
SQL Server 2016 adds Availability Groups in Standard Edition. While the licensing details can obviously change right up to release date, here’s what was announced at the Ignite conference:
- Limited to two nodes only (a primary and a secondary)
- Like mirroring, you can’t read from the secondary, nor take backups of it
- But like database mirroring, you can take snapshots of the secondary for a static reporting copy
- Each database is in its own Availability Group
In CTP2, this is referred to as a Basic Availability Group.
Yes, a BAG. I can’t make this stuff up people. But here’s what I can make up:
- If you use HammerDB for load testing of a BAG, that’s a BAG of Hammers
- If you have ten databases, each in its own BAG, that’s a Dime BAG
- It could be worse – it could be a Database Basic Availability Group, or a D-BAG
Enough laughing – let’s implement it. For this scenario, I’m already in production with one SQL Server 2016 machine, and I’d like to add a second one to give me some high availability or disaster recovery protection.
I’m setting up a simple AG with two standalone machines:
- SQL2016A – this will be my primary instance where my databases will normally run.
- SQL2016B – this will be my secondary, with less horsepower. Could be in the same data center, or in a different one. (To keep things simple for this explanation, I’m going to stick with the same data center and the same IP subnets.)
This checklist will focus on the Availability Groups portion, not the SQL Server installation, so go ahead and set up your second SQL Server using our SQL Server Setup Checklist. Make sure the second one uses the same user database data/log drive letters and paths as your primary server. If you use different paths, then whenever you add a data or log file to an existing database, it will succeed on the primary but then fail on the replica where the drive letters are different. (Only the user database paths have to match – not TempDB, system databases, binaries, etc.)
In theory, you might be able to do this in production without a major outage.
In practice, I wouldn’t bother trying – you’re probably behind on Windows Updates, and you need to apply these prerequisite Windows patches. Because of that, I’d schedule a separate (long) maintenance window to get up to speed on Windows patches, the latest SQL Server updates, and do the first few steps. Even when you rehearse it in a lab, it’s not unusual to run into several restarts-and-check-again-for-updates in the wild, or brief outages to
Let’s get started!
ADD THE CLUSTERING FEATURE TO BOTH WINDOWS SERVERS.
“But wait, Brent – I don’t want to build a cluster!” Unfortunately, SQL Server’s AlwaysOn Availability Groups is built atop Windows Failover Clustering Services, and you have to join your AG replicas into a single Windows cluster.
Fear not – this is nowhere near as scary as it sounds, and it can be done after-the-fact to an already-in-production SQL Server. (I’d recommend you set up a lab or staging environment first to get used to it, though.)
After installing those clustering prerequisites, open Server Manager and click Manage, Add Roles and Features, select your server, and on the Features list, check the Failover Clustering box:

You can move on to the next step after this feature has been installed on all of the servers that will be involved in the Availability Group.
Validate your cluster candidates.
Open Server Manager and click Tools, Failover Cluster Manager. (I know – you thought Failover Cluster Manager would be under Manage instead of Tools, but it’s these clever switcheroos that keep us all employed as IT professionals.) Click Validate Configuration on the right hand side to start the wizard:
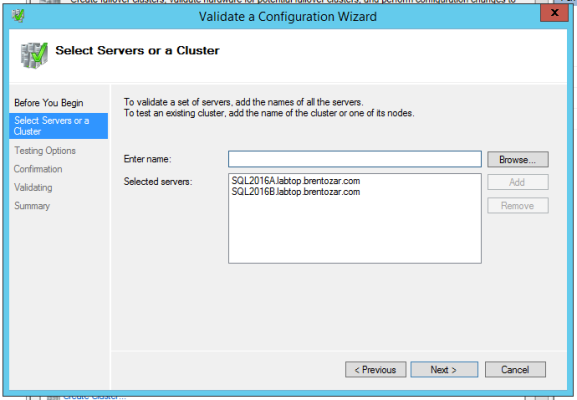
Put in the names of all the servers that will be participating in the Availability Group, and hit Next. It’s going to ask if you want to run all tests – this is another one of those gotchas where, in theory, you could do this in production without an outage if you chose to run specific tests. I don’t recommend that – just run all tests. If SQL Server is running on any of these nodes, it’ll likely stop while this wizard runs, so do this during a maintenance window.
The validation wizard can take several minutes depending on the number of replicas, environment complexity, and phase of the moon.
Your cluster will probably fail, and that’s okay. This isn’t like school. Nobody has to know if you fail several times. (Chemistry was hard for all of us.) Even if you think you passed, you probably failed a portion of it. (The wizard, not chemistry.)
Click the View Report button, and Internet Explorer will launch because why wouldn’t we take every opportunity to open a browser on a production server:

You’ll be tempted to scroll down through it because that’s how most web pages work. This is not most web pages. Click on the first error – in my case, Network – and then click on the first warning it takes you to – in my case, Validate Network Communication – and then read the warnings in yellow:
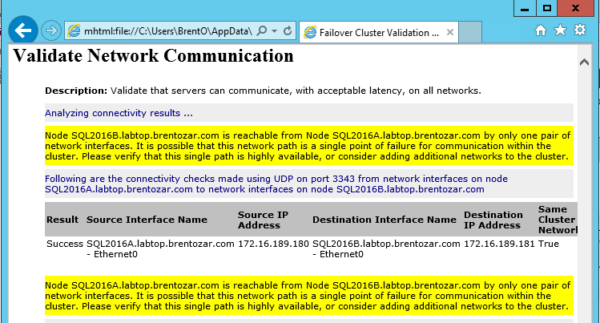
This is where things get a little weird.
Some errors are completely okay to ignore. The most common two are:
- Single network interface warnings – if you’re doing network teaming or virtualization, you’re probably protecting your network through means that the clustering wizard can’t detect.
- No disks found for cluster validation – if you’re building an AlwaysOn configuration with no shared disk, like failover clustering on a UNC path or a pair of Availability Group replicas with local disk, this isn’t a problem.
But otherwise, read this report really carefully and fix the warnings before you go on to the next step. For example, if the two nodes have different Windows patch levels, get the missing updates installed first. (If you’re having difficulty getting some of the patches to apply, there’s your first sign that this isn’t a good candidate for a reliable AlwaysOn implementation – more like OftenOn, or OffAndOn.)
After you fix the issues, run the validation wizard again. This is important because the last validation report is saved in Failover Cluster Manager, and you always want that report to look good. When you call Microsoft (or a team of highly skilled consultants) for Availability Groups help, they’re going to start by looking at this validation report, and if it didn’t pass last time, that’s going to be a bad start.
Create the Cluster.
After a successful validation report, leave the “Create the cluster now” checkbox checked, and click Finish – your cluster will be created:
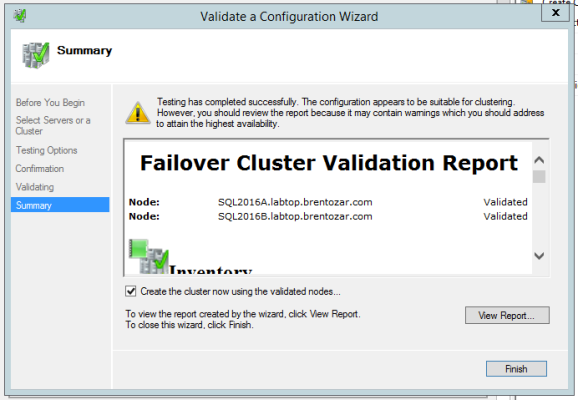
This checkbox is particularly diabolical – it will be checked by default as long as you didn’t have any heinously ugly showstopper errors, but even with mildly serious errors, it will still let you create the cluster. Make sure you fix the errors first.
