
Some query hints sound too good to be true. And, unfortunately, usually they aren’t quite as magical as they might seem.
Frustration with unpredictable execution times
People often learn about parameter sniffing when query execution times stop being predictable. Occasionally you’ll hear about a stored procedure taking much longer than normal, but the next time you look, it might be faster.
One of the causes of this uneven execution is parameter sniffing. Let’s take a look at how it works– and why it can actually be a very good thing!
Let’s start with two simple queries.
We work at a find company named AdventureWorks. We need to occasionally query a list of distinct cities by State/Province. We get our list by running a simple query– here are two commonly run statements:
|
1 2 |
SELECT DISTINCT City FROM Person.Address where StateProvinceID=80; SELECT DISTINCT City FROM Person.Address where StateProvinceID=79; |
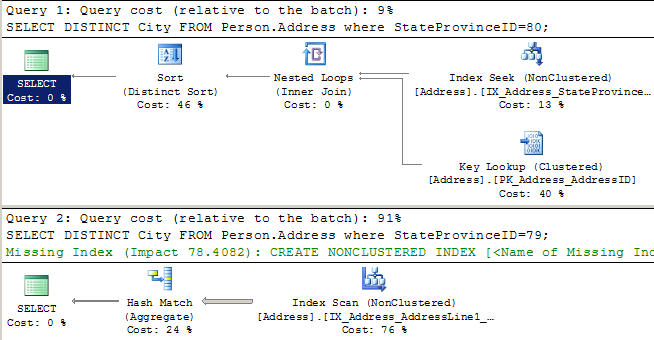
When we look at the execution plans for these, we can see that SQL Server executes them very differently. For each query, it uses statistics to estimate how many rows it’s going to get back. For the first query it estimates four rows, so it does a little nested loop to pull back the data. For the second query, it estimates it’s going to get 2,636 rows back, so it decides it’s worth it to scan a nonclustered index.
What if we’re using a stored procedure?
Let’s say we run this query often, and we create a stored procedure to handle our logic. Our stored procedure looks like this:
|
1 2 3 4 5 6 7 |
CREATE PROCEDURE dbo.GetCities @StateProvinceID int AS SELECT DISTINCT City FROM Person.Address WHERE StateProvinceID=@StateProvinceID; GO |
We execute the stored procedure with the same two values as before, and in the exact same order:
|
1 2 3 |
EXEC dbo.GetCities @StateProvinceID=80; EXEC dbo.GetCities @StateProvinceID=79; GO |
We’re going to get the same execution plans, right?
Well, no. Instead we get:

Hey, what the heck, SQL Server? When we ran this as simple queries using literal values (no parameters), you realized that one of these got a lot more rows than the other, and you created a special execution plan for each one. Now you’ve decided to use one plan as “one size fits all!”
If we right click on the second execution plan and scroll to the bottom, we can see what happened.
This execution plan was compiled for one value, but was run with another value. The parameter value was “sniffed” during the first run!

This means that the execution plan for this query will vary, depending on what values were used the last time it was compiled. Periodically, recompilation may be triggered by all sorts of things, including changes in data distribution, index changes, SQL Server configuration changes or SQL Server restarts. Whatever parameters are used when the query is first called upon recompilation will heavily influence the shape of the plan.
Enter ‘Optimize for Unknown’
Many times, people get frustrated with unpredictable execution times. They hear about a feature that was introduced in SQL Server 2008, and they apply it to solve the problem. The feature is called ‘Optimize for Unknown’. Suddenly, hints are popping up on queries everywhere!
