What’s New in SQL Server 2022 Release Candidate 0: Undocumented Stuff
24 Comments
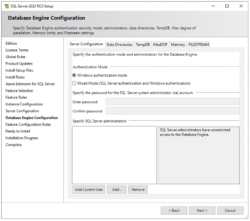
Microsoft has an official list of what’s new in 2022 overall, but here I’m specifically focusing on system objects that might be interesting to script developers like you and I, dear reader. New stored procedure sp_get_table_card_est_and_avg_col_len – I assume the “card” refers to statistics and cardinality, not Hallmark. SQL Server has historically struggled with memory…
Read More