You will be prompted for a cluster name – again, a little diabolical here, because this is not how you will address SQL Server. This name is how you will control the cluster itself:
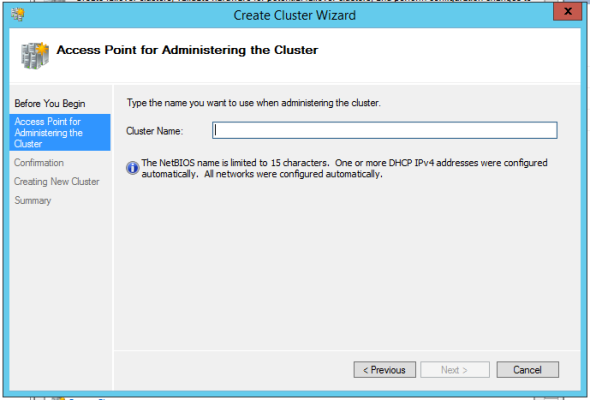
Think of your cluster like a kitchen – a restaurant can have lots of cooks, but it will have only one head chef. Your head chef knows who’s doing what at all times, and bosses people around. The head chef never actually cooks anything – he just tells other people what to do.
Your cluster can have lots of SQL Server instances in it, and they can have lots of Availability Groups. We need one controller to know what’s going on, and that’s the cluster name.
In my case, I’m using SQL2016CLUSTER. You’ll notice that in my screenshot, it says “One or more DHCP IPv4 addresses were configured automatically” – don’t do that in your production environment. Use static IP addresses. You always want to know where the head chef is.
The next screen will prompt you to add all eligible storage to the cluster – uncheck that unless you’re building an AlwaysOn Failover Clustered Instance.
In a perfect world, the wizard finishes, your cluster is completed successfully, and your Failover Cluster Manager looks something like this:
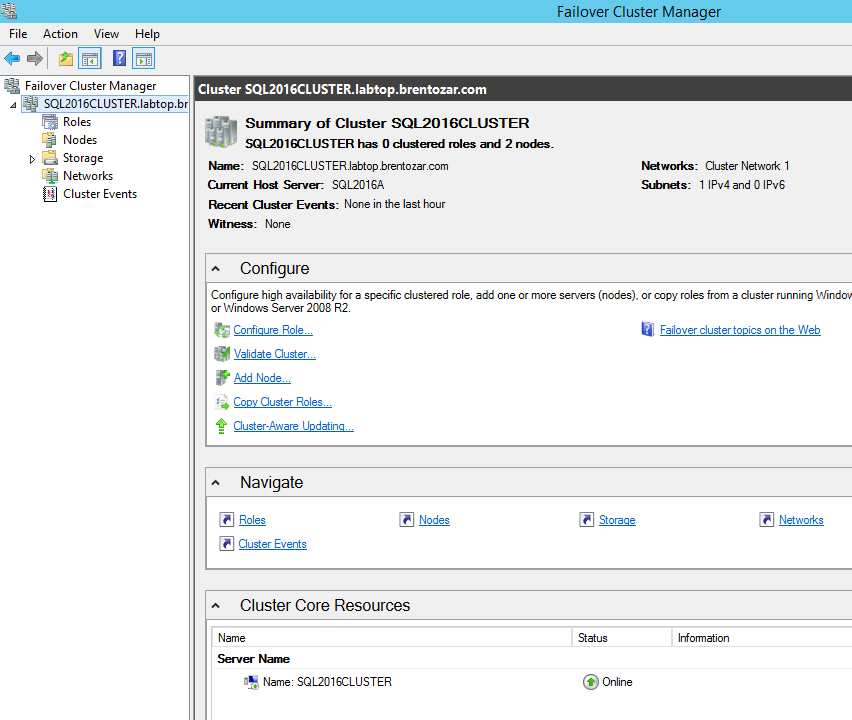
Pay particular attention to the “Witness: None” line. Just like any good preacher, your cluster needs a witness, so right-click on the cluster name on the left side of the screen, click More Actions, and Configure Cluster Quorum Settings. In the next wizard, choose “Select the quorum witness” and choose either a disk (shared drive) or file share (UNC path) witness.
For my simple two-server configuration, I need a really reliable tiebreaker, so I’m going with a file share witness. I need it hosted on my most reliable server possible – in my simple lab, that’s one of my domain controllers, so I type in the server name and then click the Show Shared Folders button:
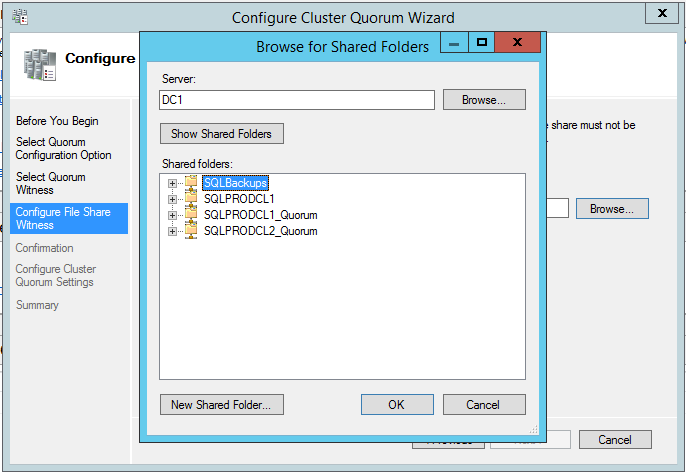
Click the New Shared Folder button, configure your file share, and exit the wizard. What I just did there is right for my lab, but only my lab – you’ll want to make some better-informed decisions in your production environment. For example, if all of my SQL Servers lived on virtual machines backed by NetApp storage, I’d probably use a file share right on the NetApp itself, because if that thing goes down, all my SQL Servers are hosed anyway.
Enable AlwaysOn Availability Groups on Each Server
On each replica, launch SQL Server Configuration Manager, then go into SQL Server Services, right-click on the SQL Server service, and click Properties.
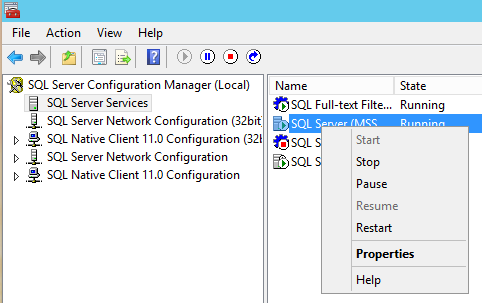
On the AlwaysOn High Availability tab, check the box to Enable, and click OK. This won’t take effect until the SQL Server service is restarted. Repeat this on all of the SQL Servers.
Now let’s take a moment to reflect: we’ve got a pair of Windows servers that are in the same cluster, but at this point, there are no dependencies between the SQL Server services running. They can be hosting different databases, doing log shipping or mirroring between them, or have absolutely nothing in common. If you’re planning your first AG in production, the work done up to this point is a good amount of work to tackle in one maintenance window. I would schedule all of this for the first outage, and then let things simmer down for the next week or two before assembling the Availability Group components.
Create the Availability Group
Whew! We’re finally done with the Windows portion of setup. Let’s fire up SQL Server Management Studio and have some fun.
On my SQL Server, I have a copy of the StackOverflow.com database that I want to copy over to my secondary replica. It’s already in full recovery mode, and I’ve been taking full backups, so it already meets the lengthy AlwaysOn Availability Group prerequisites.
In Object Explorer, right-click on AlwaysOn High Availability and click New Availability Group Wizard. Starting in SQL Server 2016, we’ve got a few new options:
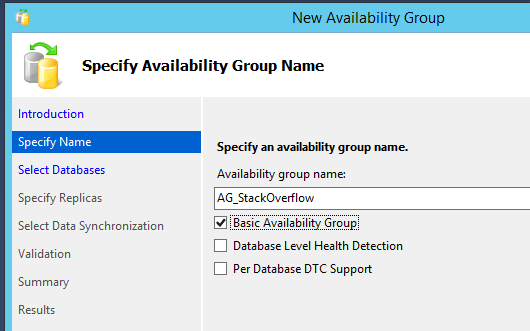
As of this writing, the AG documentation hasn’t caught up with the product yet, so here’s an explanation of each option:
Basic Availability Group – terminology can always change leading up to release, but as of CTP2, this functionality is called a Basic AG. I would just like to take another second to point out that the acronym is BAG.