To use the feature, you plug this query hint into your stored procedure like this:
|
1 2 3 4 5 6 7 8 9 10 |
DROP PROCEDURE dbo.GetCities GO CREATE PROCEDURE dbo.GetCities @StateProvinceID int AS SELECT DISTINCT City FROM Person.Address WHERE StateProvinceID=@StateProvinceID OPTION (OPTIMIZE FOR UNKNOWN) GO |
Now, let’s run our queries again:
|
1 2 3 |
EXEC dbo.GetCities @StateProvinceID=80; EXEC dbo.GetCities @StateProvinceID=79; GO |
Did we get great execution plans? Well, maybe not:
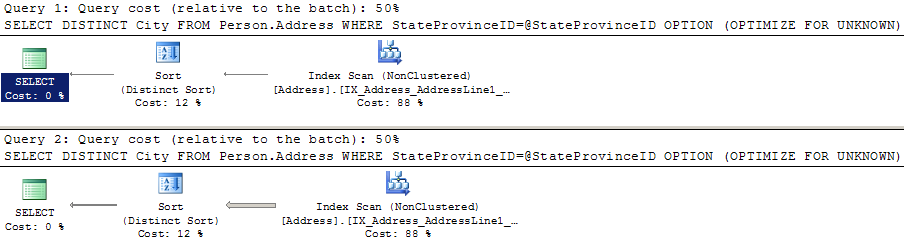
Maybe this is a decent plan for some values, but maybe it isn’t. The query that wanted the “small” nested loop plan did 216 reads in scanning a nonclustered index instead of the 10 it did when it had its ideal plan. If this was a query that ran really frequently, we might not want this plan, either. (Particularly if we had a much larger table).
‘Optimize for Unknown’ has blinders on
The ‘Optimize for Unknown’ feature follows the premise that trying to get a consistent execution time for a given set of parameters and re-using a stable execution plan is better than spending CPU to compile a special, unique flower of an execution plan every time a query runs. That is sometimes the case. But you should also know that it produces a pretty mediocre plan.
Let’s take a closer look at what it did.
For query 1, it estimated it was going to return 265 rows, when it actually returned 4:
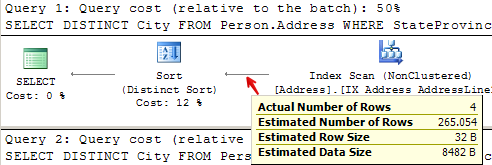
For query 2, it estimated that it was going to return 265 rows, when it actually returned 2,636:
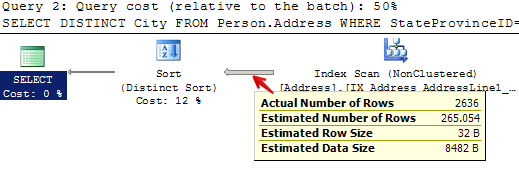
In both cases, it didn’t look at the value for @StateProvinceID that was passed in at all. It pretended it was unknown– just like we told it to. This means that when the plan was created, it didn’t customize it for the values as they were passed in for that execution.
Instead, SQL Server checked out the table and realized that we have an index on the StateProvinceID column. That index has associated statistics. It looked at the statistics to get a measure of how the values are distributed in the index– this is called the “density vector” — read more about it here in a great post by Benjamin Nevarez. It then multipled the “density vector” by the number of rows in the table to create a generic estimate of how many rows might be returned for any sort of “average” value that was used to query the table.
Check it out– we can peek at the statistics header and the density vector:

The density vector for StateProvinceID is in the second result set, first row under “All density”– it’s 0.01351351. Multiply 0.01351351 * 19614 (the number of rows) and you get 265.05398514. And so the plan was created based on an “average” or “mediocre” estimate of 265 rows– which was very different than either of the queries we ran.
Well, just how bad is a mediocre plan?
In this case, this isn’t terrible. I’m just running a few test queries against a small database.
But in this case you could say the same thing about parameter sniffing. The plans I got there weren’t terrible, either! In both cases SQL Server was able to re-use execution plans without creating a freshly compiled plan for each run. That’s good because CPU is expensive: I don’t want to compile all the time.
But in a larger, more complex plan, ‘optimize for unknown’ may make execution times more consistent, but it may also produce a very inefficient plan. The “blind” style of estimate may not match ANY real values well, depending on how my data is distributed. I may end up with a plan which thinks it’s dealing with way more or less data than it’s actually handling. Both of these can present real problems with execution.
So what’s the ideal fix?
I’ve got good news and I’ve got bad news.
