What Happens When Multiple Queries Compile at Once?
5 Comments
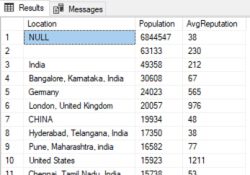
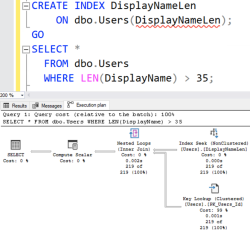
An interesting question came in on PollGab. DBAmusing asked: If a query takes 5-7s to calculate the execution plan (then executes <500ms) if multiple SPIDS all submit that query (different param values) when there’s no plan at start, does each SPID calc the execution plan, one after the other after waiting for the prior SPID…
Read More