Database Level Health Detection – in Super Availability Groups (as opposed to Basic – look, if they can make up stupid acronyms, so can I) with multiple databases, the SAG doesn’t drop if one database happens to go offline, become corrupt, or take the day off. New in SQL Server 2016 is the ability to force that failover if any one database goes down, so the SAG stays up.
Per Database DTC Support – The Distributed Transaction Coordinator (DTC) enables simultaneous commits across multiple SQL Servers hosted on different hardware. Prior to SQL Server 2016, AG databases didn’t support DTC participation, but now, just check this box.*
* – You’ll probably have to do more than that, but hey, the infrastructure is here.
Since we’re doing Standard Edition, we’ll just check the Basic Availability Group box and move on. Check the box to pick which database you want in your BAG, and then it’s time for replica selections. On this screen, click the Add Replica button and connect to your new soon-to-be secondary:
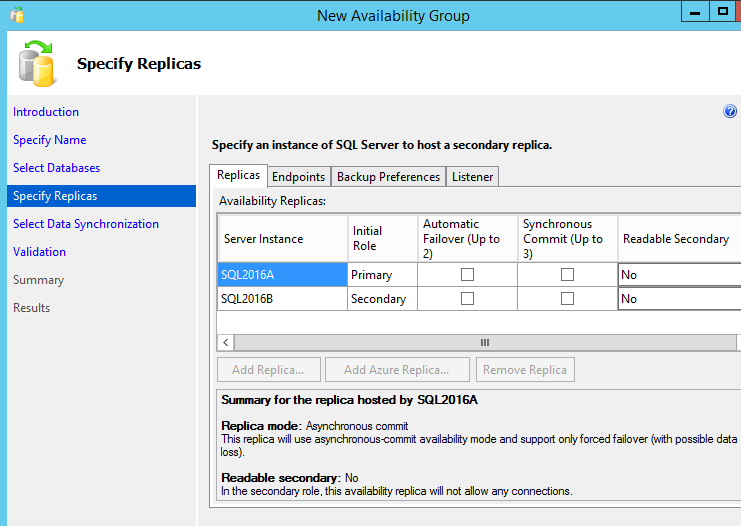
Here’s what the choices mean, and I’m going to explain them a little out of order:
Synchronous Commit – say SQL2016A is the primary, and a user does a delete/update/insert there. If I check the Synchronous Commit boxes for SQL2016A and SQL2016B, then SQL2016A will write the user’s transaction locally, send the transaction over the network to SQL2016B, write it to disk there, and then wait for confirmation back before telling the user that the transaction is committed. (Most of the time. If SQL2016B drops offline, that’s another story.)
If I don’t check the Synchronous Commit boxes, then I get asynchronous transactions – the SQL2016A primary transaction will succeed right away, and SQL2016A just sends the transactions over to SQL2016B later. SQL2016B can be seconds (or minutes, or hours) behind, so I’ll lose data on failover, but the primary’s transactions won’t be subject to that killer latency.
Automatic Failover – if the Synchronous Commit boxes are checked, then you can do automatic failover between two of the replicas. (This is where the cluster witness starts to come into play – in my two-node setup, SQL Server needs a tiebreaker to know the difference between single node failures and a split-brain scenario.)
For my evil purposes, I only need a disaster recovery copy of my databases, and I don’t want to fail over to DR if my primary just happens to restart or hiccup. I’m going to leave the Automatic Failover and Synchronous Commit boxes unchecked.
Readable Secondary – in Super Availability Groups, you can offload reads and backups to your secondaries. Since I’m dealing with a BAG here, the Readable Secondary dropdown only offers the “No” option.
The tabs for Endpoints, Backup Preferences, and Listener don’t really matter here. SQL Server automatically creates the endpoints for you, and you can’t offload backups or create a listener for BAGs.
The next step in the wizard syncs the data between replicas:
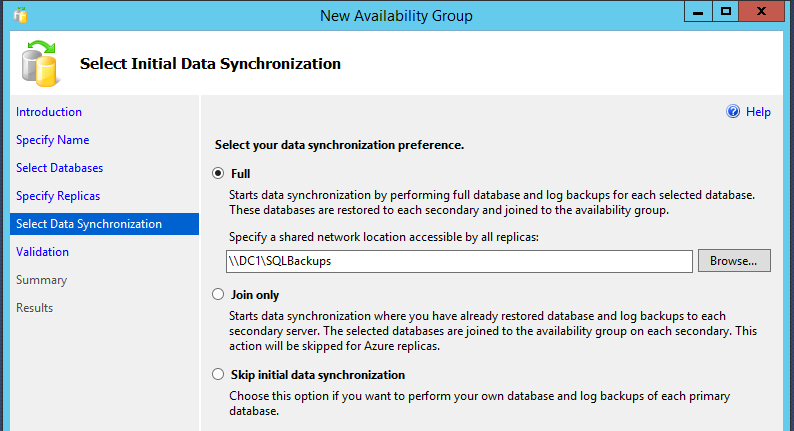
The Full option performs one full and one transaction log backup on the primary, then restores them over to the secondary to start the replication. (Keep in mind that if your databases are large, you’ll want to set database backup compression on by default in order to speed this process – you don’t get to choose compression settings in the wizard.)
The other two options are useful if you performed the backups yourself manually, or if you’re using storage replication technologies to get it started.
If you choose the Full option, you can track backup and restore status with sp_WhoIsActive’s percent-completed column.
After the AG wizard finishes, you can right-click on your Availability Group in Object Explorer and click Show Dashboard:
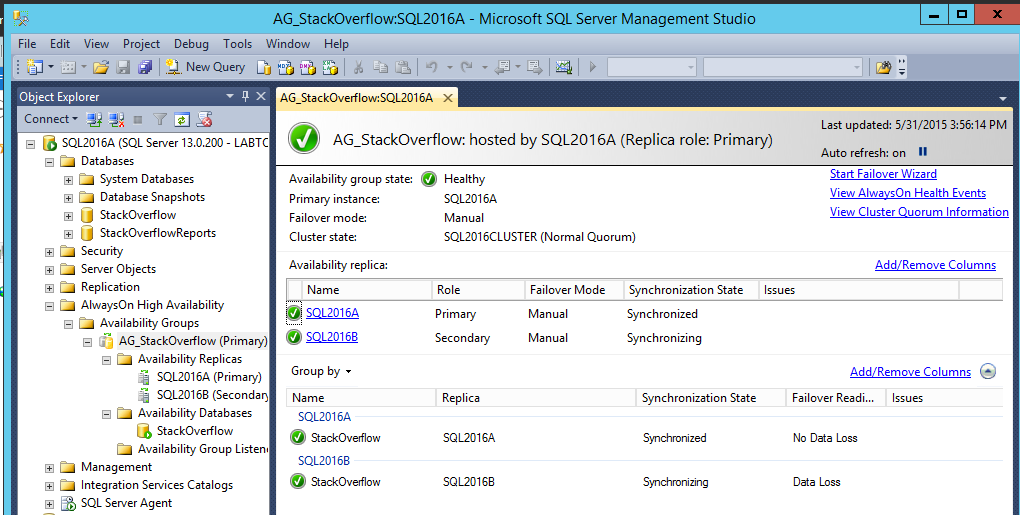
Voila! Papa’s got a brand new BAG.
Want help? Talk to Brent for free.

The problem probably isn’t fragmentation – you keep defragmenting and the problems keep coming back.
Our 3-day SQL Critical Care® is a quick, easy process that gets to the root cause of your database health and performance pains.
Learn more, see sample deliverables, and book a free 30-minute call with Brent.

191 Comments. Leave new
That’s awesome, but BOL [incorrectly] states only 2 nodes “Alwayson Failover Cluster Instances” are allowed in Standard edition.
“AlwaysOn Availability Groups” still says only Enterprise edition.
https://msdn.microsoft.com/en-us/library/cc645993(v=sql.130).aspx
BOL is wrong? (not the very first time for sure) because your 2 instances are stand alone…
cheers
Raul – yep, none of the Books Online information reflects 2016 licensing yet.
