

If SQL Server’s Transactional Replication was an animal, it would be a cockroach. It’s not pretty, but it’s resourceful and strong. Once you get even a small amount of replication in your environment it starts spreading everywhere. And if it gets out of control– well, in that case you’ve got no choice but to pretty much bomb everything, clear the fumes as quickly as possible, and reinitialize.
But unlike a cockroach, you can’t always just get rid of Transactional Replication. The bad news is, it’s here to stay.
In this post you’ll get a whirlwind introduction to Transactional Replication. I’ll explain why newer features like Change Tracking, Change Data Capture, and Availability Groups have failed at exterminating Transactional Replication. You’ll also learn what it takes to support replication in a mission critical environment.
SQL Server Transactional Replication basics
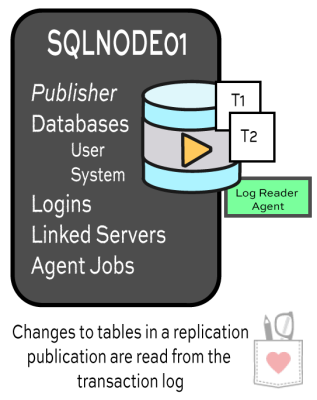
Transactional Replication lets you publish and filter individual database objects.
1) Publications define replicated articles. Transactional Replication lets you select individual tables to publish (called “articles”), allowing you to just publish a fraction of a very large database. It also lets you:
- Filter published data
- Use column filtering to only include critical columns for published tables, further targeting and limiting exactly what is published.
- Apply row filtering to put a “where clause” on a publication. This is a great way to keep a subscribing server from seeing rows that don’t belong to it.
- Publish stored procedures. This essentially takes procedure executions on a publisher and replays them on a subscriber
2) A fleet of SQL Server Agent jobs does magic. I just learned this: a group of cockroaches is called “an intrusion of cockroaches.” That seems like it probably applies to a whole lot of SQL Server Agent jobs, too.
Exactly how many jobs? So many jobs that you’ll lose count. Replication is complicated. It’s got a SQL Server Agent job to read the transaction log of where you’ve defined your publications (Log Reader Agent). There’s another job that helps run Snapshots (it helps you initialize or re-initialize the replication). Another helps apply the snapshot and move transactions around (the Distribution Agent).
There are also jobs for cleaning things up, refreshing monitoring, and all the general scuttling around that replication does.

3) The distribution database collects commands. Replication doesn’t send transactions directly to your subscribers. The Log Reader Agent snoops in your transaction log and figures out what changes have been made to the articles you’ve defined in your publications. When it finds changes, it sends them over to the distribution database.
You can configure distribution on the publishing server, or you can scale it out to an independent server. The important thing to know is that each change you make in your publisher gets translated into independent commands (insert, update, and delete), and these commands get inserted into the distribution database before it moves onward. No matter what you do, that process takes some time: replication isn’t instantaneous.
4) Commands get applied to subscribers. You may set up many subscriptions to a single publication. This is part of what’s cool about replication– a single publication can publish a narrow group of tables to be read by many subscribers (perhaps in different datacenters around the world).
You can elect to configure pull subscriptions or push subscriptions. In the “pull” model, each subscriber runs jobs that poll in data periodically. In the “push” model, the changes are more constantly pushed out to the subscribers from the distributor.
5) Old commands get cleaned up. Hopefully. Lots of commands may collect up in the distribution database. That can be a good thing– maybe a subscriber is offline for a few hours, wouldn’t it be sad if it couldn’t catch up?
But you don’t want to hoard too many commands, or your distribution database will bloat up like crazy. There are jobs that delete out old commands. In an active environment, balancing out cleanup, new activity, and pushing  data to subscribers can be… challenging.
data to subscribers can be… challenging.
6) Then you learn a million factoids. We’ve barely scratched the surface. I haven’t shown you Replication Monitor, a tool whose GUI is so confusing that you don’t dare take your eyes off it. (It’s hard to avoid it, but do use it with care– I’ve had it cause blocking when run by multiple people concurrently in a couple versions of SQL Server.) I haven’t talked about tweaking Replication Agent Profile Settings or the limitations of tracer tokens. We haven’t debated when you might want to initialize from backup.
Transactional Replication is a complicated monster. It’s not something you can book-learn, it’s just got far too many configuration options and moving parts. Replication something you learn by trying it, having problems, fixing it, and then repeating the process.
Transactional Replication vs. Change Tracking
Two new replication-ish features were introduced in SQL Server 2008: Change Tracking and Change Data Capture. These two technologies are both completely separate from replication, and from each other.
Change Tracking, like transactional replication, is available in Standard Edition. That’s a good thing, but if you’re comparing the two features, people still pick replication.
Change tracking just answers a very basic question: has a row changed? It doesn’t capture the “old data” or send the “new data” anywhere– it just updates a marker letting you know that a row has changed since your application last polled it.
It’s up to the user to write an application to regularly poll the tables (and know what version it last tracked).
It’s also recommended for the user to enable snapshot isolation on the database using change tracking and explicitly use it when querying Change Tracking tables to make sure that you don’t miss data or cause blocking with Change Tracking cleanup processes. Snapshot isolation is great, but turning it on and managing it are not at all trivial.
Change Tracking also has some additional overhead. For each row modified in a tracked table, a row is added to a change table. For each transaction that commits, a row is inserted into an internal transaction table, also. (It doesn’t keep the previous values in those tables, so they’re small inserts, but on super active tables that’s extra writes hitting the transaction log of your database– and extra writes when those tables get cleaned up.)
Verdict: Replication is complicated, but Change Tracking ain’t simpler. Due to having much less custom code to write, more freedom with isolation levels, and no extra inserts in internal tables, most people decide that Transactional Replication beats Change Tracking.
Transactional Replication vs. Change Data Capture
How about Change Tracking’s distant cousin, Change Data Capture? This is an Enterprise Edition feature– it must surely perform better than the Standard Edition friendly Transactional Replication, right? Well, sorry, not necessarily.
I love the concept behind Change Data Capture. Imagine that you’re a database administrator managing a transactional replication publication. You have a table that holds advertising campaign keywords.
- Each row in the table contains a CampaignID column, a keyword column, and a BidPrice column
- Some campaigns have hundreds of thousands of keywords
- Tools let advertisers set up campaigns quickly with LOADS of keywords– and the keyword BidPrice

It’s the day before a big holiday. One of the big advertisers goes in, and sets up a huge campaign– 200K rows of changes roll into the table. They realize they messed up and deactivate it right away. 200K more changes roll in. Then they set up a new one. Then the tweak the BidPrice.
Suddenly replication is churning trying to get all these changes into the distribution database, not to mention handle what’s happening in any other replicated tables you have. Replicated commands start backing up.
You’re left saying, “But all I want is the most recent change they made!”
This is the scenario where Change Data Capture sounds like a great idea. The concept with “CDC” is that you write your own polling. If you poll every hour, you just pick up the latest version of the row (or whatever history you want), and take that with you. You don’t have to take every command, so it’s super light-weight.
But CDC isn’t all unicorns and magic, either.
When you enable Change Data Capture for a table, SQL Server starts tracking inserts, updates, and deletes in the transaction log (similarly to replication). But when you make changes, they’re read from the log and then inserted into “change tables” associated with the tracked tables. The change tables are automatically created in the same database as the tracked tables– and inserts into them are also logged operations. So for every modification you do on a change tracked table, you’re also doing an insert (and logging it) into a tracking table.
Data in the tracking tables needs to be cleaned up periodically, of course– and that also gets logged. You need to write your own polling mechanism to pull changes, and there’s limitations to how you can change schema of a table.
While our test scenario seemed like perhaps it would help us out, after checking out a whitepaper on tuning CDC, things don’t look so hot: the whitepaper recommends avoiding scenarios where rows can be updated immediately after insert, and also avoiding scenarios where large update scenarios can occur. Also, our dream of only pulling the latest, or “net” change if a row has been changed multiple times has a cost– that requires an additional index on each tracking table, and the whitepaper points out that this can have a noticeable performance hit. This isn’t seeming like such a great fit anymore– and worse, it sounds like if it doesn’t go well, it’s going to slow down our whole publishing database.
This comparison highlights that although transactional replication commands can get backed up in the distributor, the fact that replication allows distribution to be offloaded to its own server independent from the publisher is a real strength.
Verdict: Due to extra logging caused by internal change tables (and cleanup), plus the need to write custom code, plus limitations on schema changes, most people decide that Transactional Replication beats Change Data Capture.
Transactional Replication vs. Availability Groups
Now here’s a real competitor, right? SQL Server 2012 AlwaysOn Availability Groups allow you to scale out reads across multiple SQL Server instances. You can set up readable secondary copies of a database which have their own independent storage, memory, and server resources. The secondaries can be in either a synchronous or asynchronous mode. You can even offload backups to secondaries.
If anything can render Transactional Replication completely outdated and useless, this is the feature.
It’s absolutely true that Availability Groups are better than transactional replication for high availability. But that’s not surprising– Transactional Replication is terrible for high availability! Even in Standard Edition, a simple two node failover cluster beats Transactional Replication when it comes to HA. So, yes, Availability Groups wins here, but replication doesn’t even make second place. (By a long shot.)
But when it comes to scaling out reads, Availability Groups still aren’t perfect. SQL Server 2012 did introduce a cool new feature where temporary statistics are created for read only databases that helps this feature out, but it doesn’t quite do everything. Availability Group readable secondaries still have some limitations:
- You can’t create indexes on the secondaries– all indexes must be created on the primary
- The more indexes you create on the primary, the heavier your IO load and potential for data churn in maintenance– which makes it harder for secondaries to keep up
- The whole database goes in the availability group. You can’t just include a couple of tables.
Verdict: Using Availability Groups for scale out reads works in some scenarios, but it does not replace Transactional Replication.
Transactional Replication doesn’t solve your HA or DR pains
If you remember one thing from this article, make it this fact: Transactional Replication is not a good way to save your bacon if a server fails or a database gets corrupted. This isn’t a feature for high availability and disaster recovery– it’s much more of a programmability feature to distribute data from a few critical tables from one instance out to many subscribers.