The bad news is that there is no single setting that will always produce the perfect exection plan without possibly having extreme adverse impacts on your performance. I can’t tell you “Just do X and it’ll always be fine.”
Instead, you should let parameter sniffing happen most of the time. It’s not a bug, it’s a feature. (Really!) Don’t default to using any query hints– just stay simple and let the optimizer figure it out.
You will have times that you find stored procedures and other parameterized queries (called by sp_executesql or queries using sp_prepare) have uneven execution times. In those cases, you need to figure out how often they’re executing and if there’s a single plan that helps them the most. You may solve the problem with an ‘Optimize for Unknown’ hint, or you may use another hint. No matter what you do, you’ll be making a trade-off between performance gains and possible different performance pains. Cross each bridge when you come to it.
What was the good news?
The bright side is that fixing these issues are fun! How queries are optimized and executed against different sets of data is super interesting to dive into. These little things mean that we’ll always need people to help make applications faster– and a little job security never hurt anyone.
Learn More in Our Execution Plan Training
Our How to Read Execution Plans Training explains how to get an execution plan, how to read the operators, and learn solutions to common query problems.

36 Comments. Leave new
We have several “heavy” stored procedures where parameter sniffing incurs serious performance penalties. Our databases aren’t terabytes, but we are working with hundreds of thousands of rows. And using the wrong execution plan can cause a procedure’s duration to go from seconds to minutes. For those procedures, we use WITH RECOMPILE on the procedure. I’d much rather see a CPU of even a couple seconds compared to the IO hit of scanning the tables for several minutes.
Ever since discovering the impact that “parameter sniffing” has on cached query plans, I’ve seriously discounted their benefit. But I’m far from an expert on SQL Server. Am I missing something?
Hey Jon,
Thanks for the comment!
RECOMPILE is a tricky monster. I’ve done a video on it, but I think I’m going to devote a whole post to it soon. I have two problems with recompile:
1) Like you say, it’s CPU intensive. This is much more critical on OLTP systems that have lots of concurrent queries running– in a system where fewer, larger queries are run (like a data warehouse) query plan quality tends to be more important that compilation CPU. Still, I find that people in the early days of an OLTP system throw in recompile hints that are fine for a while and then it gets bad later on.
2) This keeps SQL Server from putting plans in the cache and aggregating runtime statistics on them over time. This one is actually the one that drives me nuts the most, personally, because it makes performance tuning so much harder over time. If I want to tune indexes, it’s so much more helpful to be able to find out most of the queries using the index from the execution plan cache. If I want to know what my biggest and baddes queries are, same thing. If recompile hints are in use, you’re stuck using a trace methodology (sql trace or extended events) to do sampling, and it’s much harder AND much worse for performance.
For these two reasons (and I’m really passionate about #2), I’m much more in favor of using an OPTIMIZE FOR hint on some procedures when “Bad” parameter sniffing is impacting them. Even if it’s “Optimize for unknown”, if that does the job I tend to be happier for it for the long term health and perf tuning interests of the instance.
As I mentioned, I’m no expert and I’m learning a lot from this blog. I did not know that a query plan had to be cached in order to be included in runtime statistics. I also assumed that WITH RECOMPILE did put the plan in the cache, but recompiled it each time rather than using the previously cached plan. Might not make sense at first, but to me it would make sense if other features like runtime statistics were dependent on the plan cache.
Wouldn’t this mean that any query or procedure that has been removed from the cache due to age would be excluded from runtime statistics? Wouldn’t that also mean that the query compiler/optimizer might not generate optimal plans for queries that are not used frequently, if there isn’t relevant statistical data available?
I just read a post on MSDN about OPTIMIZE FOR UNKNOWN. It sounded to me that the hint actually results in a generic plan, as though no parameter values were provided at all. If that is the case, then wouldn’t there be scenarios where a plan would use a table scan rather than an index seek, since the index based parameter is ignored?