Not that 2 nodes cluster is incorrect 🙂 the other bit…
Hopefully they won’t “forget” that bit to be updated.
Cheers
Hi Brent, I am a MSSQL DBA and I want to understand, why Microsoft changes mssql server versions so quickly?? I want to pass certification exam for sql server 2012, but now I think should I or not??
MIK – take the test that covers the version you’re using. If you’re using SQL Server 2012 every day, then take that test.
Also from May 2014 (if I remember correctly) you have SQL 2014 Questions in your SQL 2012 exams.
That’s pretty confusing, I know.. but you will get them, so do study all new features from 2014 to pass your exams on 2012
You will get SQL Server 2014 questions in the MCSE exam. The MCSA exams still have only SQL 2012 questions.
Firstly, about the exam… Take it… It’s fun…
Secondly, and more important… Why they have a release cucle that feels like every second, third year. It’s basically due to the simple reason that they want us to have as much awesome as fast as possible…
Thank you for quick answer, but as a professional what is your opinion ?
from my point of view it was great to put all features from 2012,2014 and 2016 versions in one version.
Mik – my opinion is exactly what I gave you. Certifications measure what you know. If you don’t have a certification yet, start with the test that measures the version you’re using.
If you’re not using SQL Server, don’t get a certification on it.
I Wonder what the differences are between Basic and “Super” Availability Groups. I installed a cluster with 2 Enterprise editions of SQL Server 2016. So, If I choose Basic Availability Group, I guess there will be a limit on replicas, even though it is Enterprise edition.
Flemming – yeah, for this post, I’m using the Evaluation Edition preview (which is basically the same as Enterprise) and it’s enforcing the limits when I put my database in a BAG.
So, in theory, since the BAG isn’t a readable secondary, you wouldn’t have to license it if you had Software Assurance? Just trying to interpret based on your previous post https://www.brentozar.com/archive/2015/04/microsoft-sql-server-licensing-simplified-into-7-rules/
(Obviously pending final licensing details for 2016, and the fact that only MS licensing reps could give a final answer)
Wyatt – if SQL 2016 follows the same rules as SQL 2014, then you’ll need Software Assurance on your primary, and that will give you exactly one free secondary.
Hi Brent,
You mentioned here one AG Group per Database, what is with Availability Group Listener? Do we need one per Database then? That would mean one IP for every Database, correct?
Thank you
Struchnjak – I’ve carefully hidden the answer to your question in the post.
Right 🙂
There are none… noone to listen…
Pity, I would need Enterprise Edition then.
Thank you for clarification!
Perhaps I’m not quite awake yet but one the purposes of an AG is to failover so an AG needs a dns/ip listener that can operates on both nodes?.
Evert – that is one of the features of an AG, yes, along with things like running reports on your secondaries. This is a Basic Availability Group, and as you might deduce from the name, it may have less features than an Availability Group. Enjoy your coffee. 😉
Haha, I’m wide awake now.
Nice post! In other news, I did legitimately name an AG using the following convention: __DB_AG… Totally wasn’t thinking about it – the underscore was making those separate words in my mind. Oopsies…
Brent, I believe “BAGs” is simply the new name for Database Mirroring in SQL Server 2016, is that correct?
Is there *any* difference between Database Mirroring and BAG? Thanks very much in advance for your clarification.
Eddie – no, BAGs is Availability Groups. Database mirroring is totally different – it doesn’t rely on clustering.
In that case, can you give me one feature that a BAG has which a Database Mirror does not?
I was aware that Microsoft was planning to retire Database Mirroring. My assumption was that BAGs were the next-generation Database Mirror (more or less). Thanks again!
Eddie – sure, that answer is simple: the one feature BAGs have is that BAGs aren’t deprecated.
So if Kendra starts performing regular consulting re: Basic AGs, she’ll be the BAG La… nev mind, too easy.
Database Mirroring has the ability to run with certificates. Is there something similar for standalone servers (no Domain) with regard to BAG?
Robin – that would be an interesting feature request. Are you in a situation where you’re using mirroring without a domain? I’d like to hear more about that.
Yes. The instances and application it is supporting is running on top of SQL 2005 and realistically will not be upgraded to SQL 2016 (or 2012 for that matter).
I am just wondering if this type of configuration will be available.
If AGs are still leveraging mirroring TDS endpoints for their connections to other instances under the hood, I feel like you should be able to use certificates for encrypting the endpoints. Shootin’ from the hip like a real maverick on that one, so feel free to respond with raucous laughter if I’m incorrect.
Jerrod – that’s only the communication between the two, not things like determining which node is online.
Oh yeah, lol. Forgetful me – that whole WSFC thang that, you know…it’s built on.
I got this working using
– BAG with Certificates
– iSCSI for storage
– SQL Server 2016 CTP 3.2
– Windows Server Technical Preview 4
– An Active Directory-Detached Cluster
http://www.smooth1.co.uk/installs/dbinstalls.html#3.1.18
Lots of other items in that document
– FCI with Multi-subnet and multipath iSCSI mutipath storage
– Cluster Shared Volumes as storage, again Multi-subnet and multipath iSCSI mutipath storage
– Windows Server 2016 TP4 Storage Replica as storage,Multi-subnet and multipath iSCSI mutipath storage, this is incomplete as failover needs node 1 to be up.
Woohoo! That’s awesome, glad to see it’s moving forward.
If the zombie hordes arrive you might need to set up the DR with a BUG OUT BAG http://en.wikipedia.org/wiki/Bug-out_bag
The new Azure version of this is called “Microsoft Azure Node Basic Availability Groups” or as we like to call it MAN BAG
An additional backwards compatibility mode that supports named pipes is referred to as the “BAG PIPE”
This is too easy. 100 points for the James Brown finish
“But like database mirroring, you can take snapshots of the secondary for a static reporting copy”
Can I just check – if you took a snapshot of the read-only secondary to run reports off it, would that breach the license for the warm standby server that you get with Software Assurance?
Greg – let’s do a thought exercise for a moment. If you’re running queries against a server, is it a standby?
That was my thought, and then the wishful thinking part of my brain kicked into gear. Thanks for sending me crashing back to reality.
>>>But like database mirroring, you can take snapshots of the secondary for a static reporting copy
Does this mean that snapshots are also coming to standard edition?
That would appear to indicate that, yes, but keep in mind that licensing can change right up til release day. (It could mean that snapshots are only available with BAGs, or that snapshots are only available when the BAG replica is Enterprise Edition.)
I have been told that the SQL Server 2012 AlwaysOn implementation are limited to 1 core when it comes to replica-synchronization and it has an upper limit of 50 Mb/s in transfer speed. Do you know of any improvements in this area?
Flemming – I haven’t done load testing on 2016 AGs yet, but that transfer speed limit sounds a little fishy to me. (I’ve seen higher than that.) Who told you that?
A storage/SQL Server consultant advised us on the differences between AlwaysOn FCI and AlwaysOn AG. He mentioned the limit of 1 core and ca. 50 Mb/s throughput. It may not be a problem in my Company(Insurance), but for banking/stock applications it might create congestion in synchronous replicas.
And the consultant’s name?
SQL16 comes with some powerful enhancements in the synchronization stack of Availability Groups (parallel compression, a much faster compression algorithm, parallel redo, and a streamlined communication protocol).
Some of these are already there in CTP3, and some will come in RC0.
All this talk of BAGs and even MAN BAGs is certainly paving the way for deprecated mirroring to be removed from the product.
Richard – yeah, that’s my thought too. From a resources and patching perspective, Microsoft needs to stick a fork in mirroring, and BAGs would be the feature that lets it happen.
We have a server with lots of small db’s. Is there a limit to the number of BAG’s that can be set up?
( since its 1 BAG per db…)
Just like with mirroring and normal AGs (NAGs?), there going to be thread and CPU overhead for each AG, so there’s going to be limits you hit for performance reasons even if there aren’t licensed limits. I don’t believe the full licensing details on how many are allowed has been published yet, though.
Thanks!
BAG …. is database mirroring with lipstick on it !!!!!!!!!!!!!!!