Transactional Replication does NOT support any of the following:
- Failover (or fail-back)
- Connection string enhancements
- Load balancing
- Automatic page repair from corruption
- Protection of the replicated data (it can be updated, made incorrect, etc)
For high availability and disaster recovery, you want to look primarily at other features in SQL Server.
What if you need to write to multiple masters?
If you’ve got a datacenter in China, a datacenter in Europe, and a datacenter in the United States, you probably don’t want to send all of your writes to just one datacenter. You probably want to send writes to the closest local datacenter and have changes synchronize between databases in all of them.
There’s only one feature in SQL Server that helps with this: peer to peer replication. It’s an Enterprise Edition feature which is like two-way transactional replication. Peer to peer replication requires that you handle conflict resolution, and isn’t compatible with all newer features (example: Availability Groups).
Transactional replication has a feature called Updatable Subscriptions that allows changes at a subscriber to be sent back around to the publisher, but the feature has been deprecated in SQL Server 2012. You’re recommended to look to Peer to Peer replication instead.
Requirements for supporting replication
I have a confession to make: I like Transactional Replication. There’s something about it which I admire– its flexibility, its tenacity, its ability to endlessly survive and propagate itself through more and more versions of SQL Server while other features continuously try and fail to exterminate it.

I don’t often recommend that clients use Transactional Replication. Frequently, there are other ways to solve a problem without taking on the burden of supporting Transactional Replication. It’s just not that easy to support.
If you do think you need Transactional Replication, make sure you have the right staff in place. For mission critical data, you need to have multiple, dedicated SQL Server DBAs, an established on-call rotation, a good incident response system, root cause analysis, a pre-production environment, good Change Management processes, and the ability and desire to refine and extend production monitoring.
That may sound like a lot, but trust me, the first time someone asks, “why is the data on the subscriber so old?”, you’re going to realize why I listed a lot of things. One thing you can count on with replication is that there’s sure to be interesting times along the way.

181 Comments. Leave new
It better be here to stay 😉
Been using Transactional Replication for years to pipe data from core systems (ERP, etc.) out to database servers that feed public websites and/or are a source for our SSRS reports, data warehousing ETLs, end-user query tools, etc. It’s invaluable and as you noted: rock solid.
Well, it is like a roach. A sticky one at that.
Another point to mention is that replication is a bit of a show-stopper when it comes to upgrades: the distributor has to have the highest version of SQL Server. I.e. if you have 2008 environment, you cant really upgrade any of the publishers or the subscribers without upgrading the distributor first. Go explain that to the ones who pay for the licenses and then to the ones that need a new feature of a newer version…
Also, when something goes wrong with the replication, good luck reinitializing snapshots of big heavy loaded transactional tables…
And finally, the change tracking and CDC do miracles with SSDs. Who does not have SSDs today?
You do have a good point, however, that replication has been around only for the lack of something better.
If you work with replication long enough, you can mitigate some of the shortcomings: 1) Initialize from backup 2) Splitting up your publications so *if* you have issues, you just have to reinitialize the publication having issues. I typically put very large tables into their own publication, for example. Another big one is to set immediate_sync to false so if you have to push out a newly published article/table, the snapshot only contains that single table (and doesn’t create a snapshot of the entire publication – that sucks). I haven’t run into version issue yet, but I can see where it may cause issues under certain circumstances. Fortunately I pretty much control the versions we run, vendor products included.
Feodor – regarding “who does not have SSDs today?” – SSDs are still a very unusual except in most of the cases we work with, but I’m glad to hear you’ve had success in convincing management to adopt them.
Sorry if this question comes off as COMPLETELY moronic, but what’s an SSD?
Thank you!
Solid State Drive.
http://en.wikipedia.org/wiki/Solid-state_drive
Feodor – even the comment was one year ago. I still have to say your database foundational management knowledge needs to be improved.
Thank you for the pro/con analysis versus all other HA/DR solutions. I have a love/hate relationship with Transaction Replication myself. It has a lot of pain points, but in the end, it’s the only solution that let’s you pick subsets of data and customize your indexes. Also, scaling writes with Peer-to-Peer is a great secret weapon. I keep hoping that AlwaysOn will eventually incorporate these features.
We have an app that just moved to a Saas model but we’re replicating the transactions in a batch every night to a local DB server for reporting purposes. Unfortunately we only have visibility to the subscriber due to the fact that the distributor is on the vendor’s prod server. Is there anything we can do effectively monitor replication or do we need to trust that the vendor will be watching and handling any issues?
Chris – one way to do this is to have the vendor update records in a monitoring table regularly. That way if the table hasn’t been updated, you know there’s a problem. Of course that doesn’t catch everything, like a problem with a specific article, but it helps.
Thanks for the response. In this case we know of several tables that are updated daily and since it’s just a batch update every night that’ll work for basic monitoring.
Thanks for such an informative write-up.
What are the factors that can effect application of replicated commands from distributor to subscriber, given there are no network issues.
What are the factors that can impact replication od data from distribution to subscription, given there are no network glitches?
Very thorough post, Kendra! great analysis and a wonderful analogies. Well researched and well explained, complex made easy. Thank you.
I’m a huge fan of the Transactional Replication.We are using Bi-Directional Transactional Replication with loopback detection for high availability. You haven’t mentioned it but it’s also a great multiple master feature for those environments where there is no need for conflicts resolution, it’s a little easier to set up then peer-to-peer and supports row and column filtering.
Hi Maria,
Thanks for your comment– and I love your blog!
Bi-directional transactional replication/ loopback is an interesting case. I’m glad to hear that you’ve had success with it and it’s working well.
I didn’t mention it because I don’t tend to find folks who’ve implemented it successfully or are happy with it. Getting things set up so that you don’t have conflict is really hard– and the options if you do have conflict (stop, and have a big backup/snowball of conflicts, or allow it to continue and possibly have data getting hopelessly out of sync) make it difficult to recommend at all.
Hilary Cotter posted a write-up on how he prepares tables for implementing bi-directional replication here. His most used method involves re-creating all the tables. With your experiences with the feature, do you recommend similar methods for people doing a new implementation, or do you have a different take?
Thanks!
Kendra
Thank you, Kendra, you are too kind 😉
I’m familiar with the Hilary’s great post but, in contradiction to his write-up, our environment is quite stable and almost a “real time”: ~4 sec delay between two data centers, one in Europe, another in US. We are able to take any of the data centers down for maintenance without impacting the business by simple DNS change.
Data in the replicated tables never gets updated after initial insert and we have Origin column in the PK or uniqueidentifier to avoid conflicts.
Can’t seem to find a ton of info on it. But would transaction replication be a good tool if there were two servers and we wanted data in both servers to update with eachother? The east coast will use its allocated server and the west its own. We were having issues regarding performance with everyone sharing one server. It was on the west coast, and people on the east would have problems with speed. No clue what to do for HA!
To be able to write to two different databases and have them update each other using SQL Server technology, replication is pretty much the only supported method in SQL Server. It’s a tricky thing to set up and you have to handle your own conflict resolution. To learn more, check out Jeremiah’s post here: https://www.brentozar.com/archive/2013/07/many-masters-one-truth/
Edit: I wouldn’t say that this solves high availability though. It doesn’t include automatic failover and you would only want to replicate the very minimum tables needed to keep it lightweight. You’d still want to supplement/mix with other technologies to achieve HA, and could end up with a very complex architecture.
Looking at sizing the primary SQL Server to scale it up and then using application caching to scale out and support the users on the other coast is a reasonable alternative and could be much cheaper and easier to support in the long term.
Thanks Kendra, that was very helpful! Could you explain a little more on the last bit? I’m not sure i quite understand. Also, this database is created automatically with the install of the application (as long as sql server is already installed). Now we have both servers set up and want to make sure there’s latency and performance for both.
Maybe we won’t need to replicate based on your last section?
If this is a vendor application and you don’t control the code or the indexes, then implementing something like peer to peer replication would probably totally violate your vendor agreement. So be careful there.
For more on caching and scalability, check out our list of articles here: brentozar.com/go/scale
i have 3 servers involved, if at anytime one server is offline and a person edits a record on one side while another edits a record on another server, which record would be taken if the server is back online? and also is there a way to choose which of the two records you would choose if both has been updated while the server was offline
Urgent – that’s called conflict resolution. You’ll need to read the documentation in Books Online to understand how it works for your type of replication.
Thanks for the informative article, very helpful.
We have a replication system here where we have the publication and distribution on server A, the live production server, and the subscriber on server B, the reporting server. I’ve noticed multiple articles across the web (including this one above) that show the distribution database on its own server/node. I assume this is for performance gains.
What metrics could I examine to determine whether moving distribution to its own server would give enough of a performance gain to be worth the resources? Is it as simple as isolating the CPU/reads/writes used by the distribution database? We are planning on moving our production server onto a HA cluster at some point this year, so this would seem an ideal time to upgrade our replication setup.
I’d start a step farther back– are you having any performance problems on your publishing server?
If you’re moving to new hardware for purposes of HA and you scale the hardware properly for growth, then it’s certainly cheaper to keep the distributor with the publishing database when you can– plus you’ve automatically achieved high availability for your distributor.
CPU and IO are certainly ways you can look at the distributor’s impact. But it’s not just about overall/average metrics — on systems where you can get big bursts of updates in the publishing database, you’re going to get a corresponding big burst of activity rolling into the distribution database. This turns into a ball of fire pretty fast, and in these situations scaling out distribution is attractive. But not every system is like that, and scaling it out certainly isn’t free.
What are your latency statistics? That’s what you care most about – all the rest of the statistics would merely be a contributing factor.
I did set up latency tracking on the distribution/production server. The latency averages 5 – 8 seconds. I’m not sure if that is really relevant because my goal is to reduce resource usage on the production server. The subscription server is just a reporting server, and doesn’t need to be up-to-the-second current.