Sounds like Daniel’s solution with dynamic query could provide the benefits of both. Especially for parameters that are a “type” (such as today, 1 week, 1 month) rather than arbitrary values. (That would at least limit the number of plans cached.) We also are still maintaining support for SQL Server 2005 and typically avoid features not available in 2005.
Thanks for the wonderful blog and your valuable time and insight.
So glad you’re learning stuff! I learn stuff from our blogs and webcasts all the time still.
The name of the “RECOMPILE” hint is really misleading I think. It’s actually more like “NOCACHE”.
And yes, you’re correct– plans removed from the cache due to age /memory pressure won’t show up in there either. Even without RECOMPILE hints you can’t be sure that you’re seeing everything from sys.dm_exec_query_stats and related DMVs. But you can see an awful lot for “cheap”, and it’s so much easier/more convenient than sorting through hours of trace data (and without the performance hit).
For optimize for unknown, you’ve got it. Generic plan (in my wording “mediocre”.) It uses the density vector as I explain here– and sometimes it results in a plan that’s really not very good.
I do think the EXEC method / many plan method has its own problems. All of these things can be used sometimes, but I wouldn’t pick any of them to default to, because each of them has its own headache. I still recommend just defaulting to normal execution plan caching and evaluating each situation when you have a problem to solve for what’s best there.
kendra
First, I would like to say that this is a very insightful post. Well done.
Instead of using WITH RECOMPILE on the entire stored procedure, wouldn’t OPTION (RECOMPILE) on the particular query that you’re having trouble with be a good middle-of-the-road solution if the extremes are WITH RECOMPILE on the stored procedure and OPTIMIZE FOR UNKNOWN on the query? Let’s say that you have a stored procedure that has multiple bits of logic in it, but in the middle it’s querying against a table that has 24,000,000 rows in it, and joining on a variable table that you have to limit results from the large table. (There exists the argument that a sub-query would be better served here, but that’s outside the scope of this discussion.) I’ve seen an actual implementation of this, and the query working with the large table just was not performing up to par. Instead of cheating the SQL instance out of caching plans for the stored procedure, the OPTION (RECOMPILE) query hint was added to the query, and that solved the problem in a big way. We’re talking minutes to seconds.
Thoughts?
Raymond
Thanks!
I agree– option recompile on the statement is better than on the procedure. And in cases like what you’re describing where you can document a big benefit, it can be helpful. I would tend to use recompile even there as a last resort, and make sure the notes explain why it’s been done.
(The reason I tend to be so down on recompile is that some folks seem to start using it by habit, even when they may not need it. But I do think there are some cases when there aren’t any better options.)
Thanks for sharing this article!
Just 2 days ago I had to come up with a solution to inconsistent performance caused by parameter sniffing.
In my case, one of the parameters is a @FromDate. This is provided by the application in the form of a fixed set of date ranges: Today, 1 week ago, 1 month ago, 1 year ago, etc.
Obviously the “1 year ago” query should use a different plan to the “Today” plan. The average plan created by the optimize hint for wasn’t optimal for most of the date ranges.
Since my SP uses sp_executesql to run the query, my solution was to inject a — comment with the number of days between the @FromDate and today.
Now I get separate query plans, each optimized for the specified time frame.
Not a solution that can work for everyone (due to the dynamic SQL) but I think the date range is a common parameter that can change the query plan dramatically, and your readers might want to consider this option.
Hey Daniel,
Thanks for the comment. Basically, what this type of solution does is make sp_executesql behave more like just plain EXEC() — you get a separate plan for each statement run. They do get cached, but they get cached individually. If they’re run frequently, this can lead to bloating of the execution plan cache. Also, you get a compile for each run, which can burn up the CPU based on the style of the system.
For dynamic SQL, you do always have the choice to call it with either sp_executesql (which makes it more like a stored procedure), or just plain exec (which makes it more like a plain literal). If getting a compile each time was better for this query, I would tend to just use EXEC and document in a note that I hadn’t used sp_executesql on purpose right above it (so it doesn’t accidentally get “corrected” by someone else).