If that ugly set of steps is lipstick… Just give us old fashioned mirroring…
Can I say… What a mess?
Performance based mirroring is fast to set up, and gives the dr most of us need.
Why can’t we just set up an old fashioned mirror in std edition, the quick way?
Looking at those steps, I don’t think I would ever do them on a prod system ever.
Sam,
Keep in mind that unless your company gets right on the ball and switches to 2016 you will still be able to use standard mirroring in 2012 and 2014. It was marked for death as of 2012 which usually means that after two major releases it is removed.
Jeremie,
You are %100 correct.
But that is not my point.
My point is: What an absolute mess of complexity to set up a single, RO mirror off site.
My point is: Performance based mirroing was set up %100 within SQL (no Windows, AD or OS impact), and takes just a few commands.
Other databases (Oracle, Mongodb, etc etc) allow simple, three to ten command mirror setup.
SQL AO is really nice “on paper.” But setup sequences like this are simply not OK. A single mirror should be easy.
I feel that MS has severely dropped the ball here. Setup is crazy complex. Troubleshooting would appear… intimidating.
Wicked Job BRENT loud clapping!!!
Thanks sir!
Good writeup. I do have one question that I can’t seem to find the answer for. Do the servers participating in an AG group need to have a secondary NIC configure for heartbeat since they are ultimately nodes in a Windows cluster group? I’m not talking about the nodes themselves being part of a SQL FCI instance.
Erick – well, good news there – we already have a blog post on it! Don’t be disheartened by the title though: https://www.brentozar.com/archive/2012/06/everything-know-about-clustering-wrong/
I’m still a little confused. So I’m guessing a heartbeat isn’t needed, especially if my secondary replica is at a WAN site with different networks?
Erick – yep, make sure you *read* the posts linked to in that one. You’re gonna have to roll up your sleeves and read the manual.
What was missing from your excellent blog post here – https://www.brentozar.com/archive/2011/07/how-set-up-sql-server-denali-availability-groups/ – was the network configuration for SQL2012PROD1 and SQL2012DR1. Would there be a separate heartbeat interface defined between them?
Erick – time to take a deep breath, maybe a walk and some coffee, and READ THE LINKS THAT I GAVE YOU.
The setup for every cluster can be different. Read the manual. Full stop. Please don’t model your production infrastructure after a pair of VMs I built for a demo.
Sorry Brent, none of the links you gave me give me the information I need. I’ve been running SQL active/passive instances for a long time now and am adding two secondary replicas via availability groups, one of them being at our DR site. So while I do have a separate heartbeat NIC defined for my active/passive instance, I still don’t know if my secondary replica at my DR site needs a heartbeat NIC to participate in an availability group.
Erick – OK, if you’re not going to read https://blogs.technet.com/b/askcore/archive/2010/02/12/windows-server-2008-failover-clusters-networking-part-1.aspx?Redirected=true then there’s really nothing I can do for you. I wish you the best of luck in your deployments.
Ah. I totally skipped that because I’m running SQL 2014 on Windows Server 2012 R2 which has improved cluster services. Sorry for your troubles.
So I’ve thought long and hard about this and am not trying to sound snarkey, but why. I don’t see a use case for only 2 nodes (unless I’m missing something which is totally possible). I get that it’s a high availability solution, but if set up in prod you’d have the choice of 2 nodes in your “prod env” with the ability to switch active to do windows patching, OR 1 node in prod and 1 in dr. In which case you’d need to fail over to do patching.
Why not do 2 2 node failover clusters with logshipping?
John – because not everyone needs 4 SQL Servers.
Could we use SSIS bulkinsert master server , if not, how to do it ?
Wei – this blog post doesn’t have anything to do with your question. Try going to a Q&A site like http://dba.stackexchange.com.
I see the Microsoft 2016 Feature Lists still says Database Snapshots are in Enterprise Edition only. It looks like the developers and the marketing team are not talking to each other.
https://msdn.microsoft.com/en-us/library/cc645993.aspx#High_availability
we are going to use sql server 2012 in one of our customer location and require to setup a high availability. i have the following questions
1) Both primary and replica server should have enterprise edition or only primary server having enterprise edition and other editions can have standard edition?
2) Microsoft document says that each availability group can have 8 replica server, suppose if i need more than 8 replicas then i have to create availability group?
3)we are going to use alwayson feature redundancy purpose, suppose primary server goes down then application need to connect to secondary server, how data will sync from secondary server to primary server if there is no alwayson group not available in secondary server?
Ananth – this blog post is about SQL Server 2016. If you’ve got questions about something completely unrelated to the blog post you’re reading, your best bet is to head over to a Q&A site like http://DBA.StackExchange.com.
We have 3 replica AG setup. 2 replicas are in sync/automatic failover, the other(DR Server, different subnet) in asynchronous/manual mode…All these replicas were on sql server 2012, Recently we upgraded DR server to 2014. Since then we have a problem, the AG databases in 2014 instance went into ‘Synchronizing/ in recovery’ state…The SQL server error log has message, the recovery couldn’t start for the database ‘XYZ’…We tried to create a new database and add it to AG , it works for fine for other two 2012 replicas, but on 2014 we see the same issue…Is there any workout to fix it..Quick suggestion would greatly be appreciated
Deepak – this blog post is about SQL Server 2016’s 2-replica AGs. You’re asking a question about something completely unrelated. When you have a question about something, rather than posting it on a totally unrelated blog post, try heading over to a Q&A site like http://dba.stackexchange.com. There are lots of folks there ready to answer your questions. Hope that helps!
I’ve tried to read all the links and I hope that you haven’t already addressed this. Does the dynamic Quorum feature of Windows 2012 and above eliminate the need of having a witness for the basic availability group?
John – correct, AGs don’t have the concept of server witnesses. They do rely on Windows failover clustering, which *does* use shared disk or file share witnesses to improve quorum though.
SQL Server STD 2012\2014 support for SQL Server always ON
Satish – no, only Enterprise Edition.
I have a question here and am sort of new to AOAG. Some documentation states that the AG Listener should be created/configured within SQL as you create the AG. Some people like you are doing it when creating the cluster in WSFC. Which is correct or does it matter? When I create the AG in WSFC nothing appears in SQL. Is this OK or am I to do it in both places?
Oh forgot one thing. When I create it in WSFC, SQL doesn’t seem to let me create the listener there. Did I just answer my own question?
Ayup.
I noticed that the feature list page on Microsoft just shows it as a placeholder. Can anyone confirm that Microsoft is still planning to allow BAG as part of Standard Edition for certain? We have a data center migration coming up in June and there’s a desire to use AGs but only for HA purposes and we really don’t need readable secondaries so being able to save on licensing costs would be huge.
Along with that, would you recommend based on the above requirement to wait for SQL16’s release or continue to move forward with 2014 (the RTO/RPO is under 30 mins so AG is a must).
Rich – no one’s going to know until Microsoft releases the final feature list & licensing details.
Anyone who knows isn’t allowed to say (due to NDAs), so anyone who does say, doesn’t know.
Thanks, I figured as much but we will have some consultants involved in the migration so I think I’ll test them to see what their answer is to that 😉
That said, based on the time frame we have and if we assume that BAG would be available in Standard in SQL16, would you recommend going with that over 2014? I was just hired at my new company to guide them on the migration but its a fine line between being bleeding edge and getting the right technology for the right cost.
You know what they say about assume – you make an ass of you and Uma Thurman. Or at least I think that’s how it goes.
I just wouldn’t assume anything about SQL Server 2016 features, licensing, or availability dates. The CTP 3.2 that went out *this month* just added all-new BI features. It’s way too premature to guess.
Uma and ass go together quite well though. 😀
Thanks Brent….great info regardless for anyone looking at SQL16 in the future. I guess its still a wait-and-see approach but I’m glad Microsoft is adding a lot of features to this latest version, especially not just EE.
You’re killin me, Smalls.