To answer your question Kendra, we aren’t having any performance problems per se, but I like to stay ahead of potential problems instead of reacting to them. Our production SQL Server has a history of high CPU usage during our busy months, so if possible I’m trying to find ways to reduce now, when we’re slow.
Got it.
Being proactive is great, but if you aren’t experiencing performance pains then it’s hard to prove that scaling out distribution itself causes a performance improvement. You could show that you maintain current levels of latency and reduce certain kinds of activity on the publisher, but that’s not exactly the same.
Maria Zakourdeaev just published an article that I bet you’ll love about considerations on the distributor:
http://sqlblog.com/blogs/maria_zakourdaev/archive/2014/02/12/the-distributor-think-and-rethink-every-thing.aspx
Really nice post, Kendra!
Comparing replication with cockroaches does not make for a strong selling point though 😉
I am wondering if replication is a good choice (or even possible) for the following…
We want some tables on our acceptance environment be the leading data provider for the production database. This is so we can test these changes and push them forward to production after tweaking and approval.
The production database is in a 24/7 HA group. The tables are a few dozen and some are relatively large (though a typical change set is not). Another requirement is that some changes need to be immediate but most will follow software deployments.
My main alternative at this point is to use Change Tracking (or triggers) with custom code.
Any suggestions welcome.
Thanks,
Michel
Michel – when you say “tweaking and approval”, that’s not a mechanism built into replication by default. If your users want to interfere with the flow of data (like change or approve data), you’re looking at custom code no matter what. As long as you’re doing custom code, why rely on replication? Change tracking or triggers probably makes more sense.
Hi Brent,
Thanks, I was afraid you would say that, but at least I now have confirmation.
Love your articles!
Thanks again,
Michel
Thanks! We have a lot of fun here, heh.
My transactional replication is working great. My filter is not working. Any suggestions. It is:
SELECT FROM [DBO].[BOOKING] WHERE [ORI] = ‘LA0370000’;
I want only the records that belong to the la0370000.
thanks
Oh, and don’t forget to run the snapshot agent – that’s likely what you missed, even if you did mark the subscription for (re)initialization.
I think Allen is on to the right answer. Filters also aren’t supported for Peer to Peer, but you said transactional so I think he’s got the right cause.
Was the filter set up prior to initialization? Because if the filter was just set up, you will have to reinitialize.
Very nice article, giving insightful comparisons. And I do like the cockroach analogy 🙂
I am at a point where I would like to replicate data from SQL2008 to a SQL2012 server with AlwaysOn Availability Group configured. When I tried setting up the replication, the wizard stopped me when I tried to point the replication to the AOAG’s Listener name, something that seemed obvious.
Not much help on the various searches. AlwaysOn is quite new, and few people are experimentig yet it seems. There is even a post on a Microsoft support site that mentions in a grey box: Supporting failovers on a subscriber is hard and unreliable. The closest solution I have found implicates to stop the old subcription and create a new on on the “new” target server when a failover happens, using the ID of the last transaction to somewhat resume replication.
I am racking my brains out and trying various scenarios and 3rd party tools (we also have IBM CDC to replicate from other heterogenous data sources to the SQL2008) to find a way to move data to the SQL2012 AOAG in a fast and stable way. But everytime, I hit the wall: the Listener cannot be the target.
Would you have suggestions for me by any chance?
Hi Philippe,
I haven’t experimented with replication subscribers in an Availability group at this point– it does only support manual failover of the subscriber database. This article in Books Online does say that you should be able to use the listener name, however: http://msdn.microsoft.com/en-us/library/hh882436.aspx
Are you able to connect to the listener name from your replication publisher server using a linked server (just as a test)?
Hi Kendra.
Yes, I can use a linked server to access/manipulate data under the Listener’s name. I will keep working on this, hopefully create a script that automatically takes over the recovery of the replication in case of failovers. Or maybe try a Pull subscription from the Availability Group? There are tons of possible ways to do it, just ahve to find the right and stable one.
Thanks for your answer.
Hi any news about replication subscribers in AG? I’m looking for a solution for that. Looks like there is no easy way to do that.
I certainly wouldn’t say it’s easy — both replication and AGs are tricky to manage individually – but automatic failover of transactional replication subscribers is fully supported. https://msdn.microsoft.com/en-us/library/hh882436.aspx
I was reading right that article. too bad is really confusing.
Yeah– I think of it like this: you’re a zookeeper. You need to learn to take care of lions (replication) and then the zoo talks about getting a new tiger (availability groups). Individually you can become good at caring for each one with a lot of focus and practice. And in theory you can get them to live together in a single environment, if it’s big enough and managed correctly. But it could also go very badly.
Yeah it wasn’t so hard to do it in the end, but peer-to-peer replication is not supported, right?
If I want do sync two datacenters using peer-to-peer replication while still having HA, what option do I have? FCI, mirroring, log shipping?
Correct, peer-to-peer isn’t supported with replication. For a distributor your HA option is failover clustering and for DR you can use log shipping. (Mirroring isn’t supported for distribution, either.)
So peer-to-peer replication works with FCI? (why can’t I answer your replies below?)
Yes, those are compatible. Our comment threading has a limit on the number of replies to a single topic. But you can always start a new thread in a fresh comment, too. 🙂
Hi Philippe, we have an environment where the publisher is a SQL 2008. It is replicating through SQL 2012 Distributor to the SQL 2012 subscriber with Availability Group. The replication implemented using a pull subscription from the primary node of the Availability Group ( instead of using the listener). The replication is working great. In the rare cases of the failover we are trying to bring the primary AG node back as fast as possible, meanwhile subscription databases on the 2012 nodes temporary are not getting the updates, Distributor is holding the transactions till subscriber is ready to pull them.
Hi Maria
It sounds like what I am going to implement, until I can make an automated script run to recreate subscriptions at failovers. Or that I find another solution, setup, or 3rd party tool.
I still have to analyse if some of theses new items in SQL2012 can help:
?sp_get_redirected_publisher
?sp_redirect_publisher
?sp_validate_replica_hosts_as_publishers
?sp_validate_redirected_publisher
Or if I can use fn_hadr_backup_is_preferred_replica to validate at any time if I am on the proper “active” node while in a replicating job.
Sorry, I didn’t expect to hijack the post this way 🙂
Would like to ask about row-wise filtering on transactional replication.
If I define a filter on a column called, say, ‘DELETE_FLAG’ ; e.g.
WHERE DELETE_FLAG true
after the initial snapshot, my subscriber would include all cases that pass the filter. What happens when the value of the DELETE_FLAG column for a row changes to ‘true’ ? Obviously the row won’t be included in the transaction update to the subscriber, right? But what about the row that already exists in the subscriber? I can’t find anything in the SPs on the subscriber side that would ‘sync’ rows by deleting the row in the subscriber. (It’s a ‘delete’ based on the data and the filter NOT an actual delete of the row in the publisher)
Is this handled somehow I’m just not seeing?
Edit: Me e.g. was meant to mean:
WHERE DELETE_FLAG != true
(can’t figure out less than greater than)
Hi Steve,
So quick demo with relatively senseless data. My published table is Production.TransactionHistoryArchive and i use a filter of WHERE Quantity=4. Only rows with that quantity get pushed to the subscriber. I get 7,356 rows on the subscriber with that quantity.
I then run an update for one row where TransactionID=1 and change Quantity to 5 (it was 4).
Now I still have 7,356 rows on my subscriber — 7,355 of which have Quantity of 4, 1 of which has Quantity of 5.
So just as you feared, the static filter for transactional replication isn’t that smart. I can totally see why it would seem like it would be! You have a couple of options– you could detect the value on the subscriber, or write custom code to handle updates in replication. Both of them can be painful depending on how you’re using it.
You do also have some other big-picture options, such as replicating indexed views, but whether that makes sense depends on your situation.
I don’t think filters are a good option where the data will be volatile; rather they are useful for columns that do not have a high probability of changing. I personally don’t use them very much, as they can add significant overhead. I haven’t tried it, but perhaps you have a “cleanup job” on the subscriber to remove records that no longer qualify for what you want replicated, but that doesn’t seem wise I don’t think.
Missing something in your reply Kendra… you say that after modifying the data, the sub has 7355 that are qty=4 and 1 with qty=5. How? If Qty=4 is your filter, how did qty=5 pass at all? I would expect, based on the feared supposition, that you would still have 7356 with qty=4. What have I missed?
Anyway, thanks for checking. If you have 7356 on the sub after the data change, than what I suspected (feared) is true … no server handy to test on this evening. Seems like it makes the row-by filter kind of pointless, unless your filter column never changes data. (which probably only happens in the utopian AdventureWorks world).
thoughts:
1) A custom sp on the subscriber wouldn’t work since the data change would not ever pass the filter on the publisher
2) moving the filter to the subscriber side via sp eliminates any efficiencies had from filtering data movement across the network. I guess it decreases storage on the sub. that’s all I’ve got.
3) if the filter is a true\false and you know the current value of the field on the subscriber, the bitmap of changed fields in the sp, would indicate a case for deletion, right? Follow me… For rows where current value is false on the sub, the sp for update fires with the change bitmap indicating the filter column has changed…it can only be true… time to delete the row. Yes I think that would work… tell me why not.
This is all a bit kludgy. Thanks all.
There are obvious flaws with filters, but it does make sense as to why things work the way they do. I think they are better suited for more static data rather than data that has a descent probability of changing.
I’m curious too why the data would have replicated as you noted. I’ll have to put up a test of my own and run a trace to see what’s going on.
nevermind… too tired. #3 is no more efficient than #2. use bitmap or use data field… doesn’t matter. if I passed the row across, the efficiency of filtering is nil.
To be of use, I would need a filter on the pub, that still passes an indication of change to the sub.
Going in circles. scrap the row-by filter. for this case.
If the row already exists on the subscriber, you will have to reinitialize the subscription to get rid of those rows that were present prior to the filter. Remember, transactional replication just sends commands to the distribution database from the transaction log – if there is no actual “delete” statement to remove the row from the publisher, there will be no such command sent to the subscriber to remove the row.