Also– for anything with dates I always take a look at statistics to see if I’m going to run into the “ascending date problem”– more info from Gail Shaw here: http://sqlinthewild.co.za/index.php/2011/03/22/statistics-row-estimations-and-the-ascending-date-column/
Hope this helps!
Kendra
From Kendra’s previous comment to me, I suspect she’s not going to like this suggestion. I recently learned of the ‘optimize for ad hoc workloads’ configuration option added in SQL 2008. When this option is on, basically a plan will not be cached until the second time the plan is generated. This reduces the size of the plan cache when there are thousands of adhoc single-use queries.
Take a look at these two posts from Kimberly Tripp if you are concerned about proc cache bloat from adhoc queries:
http://www.sqlskills.com/blogs/kimberly/plan-cache-and-optimizing-for-adhoc-workloads/
http://www.sqlskills.com/blogs/kimberly/plan-cache-adhoc-workloads-and-clearing-the-single-use-plan-cache-bloat/
Kendra, am I correct in assuming you do not like this because it limits the ability to use the cached execution plans to locate queries using a specific index? I must admit, that sounds like a neat trick. Any chance you can provide a link for some educational reading?
Optimize for adhoc doesn’t prevent caching entirely– it caches a stub of the plan when it’s first run. That means it will still track all the execution statistics– it’s not nearly as bad as recompile hints.
My overall opinion of “optimize for adhoc” is basically “meh.” In practice I find that it only actually improves performance noticeably in niche cases– you’ve got to have a lot of plan proliferation/low re-use while not having a super high transaction rate. (Examples: thousands of databases on a single instance.)
But I have also found some niche cases in very high transaction systems were having ‘Optimize for Adhoc’ turned on caused a big performance bottleneck. (And it’s very clear it was this setting– we were able to reproduce the issue multiple times when turning it on and testing and measuring wait statistics.)
So in general, optimize for adhoc probably won’t hurt you, unless you’re playing in the > 20K batch requests/sec ballgame. But 99% of the time I don’t know that you’ll get that much of a benefit from it either.
I do a whole section on mining the query cache in my paid indexing training, and I’ve been thinking of doing a short webcast on it. There’s a bunch of different ways people have published to slice and dice the plan cache and look for plans using an index– it can be fairly time intensive, so I recommend starting with Grant Fritchey’s post here which talks about a couple different ways to go about it: http://www.scarydba.com/2012/07/02/querying-data-from-the-plan-cache/
Why do you need dynamic sql to deal with a large date range? Couldn’t you just create multiple ‘if exists’ begin end blocks of code that execute based on the datediff(@FromDate, getdate()) values?
I think the intent of the comment was that variable performance was being seen depending on the value of the parameter (which was a date) which was passed in to the executing string. (IE it was parameter sniffing.)
I haven’t re-read all the comments today and am going off memory, so hopefully I haven’t mauled the intent of the original commenter too much.
The dynamic SQL is there for other reasons anyway (variable types of parameters/ranges being used as criteria).
The date-range-in-comments solution seems to work quite well because there are only 5 different date ranges so the query for each date range is being compiled and reused quite well so far.
We had a scenario where a batch job in the middle of the day did a massive update/add/delete operations and started showing the performance issues. The plan was to rebuild the index every night followed by a recompile of the SP. We preferred to do it in night because of light loads.
can we put the option compile in select statement inside stored procedure in place of “optimize for unknown”. It would be better than whole SP compile every time. It should more suitable where with “optimize for unknown” is provide inconsistent results.Kendra what you suggests ? what we be pro and cons of this approach ? Looking forward to know further
Hey Neeraj–
Recompile has some downsides, also. Check out my response to Jon, above. There are some situations where I’ve had to use RECOMPILE hints, but it’s usually my last resort (and I limit it to individual statements rather than the whole stored procedure).
Hope this helps!
Kendra
Hey Kendra,
I have a situation similar to Daniel.
We have a company tree structure that goes: company->channel->region->district->strore->employee). Many of our procedures take a start date, stop date, the level in the company tree structure your want to report at and the id (or id’s in some cases) of the entities you want at that level. Start and stop date can be any date range. We get some wildly varying plans depending on what parameters the procedure gets cached with.