Hi,
i see in the MSD and the Official SQL Blog they have changed the language for BAG to see it’s only going to support 1 Database for Allways On Availabiblity
https://msdn.microsoft.com/en-us/library/mt614935.aspx
http://blogs.technet.com/b/dataplatforminsider/archive/2015/12/15/enhanced-always-on-availability-groups-in-sql-server-2016.aspx
Is this true? If so it would be a major pain.
Yes: https://www.brentozar.com/archive/2015/06/how-to-set-up-standard-edition-alwayson-availability-groups-in-sql-server-2016/
Nice article.
I have a question. In always-on setup, when i send insert statement which server’s DB will be executed first? it will be inserted to node 1 first or node 2? and when commit will happen?
Deepak – in synchronous mode, the commit is completed when the write is completed on both nodes. In async, it’s committed when the write is completed on the primary replica.
Hi Brent,
I recently read here
https://msdn.microsoft.com/en-us/library/ms366279.aspx
that neither DB Mirroring nor AlwaysON AG support cross-database transactions.
Basically, in such configurations, a transaction may leave inconsistent data.
It looks like there is no “cross-db safe”. HADR technology in SQL Server.
Am I missing something ?
Yes, check out our HA/DR worksheets inside our First Responder Kit – click First Aid at the top of the page. We show how to pick the right HA/DR technology for you, including which ones are cross-db safe.
Thanks Brent,
As per that document, only SAN/VM replication or FCI are “cross-db” safe.
Therefore, if I have a FCI in a building and want an additional server in a different location for DR purposes with less than 5 minute dada loss, there are no viable options I can see.
Alberto – take a step back and think about that for a second. If you’re willing to lose 5 minutes of data, then the databases don’t need to be at the exact same point in time, right?
After all, if you were going to restore your databases from backup, you understand that they’re not all backed up at the exact same moment in time, right?
Hi Brent,
you’re right, however what I am worried about is the following scenario:
BEGIN TRAN
INSERT INTO DB2
DELETE FROM DB1
COMMIT
If I backup both DBs and restore them in case of crash, they can be not in different point in time but they *WILL ALWAYS BE* consistent. No way to have data in DB2 and not in DB1.
In a mirroring or AlwaysON scenario, as per MSDN the transaction may leave inconsistent data. I can have Insert in DB2 committed but not the delete on DB1.
Is there a way to have a safe replication of DB1 and DB2 in such scenario ?
I just want the A and C letters of the ACID property guaranteed.
Thanks in advance 🙂
Alberto – you forgot the part about the backups. Here, I’ll help:
(DB1 log backup starts in another session)
BEGIN TRAN
INSERT INTO DB2
(DB1 log backup finishes, DB2 log backup starts)
DELETE FROM DB1
COMMIT
(DB2 log backup finishes)
WHERE IS YOUR CODD NOW?
I guess DB1.BAK will not contains any data since it finish before delete.
Or it may contain part of the transaction if this DB act as coordnator for crossdb transaction.
In any case data will be rolled back during recocery.
Again DB2 backup will contain data of the INSERT but they will be rolled back during restore..
I can see no way to get inconsistent data restoring these backups which is what i expect.
If i am missing something it means that 1 month vacation alone in Patagonia was not a good idea 🙂
Alberto – what makes you think DB2’s insert will be rolled back upon restore?
For example, think about what happens if you restore DB2 *before* you restore DB1? Do you think DB2 is going to hang out in recovery until DB1’s restore finishes?
You are definitely missing something – before responding further in the comments, you probably want to actually *try* these exercises.
Hi Brent ,
we needed a HA solution with no data lost so we ended up buying Enterprise Edition to implement AlwaysOn AG.that is only one database and we don’t need secondary be accessible. since we haven’t bought it yet just want to clarify with this post you are saying that we can have no data lost and implementing AlwaysOn Ag with out buying Enterprise Edition just use SQL 2016 Standard Edition an follow your article ?
Monammy – SQL Server 2016 isn’t out yet, so if you need it today, you need to use SQL Server 2012 or 2014.
Also, AGs don’t guarantee zero data loss: https://www.brentozar.com/archive/2015/09/synchronous-alwayson-availability-groups-is-not-zero-data-loss/
thanks for you reply
isn’t there any zero data lost solution then ??
Sure, grab our First Responder Kit – click First Aid at the top of the screen, and get our download kit. We have an HA/DR worksheet that lays out the different choices for HA and DR, which ones allow for zero data loss, etc.
I just recently downloaded RC3 and it is Enterprise edition. Going through the setup for Basic AG’s I am not seeing the option for selecting Basic Availability Group. Is this because it is the enterprise edition, and if so how do I find just the standard edition, as I am not having any luck finding the download?
I had this setup using Enterprise Evaluation edition with CTP 3.2 – http://smooth1.co.uk/installs/dbinstalls.html#3.1.18
David,
I am good up until the point where you enter the name for the AG Name. There is not an option for Basic AG, only an option for Database Level Health Detection.
There is no Standard Edition yet – right now, the downloads are Evaluation Edition (aka Enterprise) or Enterprise Edition.
Any idea as to why I am not seeing the same 3 options on the AG Name screen? Difference with RC3?
We removed the “Basic AG” option (BAG 🙂 ) from the UI, as SQL Server now automatically creates the right type of AG depending on the edition: BAG in Standard, AG in Enterprise (Developer or Evaluation).
Hi,
How can we get to the evaluation copy of Standard Edition?
I would like to check my blog post above still works for RC3.
Regards,
David.
David – there’s no eval of Standard Edition.
Seems to me that according to the current documentation AlwaysOnGroup are NOT in standard edition.
https://msdn.microsoft.com/en-us/library/cc645993.aspx. So wish they were would be big reason to move from 2014 to 2016
Hi Kris,
Basic Availability Groups are a new feature for SQL Server 2016, specifically for use in Standard Edition.
https://msdn.microsoft.com/en-us/library/mt614935.aspx
The whole functionality of Availability Groups called “AlwaysOn Availability Groups” is available in SQL Enterprise. A limited version called “Basic Availability Groups” is available in Standard. For each availability group it supports 1 sync or async secondary replica, not readable, manual or auto failover, 1 DB. It shares the same underlying core of AlwaysOn Availability Groups, including all the log synchronization performance/scalability enhancements, support for domainless/untrusted clusters, DB-level failure detection, etc.
nice . wish Microsoft would update there feature documentation before the tech documentation
Basically isn’t this just a failover cluster setup?
AlwaysOn Basic Availability Groups provide a high availability solution for SQL Server 2016 Standard Edition. A basic availability group supports a failover environment for a single database. It is created and managed much like traditional (advanced) AlwaysOn Availability Groups (SQL Server) with Enterprise Edition. The differences and limitations of basic availability groups are summarized in this document.
It is not really a true availability group where you can have a readonly distributed correct?
Kris – no, Basic Availability Groups don’t require shared storage and don’t have a single point of failure (in the storage).
Hi Brent,
I’ve created another blog post on the installation of Basic HA. Some of the screens in the installation wizard has been changed since CTP 2.
How to Set Up Basic Availability Groups in SQL Server 2016 https://blogs.technet.microsoft.com/msftpietervanhove/2016/05/10/how-to-set-up-basic-availability-groups-in-sql-server-2016/
Regards
Pieter
Great, thanks sir!
Great informative article. I followed to the dot., only issue I have with Two Node cluster, every time a Fail over occurs, if I do manually or reboot server, the databases are failing over fine and in sync, however the DB are inaccessible to App server UNTIL I redo the Ownership to the userid that i have in web config. So in other words, every time failover occurs on secondary, I have to manually run the ALTER AUTHORIZATION ON DATABASE: on the databases and specify the Owner for the App server to work. And when the Primary server comes online and I manually rollover the DBs to Primary server, I have to do the same issue ALTER AUTHORIZATION ON DATABASE: for the app server to connect to the database. Any suggestion or solution to my problem is highly appreciated!!!
Paul – for troubleshooting questions, head on over to http://dba.stackexchange.com.
can any one help on this?
Homework: Homework 5.2
You have just been hired at a new company with an existing MongoDB deployment. They are running a single replica set with two members. When you ask why, they explain that this ensures that the data will be durable in the face of the failure of either server. They also explain that should they use a readPreference of “primaryPreferred”, that the application can read from the one remaining server during server maintenance.