Hi Kendra
Very Good post, I think transactional replication has received undue bad rep because most solutions aren`t supported and maintained correctly, and that is one thing you always have with replication – support overhead.
I am glad you also still see some good use for it, I was thinking that I was becoming crazy.
I recently had to devise a solution to geo-replicate data from numerous sites to one central point in order to build a consolidated BI solution, the data had to be up to date to the minute, it had to be simple and quick to implement ,native to SQL Server( no extra costs for software) and work on just a subset of the data.
Transactional replication was definitely the best fit here, and this is why it has been such a resilient technology as you have mentioned.
Cheers
Well, I think many implementations aren’t supported or optimized because it’s only “simple and quick to implement” if you’re an expert on the feature.
Think about someone who’d never used it before— how would they know all the tricks and complexities of setting it up, monitoring it, and making it fast? There’s no good manuals out there and you’ve got to build up loads of experience before you know how to make it work well.
I don’t think you have to have a lot of experience to get it up and running. To set up a distributor, publisher and subscriber is pretty basic. Now, I’m not talking about a large scale topology that has servers across the nation; rather I’m talking about replicating between a few in-house servers for reporting/BI purposes or to serve up read-only data for websites to tap into – a pretty typical use case.
When I had a need to make some adjustments – push v. pull, moving the distributor, “unclogging” commands, adjusting -SubscriptionStreams, immediate_sync to false, optimizing agent configurations, etc. – I felt I was able to find what I was looking for in a reasonable amount of time.
This is a good one I’ve kept bookmarked:
http://technet.microsoft.com/en-us/library/ms151762(v=sql.105).aspx
This was a pretty nice case study on using replication for HA/DR:
http://download.microsoft.com/download/d/9/4/d948f981-926e-40fa-a026-5bfcf076d9b9/Replication_HADR_CaseStudy.docx
Well, I respectfully beg to disagree that it’s easy. Particularly since in many implementations you’ll have problems when pushing your first snapshot due to permissions, and if you haven’t used it before it’s not even easy to find the error in the tools.
For beginners, it’s very difficult for them to know where to look or which articles to trust, so mistakes get made. I’m not saying that makes it a bad technology, I’m just saying the learning curve is very high, especially at the beginning.
Actually I think we agree – replication is not for beginners. I didn’t think we were talking about a beginner; rather an existing DBA (say, 5+ years exp) setting up replication for the first time. DBA’s with any sort of experience generally know their way around the highly networked SQL Server community (LinkedIn, Twitter, blogs like this one, PluralSight, etc.).
Of course there are variables that could make implementing replication a bit more cumbersome than others. If we were talking SQL 2000, I would say it’s a pain to say the least, but in recent versions it’s come a long, long way.
Another good resource out there is the Stairway to Replication series on SQLServerCentral.com – happy replicating!
Here is my take as maybe an advanced beginner (not a dba, but an everyday SSMS user for 3+ years):
The wizards make it easy to setup initially. I followed the permissions documentation from Microsoft carefully (a lesson learned the hard way with SharePoint), and it worked the first time. Yea! a wizard that worked finally.The complication has come with understanding its workings internally and its capability. You might call this advanced, but here’s the rub: no one is going to setup transactional replication just for fun. You set it up because there is a real business need. So the inclusion of a wizard makes it appear as if it’s one and done… that was a help no doubt, but there is little indication as to what is happening under the covers and will it accomplish my needs, without doing a lot of digging. That digging is what was complicated in my case. (See my earlier posts). So, I think you are both right. If a simple copy of data is what you need… easy peasy. If you need anything more, expect a somewhat steep learning curve, lots of testing and searching. (The internet is definitely a love\hate with me… like being married to a troll. It’s ugly… but poked enough, it will give you what you’re after.)
Incidentally in the end, I went with one-way merge replication, to accomplish exactly what I needed, with very little hassle, other than the addition of GUID columns on my source data. (Why wasn’t this done behind the scenes?)
Interesting Steve – while this isn’t really the place to troubleshoot the issue you had, I’m curious what they were. Normally I can see what’s going on by opening up the replication monitor – it’s come a long, long way in recent versions and there’s some good info to assist with troubleshooting there. I used merge once also – I thought it had a few extra gotchas and in some cases you can’t alter the schema (COTS, for example).
Allen… I was referring to my questions from this thread on 2/24… basically the change of data at the publisher that a transactional replication filter is using… and what the result on subscriber database is. Needed them to be in sync… couldn’t find a way to do this that didn’t feel like a kludge. There may be a better way, but when pragmatism comes to play, I have to decide how much time to spend searching for an ideal solution vs an acceptable solution that is (almost) OOTB.
Agreed… this would not work for vendor databases that can’t be changed.
Ah yes – filters. My publications typically aren’t large enough to filter (~100GB) so I focus more on tuning/optimizing the queries that hit the subscriber rather than filtering. If they do get rather large (which actually may happen soon due to some acquisitions), I’ll cherry pick out some of the bigger tables and put them in their own publication.
Well after thinking about it and reading your replies Kendra, I guess I was a little generous in describing replication’s ease of use. I have spent my fair share of time struggling with the various nuances, so I might be looking at it through different goggles.
It’s funny– it’s so easy to underestimate your own skills in our area!
Kendra, thank you so much for your article. We have received a requirement from our Board of Directors to set up a Bi-Directional replication between two call center sites (one in St. Louis, MO another in Columbia, MO). They want to accomplish the dual availability in case the pipe between the sites goes down. At this time, one site processes approximately 800 records per hour, that including inserts and updates. The volume is expected to grow tremendously in the near future. I have been working on setting up the test, and I followed Hilary’s articles for the identity management and conflict resolution. My fear is of the data being out of sync. Also, in case of disaster recovery, when one of the sites has to be down, what happens with the other side, would we still be able to write to the other site? I never set up anything like this before and my biggest fear is hours added to the DR. Also, after I dug into the processes (I am new to this company), I found that there are a lot of batch processes. Meaning that tables are getting truncated and reloaded from the flat files nightly. At this time I am in a hot seat. I do not have experience in bi-directional replication (or peer-to-peer for that matter), and I am in a position where people think I am a drama queen, being scared to do work. On the other hand, I would be the only one supporting this thing if something goes wrong. Do you know if dual availability is even a good idea for the busy call center that uses large amounts of batch updates. I personally think it is not a good idea, based on my experience. But I would like to hear from the experts. Any advice is very much appreciated!
Hi there,
Your concerns are valid. I would not recommend business critical bi-directional replication to a company with a single DBA in charge of it. The technology is so complex that you have to be a specialist to troubleshoot it– it limits your ability to automate or document steps for others to take to resolve the issue. (Technologies like log shipping are easier in this regard and more suitable to single-DBA shops where your backup might be a sysadmin, etc.)
So for example, what if there’s a high volume of activity that causes problems in replication, and you happen to get food poisoning that night? That’s not good for the business.
So here’s how I’d try to tackle the situation. Explain that you’d like to make sure:
* The new system needs to be fully supported. You need another person who can learn to be a specialist with you to avoid a single point of failure in your staff. Here’s where it might help to also outline technologies that are easier to automate and scale out without necessarily adding more specialists (I personally think log shipping is a good example)
* You need time to load test on a non-production system and also work on building custom monitoring. Replication monitoring isn’t all built in and can be tricky to implement: this means you’re going to need a big chunk of time with a proof of concept (and implement all those difficult batch jobs)
It’ll be a tricky political task as much as a technical one, but those two points are the way I’d approach it.
Kendra,
Thank you so much for your response. I brought up my concerns to the management and at this time we are deciding on the fate of this solution.
Kendra,
Thank you for a great article. Do you have any recommendations as to how to best organize articles in publications? We organize our publications as logical business entity groups. For example: there is 1 publication with all the patient and patient related tables, 1 publication with just lookup tables, 1 publication with all products and product related tables. This grouping scheme results in having uneven distribution: large publication(s) while others can be lightweight.
Hi Hoa,
Great question!
It sounds like you’re doing one thing right– you don’t have the same article in multiple publications. Sometimes people do that when they have multiple subscribers, and it can cause extra work. So keep avoiding that.
Question: Are you having problems where lots of undistributed commands pile up in distribution, or overall replication latency?
Kendra
The environment is set up as to where there is only 1 distribution database , 4 publishers databases, and 4 subscribers databases. We had the issue of bloated transaction log on the distribution recently when we tore down replication of 1 publishing database, did a refresh of that publishing database, rebuilt its publications, and initiated reinits. So we are looking at ways on how to prevent the issue from happening?
Ah, OK. The first thing I would do is make sure you have a pre-production environment with the same publisher and subscriber topology as production. Replication is complicated and there’s a lot of options, and you need a place to test complicated things like re-initializing.
Here’s where I’m guessing problems may have occurred. A lot of this is really hypothetical and not something we can get to the bottom of in blog comments, but it’s just places where I’ve screwed this up personally!
1) Not tearing down replication completely from the publisher
2) Not completely cleaning up the subscriber (things like leaving nonclustered indexes on empty tables and making the initialization really slow)
3) Not setting up replication in the most efficient way possible. In some cases, initializing the subscriber from a backup can be really helpful and avoid things like this
The way to success involves testing out re-initialization in your secondary environment multiple times and optimizing it, to find out what really works best for you. It’s a lot of work, but it’s worth it (because as you know, when it goes bad in production it really hurts).
Kendra,
Thank you for your reply. We are already doing 2). We left the subscriber alone and trust that replication will sync it up with the published.
We will give 3) some good consideration.
I am not sure if we can do 1) because we restore a backup during the refresh. If replication is running, we can’t restore.
Thanks!
@Hoa,
You can only have a single distribution database per instance – the only factor is whether you have it in the same instance or in a dedicated/other instance. I have never scaled it out to another instance, and have not had any issues with that topology.
I’m curious what bloated is to you. I run a pretty active replication environment and my trans log is ~12GB, which is acceptable. It’s in Simple recovery model.
