. Or we just have to use computers, which are the worst things ever invented.
Behold the filtered index
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_POC_DEMO ON dbo.Posts ( OwnerUserId, CreationDate, ViewCount ); WHERE [PostTypeId] = 1 AND [Score] > 0 WITH (DROP_EXISTING = ON) |
Cool. This index only takes about three seconds to create. Marinate on that.
This query is so important and predictable that we can roll this out for it. How does it look now?

That key lookup is still there, and now 100% of the estimated magickal query dust cost. For those keeping track at home, this is the entirely new missing index SQL Server thinks will fix your relationship with your dad:
|
1 2 3 4 5 6 7 8 |
/* USE [StackOverflow] GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts] ([OwnerUserId],[PostTypeId],[Score]) INCLUDE ([CreationDate],[ViewCount]) GO */ |
But we took a nice chunk out of the IO and knocked a little more off the CPU, again.
|
1 2 3 4 5 6 7 |
/* Table 'Worktable'. Scan count 1180, logical reads 7102, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Posts'. Scan count 1, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 91 ms. */ |
What can we do here?
Include!
|
1 2 3 4 5 6 |
CREATE NONCLUSTERED INDEX IX_POC_DEMO ON dbo.Posts ( OwnerUserId, CreationDate, ViewCount ) INCLUDE ( PostTypeId, Score ) WHERE PostTypeId = 1 AND Score > 0 WITH ( DROP_EXISTING = ON ); |
Running the query one last time, we finally get rid of that stinky lookup:

And we’re still at the same place for IO:
|
1 2 3 4 5 6 7 |
/* Table 'Worktable'. Scan count 1180, logical reads 7102, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Posts'. Scan count 1, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 90 ms. */ |
What did we learn? Windowing functions are really powerful T-SQL tools, but you still need to be hip to indexing to get the most out of them.
Check out our free resources on Windowing Functions here.
If you like this sort of thing, you might be interested in our Advanced Querying & Indexing class this August in Portland, OR.
Jeff Moden talks at length about triangular joins here (registration required).

6 Comments. Leave new
That last optimization looks like an optimizer bug. The INCLUDE ([PostTypeId], [Score]) should not be necessary because the predicate is satisfied by the index filter. Maybe worth trying with TF4199.
It looks like this was logged as a bug last week in Covering index produce a Lookup when it should not. Until the bug is addressed, it’s going to be best to use the
INCLUDEin the index. And, if you feel strongly that Microsoft should spend dev cycles on that bug, you should up vote it.Nice post…totally digging your writing style.
Can you explain why it matters, if I append the ORDER BY to the SUM function (mathematical it’s nonsens (1 + 2 + 3 is equal to 3 + 2 + 1) but without it SQL Server makes some costly table spools)
The SUM() function uses the default ROWS UNBOUNDED PRECEDING, which means that the results will actually change based on the ORDER BY clause. In this case, the query is creating a running total of view counts by creation date.
Really interesting post. I do love some windowing functions knowledge!