You are concerned about two things, however. First, a server is brought down for maintenance once a month. When this is done, the replica set primary steps down, and the set cannot accept writes. You would like to ensure availability of writes during server maintenance.
Second, you also want to ensure that all writes can be replicated during server maintenance.
Which of the following options will allow you to ensure that a primary is available during server maintenance, and that any writes it receives will replicate during this time?
Check all that apply.
Add another data bearing node. Add two data bearing members plus one arbiter. Add an arbiter. Add two arbiters. Increase the priority of the first server from one to two.
Add another data bearing node.
Add two data bearing members plus one arbiter.
Add an arbiter.
Add two arbiters.
Increase the priority of the first server from one to two.
can anyone please help me for this assignment:
I confused between below options: probably answer will be out of below options:
1 and 5 ??
1 and 3 and 5 ??
only 1 ??
only 5 ??
Only 2 ??
i tried 1, 3 but not working
tried 3,5 but not working
I have only one attempt left so need expert opinion.
Amit – I have bad news.
I don’t think you’re going to pass your class.
It’s not just that you don’t understand MongoDB. You don’t even understand how to Internet. This blog post – and indeed, this entire web site – is about Microsoft SQL Server. Your question is about MongoDB, something entirely unrelated.
You don’t even understand that you probably shouldn’t be pasting the word “Homework” as part of your question. If any of your teachers happen to Google your name, the whole thing is right up here online, easy to find, and they’ll see that you are completely and utterly clueless.
It’s time to have an honest talk with the professor. Ask them if you’re a good fit for the career you’ve chosen. Maybe talk to a few trusted friends or a guidance counselor. This, however, is not the career for you.
HI! Could you help me?
In my mssql server, i can’t see that options(Basic Availability Group, Database level health Detection, Per DatabaseDTC Suport) in New Availability Group – Specifiyname. i just see to write the Availability group name.
So, when i execute New Availability Group Wizard, it couldn’t success.
this is contents of the error. -> The specified command is invalid because the Always On Availability Groups join availability group(basic) feature is not supported by this edition of SQL Server.
Thank you
Okhyun – for questions, head on over to http://dba.stackexchange.com.
Great post!
For BAG Listernes remember to have the cluster computer account able to Create Computer objects on AD OU that holds your servers.
Dear Brent,
how do (and can I) connect to Listener via SSMS?
I setup both SQL servers 2016 in the same way, and they use another ports (does this have an influence)..
Thank you!
You type the name of the listener in for the server name.
Yeah, I tried that, and i got to conclusion i had to force port 1433 on AG listener…
And than SSMS works with no problem…
The port number can also be specified in the connect from SSMS.
http://www.smooth1.co.uk/installs/dbinstalls.html#3.1.17
“We can connect using the listener and port demoagl1,1445”
I need another screen shot on my blog of the dialog box for SSMS, time to rebuild my AG setup again!
“If you have ten databases, each in its own BAG, that’s a Dime BAG.” (this is 50% of why I read your blogs over anyone else, hahaha)
Hahaha, thanks, sir.
Hi,
Fantastic post… I fell at the last hurdle.
I believe I have worked through everything to the letter except I want to use the BAG for synchronous commits. I cannot check the synchromous and automatic fail over check boxes, is this an option for BAGs…
or what might I have missed?
Many Thanks
Hi Nick,
The limitations for Basic Availability Groups https://msdn.microsoft.com/en-gb/library/mt614935.aspx does not mention synchronous or automatic failover.
You may want to try to alter the availability group and see what message is returned https://msdn.microsoft.com/en-gb/library/ff878601.aspx
NOTE: As per the note in the books online entry for Alter availability group
“SQL Server Failover Cluster Instances (FCIs) do not support automatic failover by availability groups, so any availability replica that is hosted by an FCI can only be configured for manual failover.”
Hi Brent,
I have followed your post and searched the internet but the one thing that seems to be an issue with the failover, is the SQL Logins. Why doesn’t AG seem to handle this or did I do something wrong with my setup. How do I get the secondary (when it becomes the primary) to recognize all the logins from the primary? There is nothing in the documentation (that I noticed) that seems to address this. FYI, I have used the setting of containment=TRUE but this I believe is only valid for the specific DB.
Any guidance would be greatly appreciated.
Thx!
Angel – start here: https://msdn.microsoft.com/en-us/library/hh270282.aspx
Anything which is not contained within the database has to be manually copied.
If you have CDC enabled on the source you also have to manually start the cdc sql agent job when you failover!
List is here https://msdn.microsoft.com/en-us/library/ms187580.aspx
Hi Brent,
Is it possible to configure Always On between the Standard edition and the Enterprise edition?
Many Thanks!
No but that wasn’t supported for Database Mirroring on any release from 2005 onwards either. You could mirror up from 2005 to 2008 within the same edition but going from Std to Ent Edition was never possible or supported for any version.
Iam planning for a 2016 ent test server set up on multi subnet.I need some clarification on it ,do we need to do it with multiple net work card one for private and one for public.
My test set up include
ser1 ,ser2(read sync) and ser3(async) on another location and sub net.
create a cluster with the 3 nodes
How many network cards needed per server ? and do we need to use nw teaming etc
Do we need to add any file share or disk as a resource for cluster voting (no automatic failover to the Dr site)
Ask the nw admin to give permission to add computer object to the cluster object
add the ag and add the listener and is done
I will be using the same ad account for all the servers.Please add any missing or any more info to this set up
Thanks
For random Q&A, head over to http://dba.stackexchange.com
Thanks!
Brent,
In setting up the WFCS using a file share for the witness, is there any reason i can not or should not use a Distributed File System share?
We are investigating upgrading from dual stand alone servers to utilizing some of these features in our next SQL upgrade and I’m trying to learn how all this works. I haven’t needed or held any MS certifications since NT4 was the new kid on the block so please explain using small words. 😉
Thanks
Steve
Stephen – good news: I can explain it with small words.
Bad news: the small word is no. Not supported.
To keep things “Internet Friendly” I shall simply say – Well Poop! I appreciate your taking the time to reply (and for using words I can understand lol ).
All of the High Availability technology is new for us and one of the topics I am still currently researching is what happens with loss of the witness / quorum and I thought that might provide a simplistic solution.
I have my VM’s built and am using this guide as my basic road map to build & “play” so hopefully an old dog can learn some new tricks.
Thanks Again!
Hey good day Brent, first time caller here.
I’m currently testing out BAGs in 2016 and when I failover, we get login issues with the test application with regard to username and creds.
The user is created on the primary initially and given all the necessary permissions, but upon failing over it seems those creds and permissions don’t carry over.
How would one circumvent this for a seamless failover, without the need to recreate credentials on the new primary?
Geon – it’s a problem similar to what you face with traditional database mirroring as well as AGs. Start here:
http://sqlsoldier.net/wp/sqlserver/transferring-logins-to-a-database-mirror
Thanks for the quick reply! Will take a look.
Hi Brent,
I have a BAG SQL2016 standard edition installed (synchronous commit mode). The 2 nodes are on the same site/datacenter.
Full and transactional log backups are taken regularly from the primary (no other choice with a BAG) to a file share. How can I ensure the backup chain is not broken after a failover? How can I ensure restore point in time in case of site DR?
Xavier – explaining that is a little beyond what I can do quickly here in a blog post comment. Your best bet there is to pop open Books Online or attend a class.
OK, thanks for the quick answer.
we have sql2012 enterprise installed with 2 node windows cluster. is there any advantage to turn on always on availability group?
Only if you intend to use Availability Groups.
is there anything I need to do on VMWare settings, because my failover doesn’t work on alwayson with BAG and the MAC address of the Original server stays in the ARP cache of the core switch/cisco4500. Strange thing is that it worked before and ‘nobody changed anything’…
Roland – for Q&A, head on over to https://dba.stackexchange.com.
I got confused with so many things about this Basic Always On AG. Please shed a light.