Was the issue that it just seemed clogged up and nothing was getting distributed? A few more details on the errors, symptoms, ways you may have tried to mitigate it prior, etc. would be helpful. Can I ask if any default replication properties were changed? Like, agent configuration, job configuration (-SubscriptionStreams, etc.)?
Personally I try to isolate very large and/or active tables so if I need to reinit the subscribers, I don’t impact other tables. Your approach is close – a few adjustments may be beneficial.
I did notice the transaction log was filling up fast (more than 8 GIG within 24 hours). No, no replication properties were changed.
When replication was rebuilt, we used the generated scripts prior to tearing it down.
Publishing database is 231 GIG but not all tables are replicated.
The issue was a rather long and compounded story.
• First, the subscribing database ran out of space. So the commands had to be retried.
• After the space issue was resolved on the subscribing database, the distribution transaction log ran out of space.
Once the distribution transaction log ran out of space, replication began to report errors such as
The replication agent has not logged a progress message in 10 minutes. This might indicate an unresponsive agent or high system activity.
• The distribution transaction log was shrunk while waiting for new disk to arrive. Had to shrink it 2 times a day because the disk had only 0 MB left.
• Because the distribution transaction log was on a local drive, it took more than 1 day to add more space to it.
• Then replication seemed to take a hiatus. Running sp_who2 showed around 1000-2000+ locks for schema changes.
We had demos to customers and waiting 72 hours for the distribution transactions to be removed was not an option.
So we were in a little bit of a predicament that in retrospect, I think could be avoided had we checked for available disk space on some regular basis.
I think your approach “Personally I try to isolate very large and/or active tables so if I need to reinit the subscribers, I don’t impact other tables. ” is a good one. Going forward, we will likely set our publications that way.
Thanks!
Ouch – that is a hairy spot to be in… not fun at all. If the subscriber ran out of space and replication was essentially “broken”, I can see where the trans log might get bloated. That’s an exceptional situation though – hopefully you have recovered an all is well.
How can i do if i want replicate the schema but i don’t want replicate the content of my table row?
Thanks
Damián Fiorito
Hi Damián,
Lots of folks handle this by periodically doing schema comparison with a tool like RedGate Schema Compare. It has an API so you can handle it programmatically.
If you’re going to do it with built in features, you could write your own tools to handle this with DDL Triggers or Event Notifications.
Hope this helps!
Kendra
Hi Kendra, maybe I was not clear, i’m talking about transactional replication. How can i exclude data of rows of some tabels but include the schema of all database tables? Of course with SQL Server 2008 R2 and not with an external application
Thanks for your advice.
Damián
Hey Damián,
Your question was clear, that’s just not what transactional replication is for. You could potentially hack replication in a way to only do that, but it’d be a lot like mowing your lawn with a chainsaw.
Kendra
Actually this isn’t all that hard to do – just use filters that you know cannot be true and no data will be replicated. For example, if your PK is an auto-incrementing integer, put a filter on that column and say “where [PK_col] = 0.
Now, if you have hundreds or thousands of tables this could be a little cumbersome to set up initially, but it would work.
Interesting, Allen. So you’re saying you’d advocate setting up log reader agents, a distribution database, filtered transactional replication and distribution agents — not to mention adding primary keys to any tables that don’t have them so that they can be added into replication — all just to replicate schema? And those filters have to be evaluated when every row is inserted, and the distribution agents need to read the logs.
I’m not sure I know anyone else who’d recommend that.
He was asking how to do it using replication – so my assumption is that he’s able and willing to set those up. I provided a viable answer to his question. Would I do it? I’m not sure I’ve ever had the need, and as you noted the SQL Compare CLI can do the trick, which is the method I’ve used in the past.
By no means was it a recommendation or endorsement – it was simply a viable solution given the context of his question.
You’ve just described the weird behavior that I see all the time on forums. Person A says: “I’m trying to poison myself and it’s not working.” Person B helpfully responds, “You should use more poison.” Most of the time nobody stops to comment on what the heck is going on and how to stop poisoning yourself.
We try to read the comments on our blog posts regularly because we don’t want this to be like a bad forum. Using the wrong tools to solve a problem is a big way people get into trouble with a complex product like SQL Server. It’s hard to identify the right tool.
Event notifications and DDL triggers are much more lightweight ways to solve the problem of schema replication, and it’s in line with what those tools are created for. And they’re both in Standard Edition! Sure, there are gotchas, but lots fewer than rigging up replication in what I can only describe as a “giant anti-pattern”.
That’s what happens – the SQL Server community is a very large, active, collaborative one and not everyone has the skills that the Ozar/SQLSkills teams have. Sorry if my response was a less than adequate one. I guess I should have just replied with “it depends” and left it at that 😉
His question got me thinking – to the point I tested it in one of my development environments. Obviously I wouldn’t use this method on a busy system, but I wouldn’t rule it out entirely if it achieved the task at hand. While I understand your analogy, I also enjoy solving problems by thinking outside the box.
Damian,
I just came across this article by Robert Davis that may be another viable option for you:
http://www.sqlsoldier.com/wp/sqlserver/schemaonlybackupsandrestores
It involves using Dacpac (data-tier application package) to do schema-only backups and deployments. There are references at the bottom to the automation of this process – perhaps it will work for you.
Hi Kendra,
I need a help.
I have transaction replication set up as follows.
Server 1:Publihser and distributor(push subscription)
Server 2 :Subscriber,Publisher,distributor to Server 3.
Server 3:Subscriber.
We have 12 databases that are replicating from server 1 to server 2 and inturn from server 2 to server 3.
We decided to go ahead with the mirroring as mentioned below.
We are planning to do this one by one.
We are going to have async mirroring along with the replication as below:
Server 1:Publihser,Principal
Server 2:DIstributor,subscriber
Server 3:Mirror
I need to remove replication between Server 2 and Server 3 for a database ABC
Remove replication between server 1 and server 2 for the same database ABC.
I will choose Server 2 as my remote distributor,but since the server 2 is already configured as its won distributor and publisher for server 3 I am not able to configure remote distribution unless I remove the replication and disable the publisher and distributor.
Appreciate your help on this?
Is there anyway I can configure remote distributor without disabling the distribution since other databases are using that as distributor.
Hi there,
Just to make sure I understand: Right now you are using a “republishing subscriber” architecture. Your future architecture will NOT have a republishing subscriber, but you intend to re-use the same hardware. (Just making sure.)
One server can act as a distributor for many publishers. However, a publishing instance can only have a SINGLE distributor. So changing the architecture for individual databases one by one as you’ve described isn’t possible, if I’ve understood your comment properly.
I completely understand why you’d want to get away from re-publishing subscribers (really!), but I would still be a bit wary about performance if you’re re-using older hardware. Replication will need threads coming in to read from all the publishing databases transaction logs. Database mirroring also has overhead as well. I’d step back and assess if you can simplify the architecture further, and if your hardware is up to the task.
Hi Kendra,
I greatly appreciate your response.This is very much helpful.
You got me right, to make server 2 as remote distributor ,we need to remove the replication architecture completely and rebuild again making server 2 as remote distributor to server 1 and server 3 and configure async mirroring with replication.
Thank you for the concern about hardware which is server 2 in this scenario going to be remote distributor I would take a look at it again.
So having a new hardware for the remote distributor is something that is recommended am I right?
I would look at hardware for all of them and figure out where it needs to go most for performance reasons.
New hardware for the publisher is attractive from a change perspective, because you could migrate each database to a new publisher server as you go. But you might actually need more hardware than that depending on your bottlenecks, sql edition, and requirements.
Kendra,
Thank you for suggesting me to look in terms of hardware perspective.
Appreciate your time on this.
You’re welcome!
HI Kendra,
Nice article!
But I’m missing something: how does change tracking compare to transactional replication? As far as I know they don’t serve for the same purpose. If you want to replicate data or need a HA or DR solution, how would change tracking (or CDC) fit into it?
I’m currently analyzing possible alternatives to replace an scenario with Sync Framework where changes are being tracked with triggers and stored in tracking tables.
It’s creating us a lot of headaches, so we want a better solution. Candidates are:
– Replace triggers and tracking tables by Change Tracking and keep using Sync Framework on top on it
– Use Merge Replication (we need bidirectional replication and it does not need to be “real time”. In fact we don’t need to replicate all changes, but the data of the replicated rows after several changes have been made).
Peers will be a factory and hundreds of points of sales with sql server express, and occasionally connected.
Thanks for your time and best regards,
Jaime
Hi Jamie,
I’m not going to be able to do justice to this, but here’s my best take on it:
Change Tracking and Change Data Capture are developer tools that can help you roll your own code to move changing data around. The catch with each of them is that you’re stuck with the framework they provide when it comes to how they record what data has changed, limitations they put on schema changes, impact on internal tables, and cleanup processes. Also, you have to write your own code to move data around! So it’s a lot of work and you may not like how the framework scales. (Or its cost- CDC is enterprise only.) I don’t find that either of these features are very broadly or commonly used, and there’s not a lot of real-world documentation on scaling and tuning them.
Merge replication is an older framework for synchronizing data. It’s complex to implement and scaling it can be quite tricky. You also have to manage conflicts yourself. I think it’s probably pretty fair to say that it’s a legacy feature: I haven’t seen any improvements come out on this in a long time, and if you search on performance tuning merge replication, you’ll find a lot of the articles are ooooolllllddd. That’s not to say that it’s not still valid, just that you’ll have to constantly test a lot on your own.
None of these sounds like an obvious winner, do they? Yep, that’s the situation.
You can evaluate these tools, but I’d also say that you should evaluate potentially writing the code to manage all if it yourself. I’m not saying that’s always the best option, I’m just saying that it should also be a candidate. (You don’t have to use ANY framework and some people just decide to roll their own.)
Which solution is right for you? There’s no way that I can know, it really will take doing a thorough evaluation and a lot of performance testing.
Coincidentally, I do have a blog post that’ll come out in a couple of weeks on Change Tracking. It’s not a comparison between all the features but it covers performance tuning CT and talks about some of the scalability issues that you can run into with the feature.
Hope this helps!