To make matters worse we host the “same” database for several thousand clients. Not all clients use things in the same fashion so a fix for one client may not work well for another. Some clients well execute a procedure A LOT while others rarely execute it. Some clients have several thousand rows while others have several million. I am always looking for the magic bullet to “solve” this problem.
I have had some success with the following:
OPTION (OPTIMIZE FOR (@StartDate UNKNOWN, @StopDate UNKNOWN, @ForWho UNKNOWN, @ForWhoID UNKNOWN))
It does not always work as a solution and of course results in mediocre plans. I have played around with splitting the procedures out into “ByCompany”, “ByChannel”, etc… and then having a parent procedure that executes the appropriate one. This allows the application to remain unchanged which is good. I have not tried the dynamic SQL route as of yet.
Do you have any other suggestions or thoughts?
Thanks for your blog, i have started working on sql server after a long time and it indeed help me to brush up few things.
I am right now stuck up with a performance issue of a query that implements pagination and deals with approx 200 million records (in base tables with multiple joins). We are using sql server 2008 r2. I will seek your help in this respect in next few days…will post specific scenarios and questions as a separate thread.
Thanks once again!
Hey there,
If you’re working through performance tuning an individual query, blog comments aren’t your best bet. It’s just really not suited for that format– and you can run into trouble giving a good description of the issue and keeping schema anonymous. It’s a hard balance.
If you’re a SQL Sentry Plan Explorer user, you can use a feature to make your plan anonymous, then upload it to their (public) website and ask for help/feedback on the plan in their forums. Plan Explorer is free. You could also anonymize the plan and use it on Stack Overflow / Stack Exchange.
Kendra
Hi Kendra,
We are currently experiencing a problem with parameter sniffing. We have a situation like this (simplified):
SELECT *
FROM Table1 T1
LEFT OUTER JOIN Table2 T2 ON T1.C1 = T2.C1 AND T1.C2 = T2.C2
WHERE Parameter1 = @value1
We have two indexes on Table 2, one on (C1, C2) and other one on, let’s say, (C2, C3).
Running the query from SQL Server Management Studio we have no problem, since it always uses the index on (C1, C2) and it runs fast regardless of the value of @value1.
But when we run this query from code (C#, SqlCommand with SqlParameter) with different values for @value1 we have the problem described in this great blog post.
The first value for @value1 makes the LEFT OUTER JOIN to return 0 records from Table2, and it makes SQL Server TO USE THE OTHER INDEX!!! (C2, C3), which makes no sense at all.
Then we change the value for @value1 with values that have to return several records from Table2, and it becomes crazy slow, because SQL is using the index on (C2, C3).
Why is SQL Server chosing that useless index for this query, even when no record is returned from Table2? After having learnt from plan cache and parameter sniffing, the only question for which we don’t have an answer is this one. We assume it has something to do with statistics.
Anyway, if the JOIN is made on C1 = C1 and C2 = C2, we don’t see the point in using the other index. Maybe SQL determines that it will mean less I/O operations, but the index on C2, C3 is even wider than the correct index.
Thanks for reading and for any clue you could give us on how to understand and to solve this situation.
For the moment we are thinking in using an index hint for this query.
Thanks!
Regards,
Jaime
The issue of “different execution plans in the application and SSMS” is usually due to this: http://www.sommarskog.se/query-plan-mysteries.html#cachekeys
Another guess: When this runs from the application, it sounds like it always runs as part of a stored procedure or prepared statement.
But I’m guessing that when you run this in management studio you may not be running it in the same way. If you’re using a local variable (and not a stored procedure), the local variable essentially will ALWAYS use “optimize for unknown”. If this is the case, you want to test in SSMS in a stored procedure so you can reproduce the behavior and learn more.
Hey Kendra,
How about a suggestion to MS to make a flag, which will trigger OPTION(RECOMPILE) to work like OPTION(RECOMPILE) and not like OPTION(NOCACHE)?
E.g. – still keep cached plans (and collect execution stats on them), even though they wont be used.