– I didn’t notice that i need to create the Availability Group. Why? Because after creating cluster, i saw that Fail-over occurred between 2 nodes. For example, after i stop EC2 which is the 1st node, then the other EC2 went online. So basically, my app could connect to this 2nd node using the domain name which my 2 nodes joined.
I combined this with Merge Replication so i can even read/write in both database inside 2 nodes and replicated between them.
– In case i configure Availability Group in SQL Management, you didn’t mention we have to create AG Listener. As far as i know, this is the something like endpoint so our app can connect to. So we have to configure them? IF not, what would happen?
KHoi – for questions, head on over to DBA.stackexchange.com.
According to Microsoft “At this time, there is no UI support to create basic availability groups in SQL Server Management Studio.” source https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/basic-availability-groups-always-on-availability-groups I don’t have my instance up yet, so who is right about using a GUI to create the BAG, you or microsoft?
James – you’ll find out soon enough. Enjoy!
Hi Brent,
Do you happen to have How to Set Up an ENTERPRISE Edition Always On Availability Groups in SQL Server 2016 versions as well?
Thanks,
Kevin
Kevin – sure, we have all kinds of resources here: https://www.brentozar.com/sql/sql-server-alwayson-availability-groups/
Gday Brent. Long time reader, 3rd (ish) time poster. Are you able to clarify something here? I’m building an AlwaysOn standard edition cluster in Azure (2016) with 7 databases. Each database has its own availability group and hence own listener. From the MS docs I’m reading I need to configure and azure load balancer to get this working. OK fine with that. What I am finding though is that (and you can probably see where I’m going with this) is that I am configuring a new IP address and subsequent load balancer rule for each listener (effectively each database). So each database that I add to this server (that I would like to be highly available) will need to be configured this way (with the corresponding load balancer IP address and rule)? Seems like a lot of overhead here each time I add a database to this server. Or maybe I’ve just walked a long way down a wrong alley? Should I just have used Enterprise edition to save this hassle?
Yours most fervently,
Browny
Glenn – thanks, glad you’re enjoying our work. Yep, you’re right, Basic Availability Groups are a lot of work there. We don’t do BAGs in Azure VMs, but I bet if you post it on a Q&A site like https://dba.stackexchange.com, someone might have a workaround. Hope that helps!
Hey Brent, thanks for responding so quickly. OK I’m going to have to look into another option for HA here as the client can’t afford to run up enterprise edition. Oh well, It’s all learning.
p.s. Australia won world’s best whisky again this year. Just sayin’…
http://www.executivestyle.com.au/sullivans-cove-distillery-wins-at-world-whiskies-awards–again-h0y16m
G
Hello Brent, Great job, this thread. I try to catch up once every 2 or 3 months. Now for my question. Can you provide some insights regarding dtc, some really clear info considering dtc support in relation to mssql 2016/2017 is hard to find. In my job I’m in the process of configuring mssql 2017 enterprise AG groups with dtc support and as I see it, every database configured under a dtc-support enabled AG group is provided with a unique identifier that can be used by the local dtc’s of the member nodes of the AG. Hence no clustered dtc is needed anymore? Is this assumption correct? I am aware of the differences in 2016 vs 2017 dtc support
Evert – your best job there is to post the question at https://dba.stackexchange.com with the specifics of your situation. I can’t really do free Q&A here.
Glenn,
If you think about it, if you have a listener configured on one of the AG’s and none of the others. Operating in Active/Passive mode, all AG on same node. Failure on Node1 will cause all AG to fail over to node2. So the listener on the one AG can actually be an entry point for all the databases. This pattern will work if you keep track of knowing that they are all running on the same node together as your steady state.
John
John – you’re assuming none of the databases will fail over individually, but that’s not necessarily the case. (BAGs are one database per AG.)
Hi
Stumbled over this a few times now, while trying to figure out if a consultant is right or not in his claim. I hope you can shed light on it.
Is it, or is it not possible to configure a Basic Availability Group on a database present in two AD-Servers with each its own standard edition SQL2016sp2 cu2 (default instance)
(Both had the SSMS 16.5.3 management studio – now upgraded to SSMS 17.9)
Almost everywhere I seem to find, it looks as if they all require that nodes be member(s) of a WSFC.
“Almost”, because I read a Microsoft note, stating that it’s possible with SSMS 17. I did install that and it also fails to enable the options to switch on AG?
If it *should* be possible, do you know where I could go to read what’s needed…
BR – for questions, head over to https://dba.stackexchange.com.
Newbie…
Hi Brent, Thanks for your this page.
But one question … you mentioned as “After installing those clustering prerequisites, open Server Manager and click Manage, Add Roles and Features, select your server, and on the Features list, check the Failover Clustering box:”
But I can’t find in this page about where you mentioned as “clustering prerequisites,”?
Without Windows Server Failover Clustering (WSFC) installation/configuration can we still go ahead with this?
BAG?
No, the prerequisite is installing Windows Server Failover Clustering services. If you’re not familiar with that, Google for how to install Windows clustering. Have fun!
Hi Brenet, Thanks for your page.
I have one question.
Can node be dropped and to move the base that are in a alwayson availability groups cluster to another domain?
I wouldn’t do that – I would build a new cluster in the new domain.
Thanks for the quick answer!
Then restore the bases and build the alwayson availability group.
Hi Brent,
Is it possible to use WSFC Virtual Name and IP Address as connection string for Application when you have configured multiple BAGs?
Jay – for general questions, head to a Q&A site like https://dba.stackexchange.com.
HI Dear when i click at show Dashboard under “Always on High Availability” it shows that error i.e. (an error occurred on the always on dashboard)
–> an exception occurred while executing a transact-SQL statement or batch
–> invalid column name ‘ required_copies_to_commit’. Microsoft-SQL-Server, error:207 Can you please tell me how to resolve this issue ??
High Deer – for unrelated questions, head to a Q&A site like https://DBA.stackexchange.com. Thanks!
dear, this is not unrelated question. i am facing a above mentioned issue related High availability Dashboard
Deer, you will not get an answer here. This is not a free support site. For questions, head to the site I mentioned. Thanks for your understanding.
Okay Dear 🙂
Nearly a 3 month old post but I’m legit about to lose my sh*t at Dier In Headlights over here.
Hi Brent, I am setting up Always on (Cluster) Replication 2:2 environment, and while configuring I am getting an error – Invalid column name ‘required_copies_to_commit’
SQL Server – 2017
OS – 2016
CU Version – 14.0.1000.169
https://social.msdn.microsoft.com/Forums/sqlserver/en-US/5a2656d4-155f-486a-b5c0-758474fc0e01/sql-server-2017-invalid-column-name-requiredcopiestocommit?forum=transactsql
Hi Brent,
I tried to find a book on Basic Availability Group and didn’t get any result. Is there any book you are aware of that is good? My department can only afford standard SQL so I need a book specifically on BAG.
Thanks in advance.
Xilei
No.
Question — We have AOAG set up with READ ONLY secondary and it is NOT a disaster recovery tool for us. We have reindexing that is causing AG sync lag. Would it be advantageous for us to include in the reindexing job a step to change the AG from synchronous to asynchronous and a step after reindexing is complete to change it back? Would that help with the lag or just push it to a later time? And even that might be better than having a lag build up while reindexing is done. This is a 16TB database and reindexing takes awhile to complete.
That’s beyond the scope of this blog post. For personal consulting advice, click Consulting at the top of the screen. Thanks!
Hi,
We have AG set up (Sql 2016) and there is ServiceBroker queue with a SP that process messages. It works on Primary, but after Failover to 2nd instance the queue shows it is enabled, active, etc. can get new messages, but the SP behind does not work. Need to Turn the service queue ON/ OFF.
Qs:
Is there an option (checkbox 🙂 that will handle it?
Or is there an event that the failover occurred and a SQL script/job/SP could be executed?
Or at least it is in system that could be queried, like Select IsPrimaryNodeSinceTime * sys_table ?
How do you handle failovers? Like orphaned users – an sql job, every 1h to check it?
Thank you