Kendra
Merge replication has built in conflict resolution which is one of its main benefits when compared to other HA solutions.
Shane – not exactly. It offers a framework to build your own conflict resolution:
https://msdn.microsoft.com/en-us/library/ms151257.aspx?f=255&MSPPError=-2147217396
For more details on why you can’t just rely on the built-in portion and have to roll your own, read the “Failed Change Conflicts” section here:
https://technet.microsoft.com/en-us/library/ms151749(v=sql.105).aspx
hi bent,
can you please let me know the capacity planning for sql server replication for big DB.
like: daily 10 GB should replicate , and these DB will be accessing multi user let say more than 100.
and how many cores and CPU’s required.
Venkat – it’s tough to determine cores just from replication volume and user count. Things like query complexity often play a big part. This is the type of work we do in our SQL Critical Care® consulting, and it usually takes us 3-4 days of working directly with a client to get to the right hardware sizing numbers. It’s a little beyond what I can do in a blog post comment, but if you’re interested in working with us on a consulting project, click the SQL Critical Care® at the top of the site and check out how we work.
Hi Kendra,
I need your help on this.
We would like to have multiple publisher and central subscriber model for transactional replication.
Server 1 :Publisher and distributor to DB1
Server2 :Publihser and distributor to DB1
Server 3:subscriber to db1
on server 1 I have the publication created and initialize the subscription with backup.
on server 2 I have publication created and how to initialize the subscription with backup?.(since the subscriber is holding the backup data of server 1)
Is this something that can be achieved without the initial snapshot and to initialize with backup?
Great question.
I strongly recommend having replication subscriptions isolated, each in their own database that is only used for the subscription. That way, if you have to re-initialize, you have the option to initialize from backup. It’s much simpler to manage.
One approach you could test to make this work with your model is to use synonyms in the DB1 database to point to the articles in individual subscriber databases.
Thanks you Kendra for your response.
Correct me if I am wrong:
create 2 publications from 2 different servers,so that subscriber server would have 2 subscription databases.then use union of two databases and create a view to concatenate the data from two subscribers? this would give me the flexibility to initialie the subscription with backup?
Views are an option, but can have problems with metadata. Here’s what I was thinking though:
Server1SubscriberDB
Server2SubscriberDB
DB1 – has synonyms pointing to tables in Server1SubscriberDB and Server2SubscriberDB so it looks like they’re in DB1 (but they aren’t).
http://msdn.microsoft.com/en-us/library/ms187552.aspx
Synonyms can have some problems with linked server queries as it notes on that page.
Hello, is it possible to execute read only stored procedures on availability group secondary instance.
Thank you,
Mishka
Quick sanity check– is this question related to transactional replication? There’s types of transactional replication that execute procedures and I’m not sure if you’re asking about combining that with AlwaysOn AGs, or if your question is just on a different topic.
My biggest issue with transnational replication are when large updates occur or the indexes have to be rebuilt. The latency we have experienced is unacceptable and forces me to stop replication before such activities occur and reinitialize the subscriptions afterwards. It takes 9-12 hours for my snap shots to be reapplied.
Like Brent says below, dialing back the index maintenance can help. For times when you do have to re-initialize, you can potentially re-initialize only impacted tables, or do initialization from a database backup — I’d look into whether those might be right for you. There’s some more info in the Performance Tuning Replication article here: https://www.brentozar.com/archive/2014/07/performance-tuning-sql-server-transactional-replication-checklist/
Would availability groups handle the above latency issues better?
Kelly – no, and in fact, it’ll be worse. If your data gets so far out of sync that you have to reinitialize, the reinitialization process with AlwaysOn Availability Groups involves backups and restores. You’ll want to troubleshoot the root causes – for example, rebuilding indexes on large replicated data probably doesn’t make sense.
I am using transactional replication in a couple Test environments where one SQL Server is the Publication and the other is my Pull subscription. When I update 3 columns for 100,000 records in a table on the Publication side, the transaction takes 10 seconds to complete. I start the Subscription replication agent (job is set for schedule or on demand) and use Profiler to watch my database get updated on the subscriber side. This side of the update takes about an hour as the update is row based ( each row is updated individually). Is this the norm for replication or is there a setting somewhere that I am missing?
update Pub_Table Set column1 = ‘N’, column2 = ‘N’, column3 = ‘N’ where Pub_Table_ID < 100001
Hi Dwayne,
Just to make sure I understand the scenario– you’re updating 3 columns for EVERY row in the 100,000 row table? Is this something you do repeatedly?
The latency you’re seeing isn’t normal, but that’s also not a common scenario for transactional replication, either. It could be many different things slowing it down, but even optimized, transactional replication isn’t really designed for that pattern. You could look at the option to replicate stored procedure commands potentially as an alternative– more on that here: https://www.brentozar.com/archive/2014/07/performance-tuning-sql-server-transactional-replication-checklist/
I have AO group set up for a particular database. I have PowerExchange CDC set up on the primary. Once I fail over to the secondary, I can only find one way to get the log reader agent added on the new primary. The only way I found is to use sp_removedbreplication. This removes all signs of replication. Then, I can re-add publisher db and log reader agent. Is there a cleaner way to handle this?
Brooke – that’s an interesting question – I’d actually ask PowerExchange, since it’s their software.
How would I do it if it were transactional replication?
I would start by going through all the Books Online guides for using AGs with transactional replication, here: http://msdn.microsoft.com/en-us/library/hh710046.aspx
Hi Brooke,
We’re looking at setting up the same scenario where i work, AO group with PowerExchange. CDC. Have you found a solution?
Thanks!
I don’t get the comparison of CDC with TRX replication. CDC is not intended as a way to replicate tables or to replace it. It’s intended to track changes to be used with ETL jobs to allow them push data to external systems that don’t necessarily use replication or where the data needs to be transformed to be pushed to a data warehouse when replication cannot do the required transformations.
In fact CDC uses the exact same technology under the hood. It tracks the TRX log. Yes you do require extra space to track the changes, but you can control how much to track. And yes the very little code you do have to write is a life saver compared to having to write your own custom CDC to for ETL.
“CDC is not intended as a way to replicate tables or to replace it.” So you’re saying you would use *both* for the same data that you needed to publish from one system and consume in another?
We use both for two different things.
We use replication to push like for like data from say production to archive database as replication is intended to be.
We use CDC to track deltas of data on specific tables on the archive database and an ETL job to push the deltas into a NoSQL database like ElsaticSearch.
CDC is good for tracking changes, for audit purposes or notification type system. Or where you need complex ETL to transform the data and push into other systems that may not have replication or when the data cannot be like for like, like calculating running totals in a data warehouse.
Ah, sure. It read to me at first like you were saying you’d use them simultaneously against the same publishing system.
Change Data Capture is marketed as being good for “Incremental Loads” for a data warehouse. If the warehouse is also in SQL Server, traditionally people have often replicated the data to the warehouse and then used the subscriber database for the loading. CDC’s Books online pages make it sound like it’s going to be much lighter on the publishing database, and simpler and easier, and replace replication for that scenario. That’s why I compare them in the article.
But you also have to consider that CDC does not have a transport mechanism. At least I haven’t seen one. So CDC all it does is copy into a local table it doesn’t push to external tables cross network. So you require ETL to do the job.
In the approach you have mentioned, using the subcriber database for loading, would you be able to identify incremental changes?
We are in the process of moving to a replicated practice managment system with data published from Australia & UK into a global hub. I’m wondering if a separate subscriber database can be setup to load a DW on scheduled basis. Would it be possible to modify the subscription to flag records affected in each schedule (for incremental loading), such as populating a custom column on each table, or possibly combining with change tracking? CDC may not be permitted by the vendor on the source PMS.
Thanks
Hi Stuart,
I may not be understanding– so to rephrase, you want to find just recently modified rows in your replication subscriber, and I’m guessing the problem is that not all the replicated tables have a timestamp column on them?
This can be solved either with custom triggers, CDC, or Change Tracking on the subscriber.
It’s easiest to explain with triggers– each subscriber table has a trigger that detects a change and then puts a super narrow related row in a “delta” tracking table, and that contains a key and a datestamp. ETL then finds the rows in those tables based on datestamps.
While this can be done with these methods, with all of them you need to test not only the overhead while everything is running, but also plan for how you’ll handle it when you have to re-initialize the replication. None of them handle that for you, and you might just see every record as “changed” in the subscriber system if you don’t design around it.
Hi Kendra,
The approach you described sounds promising & the issue regarding re-initializing needs consideration. I’m wondering how is this handled by the replication process. If replication is re-initialized are all database records republished & distributed? This would be time consuming for a large database. At some point the replicated database must recognise that the records already exist and prevent them being imported – when does this occur? Could a similar process be adopted in the ETL staging database?
Thanks
Stuart
(Quick answer, teaching offsite.)
“At some point the replicated database must recognise that the records already exist and prevent them being imported.”
Nope, sorry.
Great Article!! We have Transnational Replication enable on one of our Microsoft Dynamic CRM 2011 database and that works great… only problem we have seen so far is If we want to create new field in CRM, we have to delete replication and set it up again once we are done creating new fields in crm. Can you guys provide or guide me how to write script to stop/start replication temporarily?
Kendra,
Is it a good/common practice to use Transactional Replication to replicate the whole DB to the Subscriber if I don’t want to use Log Shipping or Mirroring?
I wouldn’t say that transactional replication is a common replacement for transaction log shipping or database mirroring.
This video should help. Brent does a comparison between the technologies and explains more here: https://www.brentozar.com/archive/2011/12/sql-server-high-availability-disaster-recovery-basics-webcast/
I’ll check it. thanks!
Hello,
Great article.
I was wondering if you could provide some insight into whether or not TR is the best fit solution for a specific scenario we have.
We have a large database that houses several different customers’ data. A specific customer would like access to THEIR data only on a separate server. For the initial phase this is being accomplished through creating a backup then removing the data that is not theirs. As you can imagine this is cumbersome and time consuming. Not to mention the frequency with which this takes is not ideal. Thus, I had though of using TR with row filtering to replication only their data to their service instance. Is this ideal or is there a better way that you can recommend?