Go for it! You can file a bug on connect.microsoft.com on the SQL Server product. If your item can get lots of votes from the community, sometimes it can really happen. (I’d search and see if anyone has filed this first, I haven’t checked myself.)
Excellent article.. I’ve the case of a multipurpose stored with five parameters … I know It’s another situation than parameter sniffing situation, the problem is the ‘first plan’ with. say, just two parameters, and the other call with another one… and all the parameters included in the same query with sintax like select * from t1 a inner join t2 b on a.id=b.id left join t3 c on c.sid=a.id
where (field1 =@param1 or isnull(@param1))
and (field2 =@param2 or isnull(@param2))
and (field3 =@param3 or isnull(@param3))
and (field4 like @param4 or isnull(@param4))
Hi Kendra,
Our DBA provide us lists of the top 20 IO and top 20 CPU consuming queries from the DMV tables.
When we look at the execution plan for one query, that is near the top of both IO and CPU lists,
the plan looks very reasonable.
I suspect a parameter sniffing issue. Do you have any secret ninja tips for proving that hunch?
The query has around 7 parameters and the table has 20 indexes.
Any slow plan is not bad enough to trigger other alerts.
Thanks,
P.S. I would like a feature in SQL server that says “If the actual cost > X * estimated cost”
then make a new plan (default X = 100) and log the bad plan (maybe as a Profiler event)
so we can take steps to not let the plan get picked again.
Brian – sure, if you do a search for parameter sniffing here on the blog, we’ve got a ton of posts and videos about it. Enjoy!
Hello Kendra.
I’m a trainee working as an analyst of databases (well for now im a guy making reports), anyway Im working with T-SQL queries. Currently Im examining parameter sniffing and I encountered a problem including a small testing query. I’ve created dynamic query to be able to use parameters and try option(optimize for @variable)) . It ‘s working for nvarchar parameters without a problem but every time I’m trying to add an int variable to this optimizer Im getting an conversion error. Is there a different way of treatment for int variables?
I have added all 3 variables before variable with query string. @area and @country are string variables and with them optimizer works without problems but when Im adding @instance it’s all crashing… Can You give me some advice how to get over this hurdle?
option(optimize for(@a = ”’ + @area + ”’, @b = ”’ + @country + ”’, @c = ‘+@instance+’ ))’
exec sp_executesql @SQLq, N’@a nvarchar(255), @b nvarchar(255), @c int’, @a=@area, @b=@country, @c=@instance
Thanks!
Hi! For general questions, head on over to http://dba.stackexchange.com. Thanks!
I’ve got some stored procedures that I’ve added OPTION (RECOMPILE) to and it brings the execution time down from 30 minutes to 30 seconds, but on closer inspection (using SET STATISTICS IO, TIME ON just before the query). I can see that the re-compilation time is 17 seconds. If I change the SQL to be dynamic I should be able to get the execution time down to 13 seconds. I should add, the queries are complex (up to 50 tables joined together) and the stored procedure has a lot of parameters.
Dynamic SQL needs to compile every time you run it. Why would it be faster?
Brian, It doesn’t need to recompile dynamic sql. It can cache the plan so long as you use sp_ExecuteSql with parameters.
The best part of this article is this….
What was the good news?
The bright side is that fixing these issues are fun! How queries are optimized and executed against different sets of data is super interesting to dive into. These little things mean that we’ll always need people to help make applications faster– and a little job security never hurt anyone.
Amazing… we used this in an urgent situation, post full stats update on a job that was not finishing overnight… The job ran in 9 minutes. In the past, it had taken between 15 and 34 minutes. Of course this is only a quick fix to a bigger issue.
I’ll go even further Brent, I’ll create a low-quality meme on Paint for that juicy prize:
https://imgur.com/EDrGMSc
(you can tell I’m a really busy DBA)
Whoops, wrong post! (Reaaaally busy)
It’s really a case by case situation. I have run into a specific query where optimize for unknown took care of business like a charm! No need for recompile, no need for adhoc query (no query plan bloat). Thanks for the tip.