Thanks again for the article. Looking forward to any and all recommendations.
-c
Hi Chris,
Is the customer pulling the data down to work with in their own systems? Why is it going into another SQL Server on your end?
Very frequently a customer need is to pull down recent transactions to their own side so they can integrate it into their applications. The solution for that is to create an API to give them incremental chunks of the data and let them pull their requests from that.
Kendra
It’s going to a server outside of our network that they have access to. Ideally the data would be transferred to this external instance as immediately as possible so that they have the most updated data to work with. It doesn’t necessarily need to be truly realtime, but daily would be much better than the monthly or even weekly that we are able to provide via the backup / restore model.
It still sounds architecturally questionable to me — like the customer requirements weren’t really mapped out. Most companies who need to let customers pull down data to do their own reporting do so with APIs, and then the customer does what they need in their own environment. Then you aren’t responsible for the risk of unintentional access to that data (outside of the API code) and you don’t have to maintain a separate SQL Server.
Technically you can do row filtering in transactional replication, but it can absolutely impact performance on the publisher and be a real bear to manage. If the row filtering isn’t set up properly, it can send over data that you don’t intend. And it might require schema changes — tables require a primary key to participate in replication.
There aren’t a lot of features built to solve this problem other than that and custom code, unfortunately. So I don’t have any easy answers for you.
Hi,
great sum up of comparing CT, CDC and TR.
I’m trying to pull off data for data warehousing and want to use a third party application to handle some of the complexity of transactional replication as I don’t have a DBA on my site. Is that going to be a good idea? The tool uses transactional replication to pull of the data but shields me from certain complexity.
Requirement:
I want to have a complete audit trail of what happened as I suffered from jobs deleting data in the operational database (which poses a problem to me) and changes done on the database directly. Today I rely on dates but over time there are always small differences start to pile up and people then find the operational system more “trustworthy” than the data warehouse (and it should be the other way around in my opinion).
Hi Mudi,
The quality of tools can really vary for any software. As part of your evaluation, I recommend stress testing the tool, and also asking whomever makes the tool if they have customer references they can introduce you to. Then I would ask those reference what troubleshooting they’ve needed to do when there were issues and make sure the tool really meets your requirement. (And if there are no references, or the references say there are never any issues, I’d be a very suspicious.)
Kendra
Hi Kendra,
I’m actually finding that Service Broker provides a reasonable alternative to all of these replication technologies. You can script triggers based on a source table’s metadata that enqueue individual DML operations as atomic messages and then define a stored procedure that dequeues and performs the data changes against a destination table (and possibly re-queues the data for distribution to other destinations as required). The only constraint here is that the Inserted and Deleted tables in a trigger don’t contain copies of any LOB data columns, so you need to treat your LOBs separately (perhaps syncing them up during processing a secondary select query) or accept that you can’t ship them to destination tables. Performance isn’t too bad, and you can ensure transactional isolation by using FOR XML queries in the triggers to build and enqueue a single message based on updates to any number of rows. Definitely worth a look if you haven’t played with it.
Cheers
JH
What would be cause for missing custom stored procs on Subscriber ? For example, we being seeing errors saying that “Could not find stored procedure ‘sp_MSdel_tablename’ in our distribution agent log. We didn’t use manual synchronization to pull the data to subscriber initially and even confirmed from app team to check if there are using any process to delete those stored procs. So far we are generating those procs by using system procedure and fixing it but, we need to find the root cause for permanent fix.
Any help!
If you’re sure no user is doing this, you should open a ticket with Microsoft Support for it.
I am extremely said it’s deprecated 🙁
Just upgraded my servers to 2014 and can no longer use it with updatable subscriptions which make it unusable for me.
Merge now? I never liked the looks of Merge 🙁
Just a little wording thing– deprecated usually means it may go away in a future version. Updatabale subscribers are past that and have been removed altogether, so you’re right, you can’t use it.
Peer to Peer is the official replacement, but as you may know it’s Enterprise Edition only.
Well… what I discovered yesterday is that updatable subscriptions still exists – you just can’t create that type of publication through the GUI. If you script it, it will create the publication.
Tried it on some test databases, it actually still works.
I don’t like using unsupported technologies though…
Peer to peer is way out of my price range so my only other option is Merge.
I just never liked the looks of merge because it seems messier and I don’t need most of what it touts as its benefits. And I can’t seem to find comparisons between them – such as does it use more bandwidth? Do the servers have to work harder all the time than transactional? Or is merge better on those fronts?
What I have is six sites where the publisher makes more than half of the the entire system’s data changes all by itself. But all the sites need all the data, I don’t want to partition the data at all.
The sites are all always online, always connected, and low latency for data updates is important. Would Merge be a good fit for that type of scenario?
I’m confused by: https://msdn.microsoft.com/en-us/library/ms151718(v=sql.120).aspx
Updatable Subscriptions for Transactional Replication – SQL 2014:
This feature will be removed in a future version of Microsoft SQL Server. Avoid using this feature in new development work, and plan to modify applications that currently use this feature.
The feature is no longer available.
…
But you can still create it by using T-SQL, surely that means it is still supported?
Nico – “will be removed in a future version” means it’s still in the current version, and thereby still supported.
Hi,
Thanks for the article. We have quite a few Transaction replication setup.
All our existing servers are in SQL 2008 and I am in the process of upgrading to SQL 2014 and as well moving SAN to different SAN storage.
As part of it I have upgrade my distributor.
We got about 7 production database servers and data from all that are replicated using a separate distributor to multiple subscribers. Totally got about 78 publications going to multiple subscribers for various reasons!!! Don’t ask why so many. It is what I inherited as part of new job.
So I started with creating a new VM with Windows 2012 and SQL 2014, made that as the distributor and started changing the distributor of each publisher to the new one and eventually once everything is moved the old distributor can be dropped.
We setup replication from first 2 servers (about 30 publications or assume x publications) to multiple subscribers and things worked fine. It is all Transaction replication with pull subscription. NO delays in replication things working great.
The moment I add a new publication or a new article the new transaction replication goes into “between retries” or sql agent jobs never starts. I tested by deleting one of the existing publication and the new one works fine. So I digged around and read that the number of worker threads on the server level and subsystem level needs to be high enough to run mulitiple SQL agents jobs continously.
So I updated the worker threads on server level setting, restarted server, and that didn’t help. I found the subsystem worker thread information in msdb.dbo.subsystems and updated the worker threads as defined here http://blogs.msdn.com/b/karthick_pk/archive/2011/02/01/sql-agent-maxworkerthreads-and-agent-subsystem.aspx and that doesn’t seem to help.
My distributor is a VM, 2 processors and 8GB ram on it. It is same as the existing SQL 2008 box. One difference I see between existing box and new box is the number of worker threads in the subsystems table. One issue in updating that table is it gets reset whenever SQL server restarts by this proc: dbo.sp_verify_subsystems. So I tried adding a startup proc that updates the worker threads and that doesn’t help.
One thing that seems to work in the new server is, after I setup more replication if I restart the server then it works. But, the moment I add a new replication the new one doesn’t work. So that doesn’t explain the reason.
Any help is appreciated. Should I update the worker threads or other settings for Agent jobs? or Do I have to rely on restarts?
Thanks,
Nachi
Nachi – for personal production support, your best bet is to call Microsoft, or if it’s not urgent, post it on a Q&A site like http://DBA.StackExchange.com.
NO problem. I had opened a ticket with Microsoft and had posted in other blogs in addition to DBA Exchange @ http://dba.stackexchange.com/questions/107440/sql-server-2008-replication-between-retries-or-worker-thread-no-available.
Nachi
Can Change Tracking or Change Data Capture be used on a replicated database (subscriber)?
Yes, but when you re-initialize replication you will see every single row as having been changed unless you code around that.
Hi,
I want an answer of question and that would be highly appreciated
Scenario:
First of all i am an IT guy from Sports Field and using SQL Server 2008R2. I have 2 production servers server 1 and Server 2 both are using SQL Server Transactional Replication [whereas Server 1 is Processing Major Database Operations crawlers and xml parsers data translation and many more stored procedures. it’s a publisher]
[Server 2 mostly contains Websites that are used to show sports data on website and it’s a subscriber]
Actual Data file size is around 3 GB on server 1
Actual Data file size is around 1 GB on Server 2
The problem is that Server 1’s Log file size is increasing with uncertainty let say it grows over the night and jumps to 14 – 15 GB normally if i do not shrink the size with simple recovery model. Usually i am using Full Recovery model because of Replication. I know that it’s pretty much load but that thing was not growing until i tried to make DB’s errors rectified.
Due to log size increase replication between both servers struck.
some of my queries also contain nolock because previous problems until my joining was deadlocks in that DB. Now it’s around 85% less. 🙂
I already took and implement a Transaction log because someone posted that it might be helpful to take Log backup it helps to reuse the free space of log but there is no success indeed suppose a backup log which was using around 2 Gb log Once and had around 1600 MB free so the log backup which i initiated was around 400MB. but still the space 1600 MB was enaged to log.
please help / suggest a solution to automaticaly clear DB’s Transaction log.
Summary.
1: Irregualr / uncertainty in growing of Transaction Log and not releasing space
2: Transactional Replication between both servers stopped due to Transactional log (I think)
One more thing : i got an errors from log reader. Error codes are (355, 298, 165, 382, 18456, 4060) there are only 2 users sa, sqladmin
Hassan – troubleshooting your replication is a little outside of the scope of something we can do in a blog post comment. You might try over at http://dba.stackexchange.com.
Hi there , This is one of the best article i came across wrt replication . I need your valuable suggestion with regards to scenario i m facing :
I have a prod server running SQL 2012 Standard which host our DB which is about 50 GB . We have enabled logshipping on a secondary sever which is in another region . Now we need to implement reporting solution for which we need to have another copy of DB . I can’t implement transactional replication since it works only for tables with primary keys . Merge replication is also out of question.DB mirroring is also out of question.
Could you please tell me the best strategy to implement the reporting on secondary server ?
Thanks in advance!
Rohan – systems design is a little outside of the scope of a blog post comment. Feel free to click Contact at the top of the page and we can work with you on a consulting project to find the right match for you.
HI, I know abt transactional replication and merge replication , if I have need to use push replication (transaction) without updatable subscriber then what is the use of replication ,
can I use triggers in publisher and insert/update/delete the data on the subscriber dabase
My subscriber and publisher are on same server.
Asha – for random questions unrelated to the post, try hitting http://dba.stackexchange.com.
You can still set up transactional replication with updatable subscriptions. You just have to script it since Microsoft took away the interface option to do it. Just know that is being deprecated.
For me the use case for transactional replication is for a situation where transactions are regularly small, i.e. transactions stemming from an OLTP database receiving individual user updates or inserts. If what you’re trying to replicate are large transactions involving many rows like in an ETL setting, replication gets choked. You could use Stored Procedure replication for that perhaps . .
I wonder what you think of SSIS as an alternative to replication in the case of large transactions – as you update one server you can multicast to other servers that need the data.
Can we setup Transactional Replication from a SQL Server 2014 database(publisher) to SQL Server 2014 in-memory OLTP database(subscriber) where the in-memory OLTP do not support cross db transactions /DTC ?
Thanks Kendra, really nice write up of the options!
Urgent::If i run the snapshot agent and cdc is enabled.Will that create any impact on CDC functionality on subscriber.
Sonu – for urgent questions about production, call Microsoft for support.
can any one help on this?
Homework: Homework 5.2
You have just been hired at a new company with an existing MongoDB deployment. They are running a single replica set with two members. When you ask why, they explain that this ensures that the data will be durable in the face of the failure of either server. They also explain that should they use a readPreference of “primaryPreferred”, that the application can read from the one remaining server during server maintenance.
You are concerned about two things, however. First, a server is brought down for maintenance once a month. When this is done, the replica set primary steps down, and the set cannot accept writes. You would like to ensure availability of writes during server maintenance.
Second, you also want to ensure that all writes can be replicated during server maintenance.
Which of the following options will allow you to ensure that a primary is available during server maintenance, and that any writes it receives will replicate during this time?
Check all that apply.
Add another data bearing node. Add two data bearing members plus one arbiter. Add an arbiter. Add two arbiters. Increase the priority of the first server from one to two.
Add another data bearing node.
Add two data bearing members plus one arbiter.
Add an arbiter.
Add two arbiters.
Increase the priority of the first server from one to two.
can anyone please help me for this assignment:
I confused between below options: probably answer will be out of below options:
1 and 5 ??
1 and 3 and 5 ??
only 1 ??
only 5 ??
Only 2 ??
i tried 1, 3 but not working
tried 3,5 but not working
I have only one attempt left so need expert opinion.
We have looked at Transactional Replication as an alternative to CDC (Enterprise Edition is too expensive), but face an issue that I’m not sure can be solved via replication. In addition to the transactional data that needs to be written to the target warehouse database, we need to augment the data with some additional columns such as ‘modifiedon’, ‘modifiedby’, and a few others. Is this something that can be done with Transactional Replication? I know there are some capabilities to define your own stored procs to handle the INSERT, UPDATE, and DELETE’s during the replication, but it doesn’t appear that you can modify the schema when setting up the replication target tables.
We have resorted to writing triggers on the source tables to replicate the data, but this seems to limit where we can place the target DB as linked servers and triggers seem to be a no-no.
Dan – for unrelated questions, head on over to http://dba.stackexchange.com.
Hi
As a real newcomer to Transactional Replication I would appreciate some guidance.
I have a production database on premise and the need to take two tables from here and copy them regularly to a SQL Azure database. This is so that our suppliers can run a very simple label printing program from their premises so they can stick labels on the goods they supply to us.
We raise a Purchase Order in house on our ERP system and send it to our supplier. They produce the goods and print the labels. Stick the labels on the goods and send them to us.
That is it. Nothing fancy in the way of filters or otherwise (This can all be handled by the program).
Is this a fairly easy thing to set up? Is there an idiots guide anywhere that could show me how to go about this?
Thanks
Roy – for unrelated questions, your best bet is http://dba.stackexchange.com.
Hi Kendra,
I’m just doing some research on replication, and having never used it, I know I’m not going to use all the right terms. We are looking into replication at the schema level for databases that are in SQLServer 2012. I’ve done quite a bit of searching, but can’t seem to find any information on this. If I have a database with multiple schemas, is it possible to replicate the data for only a subset of those schemas? I’m not referring to replicating structure, I want to replicate the data at schema level.
Thanks
Mike – yes, ignore the concept of schemas – you can pick the TABLES you want to replicate, and they can be in any schemas you want.
Hi Brent,
Thanks for the quick response!
Mike
In some of the earlier comments, Kendra, you expressed the opinion that replication wasn’t suitable for a lone DBA setup. I just wanted to check whether you think this is still true if the replication setup is fairly simple?
I’m a lone DBA (and I’m a BI dev/database designer with some DBA knowledge, rather than someone with years of DBA experience), and my team need to get a read-only copy onto a separate server for a website to use. Replication looks pretty good for this – I need to be able to only replicate certain objects, and I want different indexes set up on the publisher (our data warehouse) and the subscriber (read only website DB). I may need to do something to filter what’s taken across to a certain date range (if we only want, say, a year’s worth of data on the subscriber). The website must be available 24/7, and the data warehouse is updated every 15 minutes – so we’d need the subscriber to be updated on a similar schedule.
I’m wary of replication after reading various comments suggesting it might not be easy to administrate, but I’m not really clear on whether this only applies to more complicated setups. I’m also not clear what the particular gotchas are that might mean I end up getting called at 3AM if I go down this route; is the issue largely around large numbers of transactions causing replication to stall? If so, that could be a major issue for us given the 24/7 requirement for near-realtime data.
Not looking for vast amounts of support, but if you’re able to clarify whether that is the kind of issue I’d need to be worried about, and whether you think replication would be manageable in this scenario, I’d really appreciate it. My other likely alternative is use something like SSIS to port data across – which I suspect would be more time consuming to set up and maintain (upgrades, changes to schemas, etc.), but at least we have multiple people in house who can help support SSIS packages.
Does Initialize from backup work for Multiple Publications?
I’d have 3-5 publications (separating articles based on their size and relationship), with 1.2TB Data, im planning to use Initialize from backup….
How to do it, considering I have multiple publications?
Hi, I see that this post survives almost 4 years, proving that replication is indeed immortal!
I have been living with transactional replication since my first day as a SQL Server DBA (more than 10 years) and I have come to a conclusion similar to this article’s: Replication will live forever, as long as there is no alternative to some of its unique features.
It has always been a battle between us (the DBAs) and the others (the devs) when it came to which replication to choose. In my previous company I found transactional replication already implemented, acting as a disaster-recovery scenario. Total disaster… After years of fighting we finally moved Mirroring first, and then to AlwaysOn, which meant that the company had to dig deep into its pocket to pay for an Enterprise license…
When I moved to my new company, I though (not wished) I would not have to face replication again. But here it was, alive and kicking, more important (application wise) than ever before. What I mean is that now, we take advantage of the unique features that only transactional replication can offer, that there is (most probably) no alternative to that.
Partial replication!
Not only in terms of a subset of tables being replicated, but most importantly through the use of filters to replicate just a filtered set of data on each replicated table!
Consider the following scenario:
– You have a central Database that services the core application for multiple clients.
– Each client has a dedicated Database, for his eyes only, for reporting and financial purposes.
– Only a subset of tables need to be replicated to the clients’ databases
– Only the personal data of each client have to be replicated to his own dedicated database
– The client’s databases would benefit from a completely different indexing schema, as the queries executed are different than the ones’ executed on the central Database.
Now, ask yourself if there is any other solution, apart from transactional replication with filtering, that can satisfy these simple requirements.
I think transactional replication is the only way, and that is why it is here to stay (I just made a rhyme!)
PS1. Sorry for the lengthy post, but I kept these thoughts inside me for so many years… 🙂
PS2. A second post will follow, asking for help in a very special scenario that I am facing and can’t deal with.
Konstantinos – for questions, head on over to https://dba.stackexchange.com.
Can we execute the procedure in publisher and don’t want it to replicate to subscriber?
King – for questions, head on over to http://dba.stackexchange.com.
Our most senior person left recently, and we of course now have to push out a schema change to a replicated table that is part of transactional replication. I am looking for information on the best order of operations, given what we know, so we don’t mess it up. We’ve exported the publication scripts and backed up the data in case things go wrong, but this will be our FIRST try at it, and I am a bit nervous.
– Transactional replication directly from publisher to subscriber
– We are adding a new column to an existing article in a publication, in a table that is primarily lookup data (only a few hundred rows, not 100Ks of rows)
– We are also adding a new table that needs to be added as a new article
– The existing publication is set up to replicate schema changes.
From everything I have read, it seems the steps may be to:
1. Turn off the distribution agent on the publisher via SSMS.
2. Disable the existing replication jobs (?). There are 3 I see active for this DB.
3. Make the local schema changes on the publisher.
4. Edit the existing article to add the new column.
5. Add the new article into the existing publication.
6. Then I think we have to reinitialize all subscriptions with a new snapshot, right? Because we added a new article?
Tuesday – for that kind of help, your best bet is to hire a consultant. (I don’t work on replication, so I’m out.)
“Replication something you learn by trying it, having problems, fixing it, and then repeating the process.”
And it is never ending.
When it all works, it’s a thing of beauty. When it gets tripped up, it is not.
Hello and thank you for the article!
We have mirroring configured in our site without automatic failover. We have the standard edition of SQL server and so we can not have snapshots on the mirror server to see what is going on really. We have to break the mirror and make the mirror server the principal in order for us to check how well the mirroring works.
We are thinking of setting up replication to the current configuration and I am not sure if this would be a good idea. Has anyone tried this with success?
Thank you!
Sok – for questions, head to a Q&A site like https://dba.stackexchange.com.